



Фреймовый подход к моделированию знаний реализован в языке ЛИСП.
Достоинства модели: естественность иерархического представления знаний для человека; легкость расширения и модификации знаний, комбинация декларативных и процедурных знаний, возможность преобразования знаний на естественный язык.
Недостатки модели: нет общепринятого формального аппарата, логический вывод целиком опирается на правила наследования, необходимость программирования процедур.
Таким образом, фреймовая модель удобна для представления знаний в тех областях, где четко выделена и систематизирована понятийная структура.
Рассмотренные модели представления знаний имеют одинаковые возможности по структуризации знаний. Наиболее пригодны для реализации на ЭВМ продукционная и фреймовая модель, но последняя более трудоемка в программировании, а первая медленнее работает на больших задачах. Наиболее близка к естественному языку семантическая сеть.
Лабораторная работа № 5. Нереляционные модели данных
В настоящее время в некоторых информационных системах применяются модели данных, которые исторически появились раньше реляционных - инвертированные списки, иерархические и сетевые модели. Их наиболее общие характеристики:
1. Понятие модели данных появилось только вместе с реляционным подходом, поэтому абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у разных систем.
2. Для этих систем характерен навигационный принцип доступа к БД (в любой момент времени выделяется "текущая запись", с которой начинается выполнение операций с БД).
3. В качестве интерфейса применялись обычные языки программирования, расширенные функциями работы с БД, поэтому задача оптимизации доступа к БД возлагалась на пользователя.
4. Эти системы использовались в течение многих лет, накопили громадные базы данных и некоторые из них используются до сих пор, поэтому актуальна проблема совместного использования ранних и современных систем.
5. Использование более сложных внутризаписных структур данных.
Рассмотрим последнюю особенность более подробно. Записью обычно называют элемент структуры данных. Различают записи с линейной структурой и иерархической. В первом случае запись состоит из атомарных элементов (полей), которые следуют один за другим. Такие записи характерны для реляционных баз данных.
Во втором случае в состав записи могут входить составные единицы информации (СЕИ): векторы (массивы); повторяющиеся группы (когда в записи присутствует несколько экземпляров СЕИ, состоящих из разнотипных элементов), неповторяющиеся составные единицы информации. Например: в состав записи СОТРУДНИК могут входить простые элементы (ТабНомер, Фамилия), вектор ИнострЯзыки, повторяющаяся группа ПослужнойСписок (ДатаНазначения, ДатаУвольнения, МестоРаботы, Должность) и неповторяющаяся группа Адрес (Город, улица, дом, квартира, индекс). Сложная структура записей характерна для нереляционных БД.
Системы, основанные на инвертированных списках
Типичными представителями таких систем являются Datacom/DB компании Applied Data Research, Inc. и Adabas компании Software AG. Они применяются, как правило, на больших ЭВМ фирмы IBM. База данных на инвертированных списках похожа на реляционную БД, то есть также состоит из таблиц отношений, однако есть важные отличия:
- допускается сложная структура атрибутов (не атомарность);
- строки таблиц (записи) упорядочены в некоторой последовательности, каждой строке присваивается уникальный номер;
- пользователь может управлять логическим порядком строк в каждой таблице с помощью специального инструмента - индексов.
Некоторые атрибуты могут быть объявлены поисковыми, для каждого из них создается индекс, который содержит упорядоченные значения ключей и указатели на соответствующие записи основной таблицы (инвертированный список). Если таблицу требуется упорядочить по нескольким ключам, то создается столько же индексов. Возможна установка связи между таблицами по тем атрибутам, которые были объявлены поисковыми.
Поддерживаются два класса операций над данными:
- поиск адреса записи по некоторому пути доступа и некоторому условию,
- обновление, удаление или выборка записи с заданным адресом.
Достоинство рассмотренного метода построения базы данных:
- более быстрый поиск по сравнению с РБД (особенно поиск уникальной записи по нескольким условиям),
- возможность хранения элементов данных со сложной структурой.
