



Ячейки, находящиеся на границе поля ячеек, имеют свободные каналы, к которым подключаются контроллеры памяти, периферийных внешних устройств. Прерывания от контроллеров передаются в виде специальных однословных сообщений, в которых указывается, какая ячейка должна обрабатывать это прерывание
Экспериментальный кристалл программируемого процессора изготовлен по 0,15-микронной технологии с 6 слоями медных проводников на фабрике IBM. Кристалл содержит 16 (4х4) ячеек и функционирует на частоте 225 МГц, потребляя 25 Вт.
Разработаны компиляторы языков Си и Фортран, автоматически отображающие операторы программы в массив ячеек и формирующие команды статического интерфейсного процессора этой программы. Для одной из программ набора SPECfp на 16 ячейках получено уменьшение времени выполнения программы от 6 до 11 раз по сравнению с временем ее исполнения на одной ячейке. В другом эксперименте с использованием 32 ячеек соответствующее ускорение составило от 9 до 19 раз.
Однородные вычислительные среды
В разное время было предложено достаточно много проектов однородных вычислительных сред [1-5]. Какое-то схематичное представление о них дает Рисунок, на котором изображена структура ячейки гипотетической однородной среды. Ячейки находятся в узлах прямоугольной решетки и связаны двунаправленными информационными каналами. Кроме этого, ячейки связаны сетью для ввода программы в ячейку, задания режима ее функционирования «настройка/работа», тактирования. В режиме «настройка» каждая ячейка получает программу, возможно, состоящую из одной команды.
|
Рис. Структура ячейки гипотетической однородной среды |
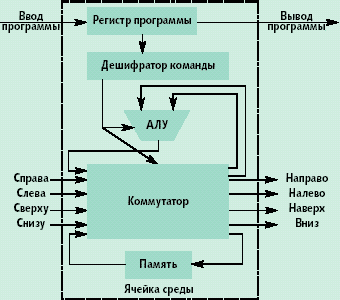
В режиме «работа» ячейка выполняет команды над операндами, поступающими из информационных каналов или из внутренней, как правило, однобитной памяти. То, какие операнды использовать, и какую операцию выполнять над ними определяется дешифратором команды, который управляет АЛУ и коммутатором ячейки. Эта же команда определяет, на какие информационные выходы, и что надо выдавать из ячейки. Ячейка, как правило, выполняет следующие команды: транзит данных через ячейку с ее входов с записью или без записи в память ячейки; нет операции; суммирование с учетом или без учета переноса; логическая операция (суммирование по модулю 2, или, и, не-и); генерирование константы.
Настройка ячеек может быть статической или динамической. В первом случае команды в регистр программы записываются извне. Во втором случае должен предусматриваться способ, как будет выполняться конфигурирование ячеек (т. е. выполняться загрузка регистров программы ячеек). Ячейки могут двояко воспринимать входную информацию. Когда ячейка формирует выходные сигналы сообразно с конфигурацией, она работает в «комбинационном» режиме или режиме обработки данных, как комбинационный логический блок. Может быть введен дополнительный режим работы ячейки, называемый «режимом модификации», позволяющий интерпретировать входные данные как новое содержимое регистра программы. Ячейки входят в этот режим и выходят из него через скоординированный обмен с соседними ячейками. Во время этого скоординированного обмена соседняя ячейка предоставляет новую программу (таблицу истинности) для модифицируемой ячейки. Конфигурирование ячейки является чисто локальной операцией, в которой участвуют только две ячейки — та, которая имеет новое содержимое, и та, в которую это содержимое записывается. Благодаря локальности, операции конфигурирования могут производиться одновременно во множестве различных областей матрицы ячеек.
Любая из ячеек матрицы может работать в любом из данных режимов. Не существует ячеек с заранее предопределенным режимом работы, он определяется данными от соседних ячеек на входах этой ячейки. В типовой сложной схеме матрица содержит ячейки, которые обрабатывают данные, и ячейки, которые участвуют в реконфигурации других ячеек. Функционирование системы включает тесную кооперацию, взаимодействие, обмен между комбинационными узлами и узлами модификации. Можно не только обрабатывать данные на наборе ячеек, но и заставлять ячейки считывать и записывать конфигурацию других ячеек, что позволяет создавать динамические самоконфигурируемые системы, чье поведение во время выполнения может изменяться в зависимости от локальных событий.
Литература
, . Однородные универсальные вычислительные системы высокой производительности. // Новосибирск: Наука, 1966. . Архитектура вычислительной системы с однородной структурой. В кн. однородные вычислительные среды. // Львов, ФМИ АН УССР, 1981. . Матрица одноразрядных процессоров. Львов, НТЦ "Интеграл", 1991. L. Durbeck, N. Macias. The Cell Matrix: An Architecture for Nanocomputing, www. . С. Кун. Матричные процессоры на СБИС. // М.: Мир, 1991.
