



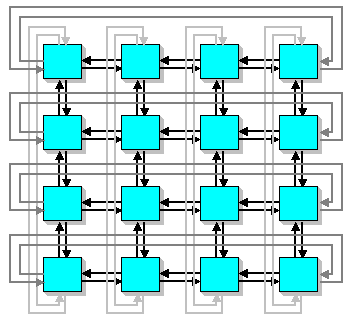
Сеть с топологией 2D решетка(тор)
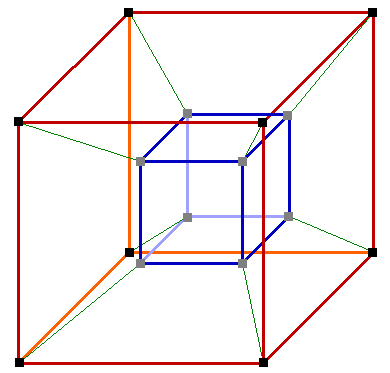
Сеть с топологией 2D гиперкуб (тор)
.
Термин "мультипроцессор" покрывает большинство машин типа MIMD и (подобно тому, как термин "матричный процессор" применяется к машинам типа SIMD) часто используется в качестве синонима для машин типа MIMD. В мультипроцессорной системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно независимо от других процессорных элементов. Процессорные элементы, конечно, должны как-то связываться друг с другом, что делает необходимым более подробную классификацию машин типа MIMD. В мультипроцессорах с общей памятью (сильносвязанных мультипроцессорах) имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ связываются с помощью общей шины или сети обмена. В противоположность этому варианту в слабосвязанных многопроцессорных системах (машинах с локальной памятью) вся память делится между процессорными элементами и каждый блок памяти доступен только связанному с ним процессору. Сеть обмена связывает процессорные элементы друг с другом.
Базовой моделью вычислений на MIMD-мультипроцессоре является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным. Существует большое количество вариантов этой модели. На одном конце спектра - модель распределенных вычислений, в которой программа делится на довольно большое число параллельных задач, состоящих из множества подпрограмм. На другом конце спектра - модель потоковых вычислений, в которых каждая операция в программе может рассматриваться как отдельный процесс. Такая операция ждет своих входных данных (операндов), которые должны быть переданы ей другими процессами. По их получении операция выполняется, и полученное значение передается тем процессам, которые в нем нуждаются. В потоковых моделях вычислений с большим и средним уровнем гранулярности, процессы содержат большое число операций и выполняются в потоковой манере.
4) Многопроцессорные машины с SIMD-процессорами.
Многие современные супер-ЭВМ представляют собой многопроцессорные системы, в которых в качестве процессоров используются векторные процессоры или процессоры типа SIMD. Такие машины относятся к машинам класса MSIMD.
Языки программирования и соответствующие компиляторы для машин типа MSIMD обычно обеспечивают языковые конструкции, которые позволяют программисту описывать "крупнозернистый" параллелизм. В пределах каждой задачи компилятор автоматически векторизует подходящие циклы. Машины типа MSIMD, как можно себе представить, дают возможность использовать лучший из этих двух принципов декомпозиции: векторные операции ("мелкозернистый" параллелизм) для тех частей программы, которые подходят для этого, и гибкие возможности MIMD-архитектуры для других частей программы.
Многопроцессорные системы за годы развития вычислительной техники претерпели ряд этапов своего развития. Исторически первой стала осваиваться технология SIMD. Однако в настоящее время наметился устойчивый интерес к архитектурам MIMD. Этот интерес главным образом определяется двумя факторами:
1.Архитектура MIMD дает большую гибкость: при наличии адекватной поддержки со стороны аппаратных средств и программного обеспечения MIMD может работать как однопользовательская система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, как многопрограммная машина, выполняющая множество задач параллельно, и как некоторая комбинация этих возможностей.
2.Архитектура MIMD может использовать все преимущества современной микропроцессорной технологии на основе строгого учета соотношения стоимость/производительность. В действительности практически все современные многопроцессорные системы строятся на тех же микропроцессорах, которые можно найти в персональных компьютерах, рабочих станциях и небольших однопроцессорных серверах.
Одной из отличительных особенностей многопроцессорной вычислительной системы является сеть обмена, с помощью которой процессоры соединяются друг с другом или с памятью. Модель обмена настолько важна для многопроцессорной системы, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, соответствующим решаемым задачам. Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти. В многопроцессорной системе с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом "почтового ящика".
С ростом числа процессоров просто невозможно обойти необходимость реализации модели распределенной памяти с высокоскоростной сетью для связи процессоров. С быстрым ростом производительности процессоров и связанным с этим ужесточением требования увеличения полосы пропускания памяти, масштаб систем (т. е. число процессоров в системе), для которых требуется организация распределенной памяти, уменьшается, также как и уменьшается число процессоров, которые удается поддерживать на одной разделяемой шине и общей памяти.
Распределение памяти между отдельными узлами системы имеет два главных преимущества. Во-первых, это эффективный с точки зрения стоимости способ увеличения полосы пропускания памяти, поскольку большинство обращений могут выполняться параллельно к локальной памяти в каждом узле. Во-вторых, это уменьшает задержку обращения (время доступа) к локальной памяти. Эти два преимущества еще больше сокращают количество процессоров, для которых архитектура с распределенной памятью имеет смысл.