Недостаток модели - отсутствие строгого математического аппарата, отсутствие средств для описания ограничений целостности БД, отсюда - большая трудоемкость программирования запросов к БД.
ПРИМЕР.
Основная таблица:
Адреса | Имена столбцов (поля) | ||
Номер зачетки | Фамилия | Группа | |
400 | 5 | Усачев | 95е1 |
Индексы и инвертированные списки:
Ключевой aтрибут | Индекс | Адреса записей |
Фамилия | Арбуз | 700 |
Группа | 95е1 | 400, 500, 799 |
Например, для поиска записей по условию Фамилия ="Пикулин" и Группа = "98е1" достаточно найти пересечение списков с соответствующими индексами: адрес искомой записи = (500, 900) ^ (800, 900) = 900.
Иерархическая модель
Типичным, наиболее известным и распространенным представителем является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г., до сих пор поддерживается много баз данных, что создает существенные проблемы с переходом как на новую технологию БД, так и на новую технику.
Структура данных
Иерархическая БД состоит из упорядоченного набора структур записей, каждая структура имеет вид дерева. Деревом называется связный неориентированный граф, не содержащий циклов. Вершины дерева называются узлами. Один из узлов, который находится на самом верху иерархии, называют корнем. Остальные узлы называются порожденными (потомками) и связаны так, что каждый узел имеет исходный, находящийся на более высоком уровне иерархии (предок). Узлы, не имеющие порожденных, называют листьями. Все экземпляры узла - потомка, имеющие общего предка, называют близнецами.
Рассмотрим пример иерархической БД
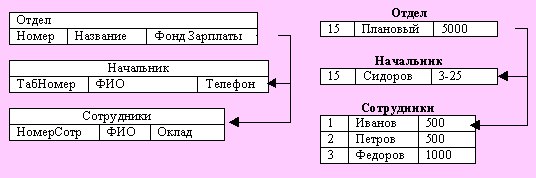
Рис. Схема иерархической БД и один экземпляр дерева
Здесь Отдел является предком для узлов Начальник и Сотрудники, а Начальник и Сотрудники - потомки узла Отдел.
Каждому узлу соответствует своя структура записей. Например, в узле Отдел запись содержит поля Номер, Название, Фонд з\п.
Между узлами поддерживаются связи.
Справа показан один экземпляр дерева, содержащий конкретные данные для планового отдела. Для другого отдела строится другой экземпляр дерева с такой же структурой.
Для отображения другой информации о предприятии могут быть построены другие типы деревьев.
Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:
- Найти указанное дерево БД (например, плановый отдел);
- Перейти от одного дерева к другому;
- Перейти от одного узла к другому внутри дерева (например, от отдела - к первому сотруднику);
- Перейти от одного узла к другому в порядке обхода иерархии;
- Вставить новую запись (экземпляр узла) в указанную позицию;
- Удалить текущую запись.
Ограничения целостности: никакой потомок не может существовать без своего родителя. Однако аналогичное условие целостности по ссылкам между узлами, не входящими в одно дерево, не поддерживается.
Достоинства иерархической модели:
- простота и естественность представления экономических данных;
- минимальный расход памяти по сравнению с другими моделями.
Недостатки иерархической модели:
- сложность отображения связей М : N без увеличения избыточности
- сложность включения информации о новых объектах и удаления устаревших данных;
- доступ к данным возможен только через корень дерева, следовательно большое время поиска данных для некоторых запросов.
Рассмотрим перечисленные недостатки на примере.
Построим иерархическую БД о преподавателях, студентах и сдаче экзаменов по разным дисциплинам
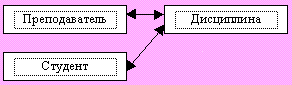
Рис. Исходная ER-модель
Можно выделить два варианта в соответствии с тем, какой объект принять за корень дерева:
1. Корень дерева - преподаватель.
о Преподаватель ( Код_пр, ФИО_пр, Уч. звание, кафедра)
ß
о Студент+дисциплина ( N_зач, ФИО_ст, группа, дисциплина, дата_экз, оценка)
Полученная БД удобна для представления данных о преподавателях, но неудобна для представления сведений об успеваемости студентов: если преподаватель Х уволился, то необходимо информацию о нем удалить из БД, при этом удаляются и порожденные записи, следовательно теряется информация об успеваемости студентов.