Однокристальный ассоциативный процессор САМ2000
На концептуальном уровне многие сегодняшние проблемы повышения эффективности параллельной обработки данных связаны с вопросами представления данных в адресных запоминающих устройствах и указанием способа их параллельной обработки. Данные должны быть представлены в виде ограниченного количества форматов (например, массивы, списки, записи). Также должна быть явно создана структура связей между элементами данных посредством указателей на адреса памяти элементов. В свою очередь, при обработке этих данных порождается совокупность операций, обеспечивающих доступ к данным по указателям. При подготовке и исполнении параллельных программ анализ этой совокупности операций составляет, в сущности, проблему, так называемого, распараллеливания по данным. Кроме того, указанные операции по доступу к данным часто образуют — в силу своей природы — неподдающиеся распараллеливанию блоки программного кода.
Сформировавшаяся триада — алгоритмы прикладных задач, общесистемное программное обеспечение и аппаратные средства — существенно ориентирована именно на традиционную адресную обработку данных. Помимо обусловленной этим подходом громоздкости операционных систем и систем программирования, адресный доступ к памяти служит препятствием к созданию вычислительных средств с архитектурой, ориентированной на более эффективное использование параллелизма обработки данных.
Преодоление ограничений, обусловленных адресным доступом к памяти, возможно за счет использования ассоциативного способа обработки данных, позволяющего выбирать все данные, удовлетворяющие некоторому задаваемому критерию поиска, и производить над всеми выбранными данными требуемые преобразования [1, 2]. Определенная подобным образом ассоциативная обработка включает возможность массовой параллельной выборки данных и массовой их обработки. Критерием поиска данных может быть совпадение с любым элементом данных, достаточным для выделения искомых данных из всех данных. Поиск данных может происходить по фрагменту, имеющему большую или меньшую корреляцию с заданным элементом данных.
Исследованы и в разной степени используются несколько подходов, различающихся полнотой реализации модели ассоциативной обработки. Если реализуется только ассоциативная выборка данных с последующим поочередным использованием найденных данных, то говорят об ассоциативной памяти или памяти, адресуемой по содержимому. При достаточно полной реализации всех свойств ассоциативной обработки, используется термин «ассоциативный процессор». Примером такого процессора может служить STARAN [2]. Кроме того, модель ассоциативной обработки может достаточно эффективно быть реализована на специализированных параллельных системах из большого числа процессоров, каждый из которых имеет собственную небольшую локальную память. Подобные вычислительные структуры обычно называют памятью с обработкой, многофункциональной памятью, интеллектуальной памятью и рядом других терминов.
|
Рис. Структура САМ 2000 — бинарное дерево |
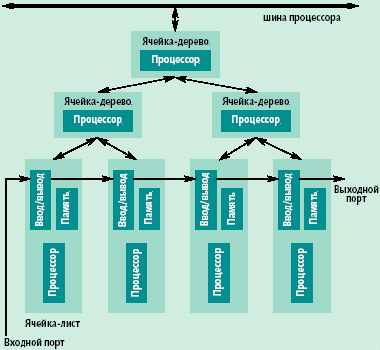
Однако следует проанализировать возможности использования памяти с обработкой. Представляется, что переход от одной крайности (только хранение данных в традиционной памяти) к другой (вся обработка данных только в памяти) заведомо не продуктивен. Компромиссным решением может быть реализация в интеллектуальной памяти простой массово параллельной обработки данных и вычисление агрегированных значений типа сумма компонент вектора, определение минимальной или максимальной компоненты вектора и тому подобные. Сложная обработка данных производится в процессоре, к которому подключается рассматриваемая интеллектуальная память. Этот подход положен, например, в основу проекта контекстно-адресуемой (ассоциативной) памяти САМ 2000 [3].
САМ 2000 объединяет возможности ассоциативного процессора, ассоциативной памяти, динамической памяти в одном кристалле. Этот кристалл может выполнять просто функции динамической памяти, а также производить простую массово параллельную обработку содержимого, хранящегося в динамической памяти.
В основе САМ 2000 лежит концепция увеличения качества данных. Множество простых процессоров в кристалле памяти выполняют массово-параллельную обработку содержимого памяти прежде, чем отправить результаты этой обработки в процессор. Например, нахождение среднего k чисел в традиционном вычислительном модуле с кэш-памятью требует пересылки данных с последующим выполнением только одной операции с каждым данным. При этом создается большая нагрузка на интерфейс «процессор-память», определяющий фактически производительность обработки. В САМ 2000 среднее может быть вычислено так, что сумма чисел может быть получена в памяти и передана в процессор, где выполняется вычисление среднего.
Каждый кристалл САМ 2000 выполняет функцию микросхемы интеллектуальной памяти и имеет 4 шины: двунаправленную шину данных, подсоединяемую к основному процессору или процессорам, однонаправленную входную шину команд, по которой поступает выполняемая всеми кристаллами команда; однонаправленную входную шину ввода; однонаправленную выходную шину вывода.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