Обычно устройства ввода/вывода, также как и память, распределяются по узлам и в действительности узлы могут состоять из небольшого числа (2-8) процессоров, соединенных между собой другим способом. Хотя такая кластеризация нескольких процессоров с памятью и сетевой интерфейс могут быть достаточно полезными с точки зрения эффективности в стоимостном выражении, это не очень существенно для понимания того, как такая машина работает, поэтому мы пока остановимся на системах с одним процессором на узел. Основная разница в архитектуре, которую следует выделить в машинах с распределенной памятью заключается в том, как осуществляется связь и какова логическая модель памяти.
Литература
[1] ComputerWorld Россия, № 9, 1995.
[2] К. Вильсон, в сб. "Высокоскоростные вычисления". М. Радио и Связь, 1988, сс.12-48.
[3]. , "Параллельные вычислительные системы". М.. Наука, 1980, 519 с.
[4] Р. Хокни, К. Джессхоуп, "Параллельные ЭВМ. М.. Радио и Связь, 1986, 390 с.
[5] Flynn И.,7., IEEE put., 1972, о. С-21, N9, рр. 948-960.
[6] Russel К. М., Commun. АСМ, 1978, v. 21, № 1, рр. 63-72.
[7] Т. Мотоока, С. Томита, Х. Танака, Т. Сайто, Т. Уэхара, "Компьютеры на СБИС", m. l. М. Мир, 1988, 388 с.
[8] М. Кузьминский, Процессор РА-8000. Открытые системы, № 5, 1995.
[9] Открытые системы сегодня, № 11, 1995.
[10] ComputerWorld Россия, №№ 4, 6, 1995.
[11] ComputerWorld Россия, № 8, 1995.
[12] Открытые системы сегодня, № 9, 1995.
[13] ComputerWorld Россия, № 2, 1995.
[14] ComputerWorld Россия, № 12, 1995.
[15] В. Шнитман, Системы Exemplar SPP1200. Открытые системы, № 6, 1995.
[16] М. Борисов, UNIX-кластеры. Открытые системы, № 2, 1995, c.22-28.
[17] В. Шмидт, Системы IBM SP2. Открытые системы, № 6, 1995.
[18] Н. Дубова, Суперкомпьютеры nCube. Открытые системы, № 2, 1995, сс.42-47.
[19] Д. Французов, Тест оценки производительности суперкомпьютеров. Открытые системы, № 6, 1995.
[20] Д. Волков, Как оценить рабочую станцию. Открытые системы, № 2, 1994, c.44-48.
[21] А. Волков, Тесты ТРС. СУБД, № 2, 1995, сс. 70-78.
Лекция 24. Классификация мультипроцессорных систем по способу организации основной памяти.
1. АРХИТЕКТУРЫ МНОГОПРОЦЕССОРНЫХ СИСТЕМ
Основной характеристикой при классификации многопроцессорных вычислительных систем является способ организации оперативной памяти. В случае наличия общей памяти с равноправным доступом к ней от всех процессоров говорят о симметричных мультипроцессорных системах (SMP), а при использовании распределенной памяти, когда каждый процессор снабжается собственной локальной памятью, и прямой доступ к памяти других процессоров невозможен, речь идет о системах с массовым параллелизмом (MPP). Нечто среднее между SMP и MPP представляют собой NUMA-архитектуры (Non Uniform Memory Access), в которых память физически распределена, но логически общедоступна. При этом время доступа к различным блокам памяти становится неодинаковым. В одной из первых систем этого типа Cray T3D время доступа к памяти другого процессора было в 6 раз больше, чем к своей собственной.
В настоящее время развитие высокопроизводительных вычислительных систем идет по четырем основным направлениям: векторно-конвейерные суперкомпьютеры, SMP системы, MPP системы и кластерные системы. Рассмотрим основные особенности перечисленных архитектур.
1.1. Векторно-конвейерные суперкомпьютеры
Характерной особенностью векторно-конвейерных компьютеров является, во-первых, конвейерная организация обработки потока команд, а, во-вторых, набор векторных операций в системе команд, которые оперируют целыми массивами данных [2]. Исторически это были первые компьютеры, к которым в полной мере было применимо понятие суперкомпьютер. Однако в настоящее время их доля в суперкомпьютерном парке неуклонно снижается ввиду их чрезвычайной дороговизны и невысокой степени масштабируемости. Как правило, несколько таких процессоров (2-16) работают в режиме с общей памятью (SMP), образуя вычислительный узел, а несколько таких узлов объединяются с помощью коммутатора аналогично MPP-системам. Типичными представителями такой архитектуры являются компьютеры CRAY J90/T90, CRAY SV1, NEC SX-4/SX-5.
1.2. Симметричные мультипроцессорные системы SMP
Современные системы SMP архитектуры состоят, как правило, из нескольких однородных микропроцессоров и массива общей памяти (Рис. 1). Все процессоры имеют равноправный доступ к любой точке общей памяти.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