2. Корень дерева - студент
о Студент ( N_зач, ФИО_ст, группа)
ß
о Дисциплина+преподаватель ( Код_пр, ФИО_пр, звание, кафедра, дисциплина, дата_экз, оценка)
Построенная модель позволяет быстро находить информацию о студентах (например, о сдаче экзаменов по разным дисциплинам), но не удобна для того, чтобы узнать информацию о преподавателях. Например, если преподаватель не принимает экзаменов или ушел в длительный отпуск, то информацию о нем нельзя включить в БД. Кроме того, информация о преподавателе Х дублируется столько раз, сколько у него студентов.
Переход от инфологической модели к иерархической БД
Методика перехода к иерархической БД может быть различной. Один из способов описан в учебнике [7].
Рассмотрим более простую методику, идея которой состоит в том, чтобы построить дерево на графе инфологической модели. Таких деревьев может быть несколько. При этом корень дерева - узел, в который не входят дуги (если такого узла нет, то следует ввести его). Часть связей нужно удалить и заменить их соответствующими атрибутами объектов.
Список атрибутов каждого узла определяется так:
- перечисляются все атрибуты понятия кроме тех, которые принадлежат вышестоящим узлам,
- добавляются атрибуты для моделирования связей, явно не отраженных в структуре дерева.
Дублирование атрибутов в узлах позволяет отобразить реальные связи, но увеличивает объем БД.
Пример. Рассмотрим ER-модель факультета (на рис. 7.3 показаны связи типа "является частью" и процесс сдачи экзаменов и чтения лекций).
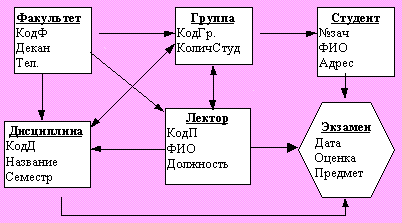
Рис. ER-модель факультета
Можно построить несколько вариантов иерархической БД, например.
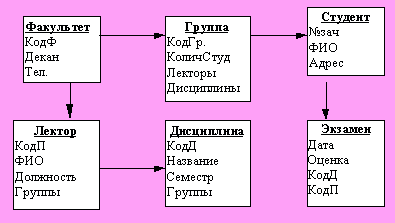
Рис. Вариант иерархической модели
В качестве корня выбран узел “Факультет”, так как все дуги выходят из него. Обратите внимание, как изменился состав атрибутов в узлах дерева: добавлены внешние ключи вместо разорванных связей типа 1:М (например - в узле Экзамен). Вместо удаленных связей М : М добавлены векторные атрибуты "Лекторы" и "Дисциплины" в узле Группа; атрибут "Группы" в узле Лектор, атрибут "Группы" в узле Дисциплина. Налицо дублирование информации, которое можно уменьшить, но тогда усложнится обработка запросов к БД.
Если конкретная СУБД не допускает сложных внутризаписных структур, то придется вводить дополнительные узлы дерева либо пренебречь некоторыми связями в концептуальной модели, то есть потерять часть информации о предметной области.
Сетевая модель данных
Отличие сетевой модели от иерархической заключается в том, что в сетевой структуре любой элемент данных может быть связан с любым другим, то есть иерархическая модель является разновидностью сетевой.
Различают простую и сложную сетевую структуру. В простой сетевой структуре между исходным и порожденными узлами реализуется связь 1:М. Сложной сетевой структурой называют такую схему, в которой присутствует хотя бы одна связь N : M.
В настоящее время большинство СУБД поддерживают только простые сетевые структуры. Такие системы называют СУБД с равноправными (однотипными) файлами. Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем. Архитектура системы основана на предложениях Комитета по языкам программирования Conference on Data Systems Languages (CODASYL). В дальнейшем мы будем пользоваться терминологией, принятой в КОДАСИЛ.
Основная конструкция сетевой модели данных КОДАСИЛ - набор.
Рис. Графическое представление набора | Набор - это поименованное двухуровневое дерево, которое реализует связь между записями двух типов: владельцем набора и членом набора. Разрешаются только связи 1 : М или М : 1 , но связи M : N в явном виде не поддерживаются. |
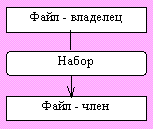
Для каждого набора, устанавливающего связь между предком P и потомком C должны выполняться два условия:
1. Каждый экземпляр Р является предком только в одном экземпляре набора;
2. Каждый экземпляр C является потомком не более чем в одном экземпляре набора.
Основные свойства набора:
- набор имеет имя, в каждом наборе только один владелец, в каждом наборе 0, 1 или несколько членов, набор существует, только если существует запись - владелец. поскольку набор имеет имя, то два экземпляра записи могут быть в разных наборах, экземпляр записи может входить только в один экземпляр набора данного типа. в общем случае каждый набор - это вход в БД;
С помощью наборов можно строить многоуровневые деревья и простые сетевые структуры. Так как роль записи жестко не фиксируется, то в одном наборе запись (файл) может быть членом, а в другом владельцем, поэтому такая модель и называется моделью с равноправными файлами.
В сетевых моделях реальных СУБД запись может иметь любую структуру, например, простую линейную, как в реляционной БД, либо более сложную, включая массивы, группы, повторяющиеся группы. Совокупность однотипных записей образует файл, а совокупность файлов и наборов, описанных в одной схеме, образует сетевую БД. Допускаются изолированные, не связанные с другими, файлы.
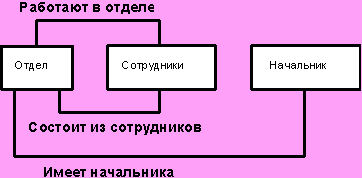
Рис. Пример сетевой схемы БД
Типы наборов
В зависимости от способа физического хранения различают одночленные, многочленные и сингулярные наборы. Одночленный набор включает только один файл - член. Многочленные наборы состоят из трех и более файлов (рис. 7.7б), сингулярный набор - это особый набор, в котором владельцем является система. В каждом сингулярном наборе всего один экземпляр. Сингулярные наборы чаще всего применяются, чтобы получить доступ ко всем записям файла - владельца, а также чтобы объединить записи, не имеющие владельца.
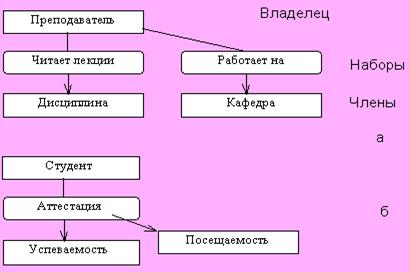
Рис. Примеры одночленного (а) и многочленного (б) наборов
Отображение инфологической модели в сетевую модель данных
Процесс датологического проектирования сетевой БД отличается от такового для реляционных БД тем, что необходимо явно задать наборы как модели связей между объектами. Если структура каждой записи файла линейная (как в реляционной БД), то на этом отличия и кончаются. Если структура записей сложная, то связи между объектами можно отобразить двумя путями: как наборы (связи между записями) и как связи внутри записей файла.

Рис. Пример выбора сложных внутризаписных структур
Внутризаписные сложные структуры рекомендуется применять в следующих случаях (рис. ):
1. Если объект (понятие) имеет множественные свойства;
2. Если объект имеет составные свойства;
3. Если связи между объектами 1:М, где М - невелико и объект не связан с другими объектами.
В остальных случаях каждое понятие ER - модели представляется отдельным файлом.
Лабораторная работа № 6. Моделирование вычислительных процессов в ЭИС
Форма хранения данных в ЭВМ часто существенно отличается от представления пользователя и программиста. Терминология при этом зависит от того, какой носитель информации имеется в виду - оперативная память ЭВМ, магнитный диск, магнитная лента, оптический диск. Рассмотрим основные из этих терминов.
Общие сведения
Физическая запись (ее еще называют блоком или сектором) - элементарная единица данных, которая может быть считана или записана одной командой ввода - вывода ЭВМ. Например, размер сектора для MS DOS - 512 байт. Обычно одна физическая запись состоит из нескольких логических записей. Обмен данных с оперативной памятью происходит только целыми блоками.
Часть оперативной памяти, предназначенная для хранения одной физической записи, называется буфером. Количество буферов задается пользователем при настройке операционной системы.
Кластер - это несколько (2-4) смежных секторов.
Файл - это совокупность физических записей, они могут размещаться как в смежных областях внешней памяти, так и быть “разбросаны”.
Физическая организация данных - это устойчивый порядок расположения записей и способ обеспечения взаимосвязей между ними.
Логическая и физическая организации данных относительно независимы, т. к. преследуют разные цели. Цель логической организации данных - наиболее ясное и полное отображение информации об объектах и связях между ними. Цель физической организации - максимальная скорость выдачи ответа на запрос и эффективное использование памяти ЭВМ.
Обычно при создании ЭИС выбирают ту физическую организацию данных, которая принята для выбранных технических средств. Изменение ее может произвести лишь системный программист. Физическая организация данных определяется типом ЭВМ, ОС и СУБД. При этом учитывают следующие факторы:
- эксплуатационные характеристики технических средств (объем памяти, внешней памяти, тип внешних ЗУ, скорость ввода-вывода); стоимость технических средств; тип преобладающих запросов к ЭИС.
Можно выделить три основных типа запросов:
- создание структуры, включая размещение основных и вспомогательных данных; поиск по одному или нескольким ключам; коррекция, включая поиск ее места и перестройку структуры основных и вспомогательных данных.
Рассмотрим критерии оценки эффективности физической организации данных:
1. Эффективность доступа Эд = 1/N , где N - среднее число физических обращений к записям для организации одного логического запроса, зависит от типа запроса и организации данных.
2. Эффективность хранения Эx = 1/К, где К - среднее число дополнительных байтов памяти, необходимых для хранения одного байта основных данных (дополнительная память расходуется для хранения указателей, служебных таблиц, индексов, резервных участков и т. п. и зависит от метода организации данных).
3. Доля выборки D = Mнуж / M, где Мнуж - число нужных записей для запроса; М - общее число записей файла.
В зависимости от D различают три вида поиска:
- получить все или многие записи [D =%], получить уникальную запись [Мнуж = 1], получить некоторые записи [D = 0 - 10%].
Совокупность соглашений о физической организации данных и алгоритмов выполнения запросов называют методом доступа. Обычно выделяют три группы методов доступа:
1. Последовательные методы (применяют для D =%);
2. Индексные методы (для D = 0 -10%)
3. Адресные (эффективны для Мнуж = 1).
Последовательные методы доступа
Они предполагают последовательный перебор записей, когда расположение в памяти i-ой записи определяется в зависимости от места (i-1) - ой записи. Первая запись имеет фиксированный адрес. В зависимости от способа вычисления адреса следующей (предыдущей) записи различают несколько разновидностей этого метода доступа. Первые три метода характерны тем, что данные занимают в памяти смежные участки. Остальные методы используют понятие списка.
Список - это множество записей, последовательность обработки которых задается с помощью указателей.
Списковые разновидности последовательного метода доступа позволяют логически соединить разрозненные участки памяти.
а) Последовательный доступ с фиксированной длиной записей
Адрес любой записи Ai определяется по формуле: Аi = А1 + (i - 1) * L, где А1 - адрес первой записи; | Если записи располагаются в ОП, то такая организация соответствует понятию "массив" в языках программирования. Если записи расположены на магнитном диске или ленте, то порядок ввода или вывода данных зависит от языка программирования. Чаще всего допускается только перебор записей от начала к концу файла. |
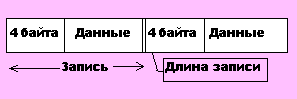
б) Последовательный доступ с записями переменной длины
Обычно каждая запись содержит значение Li - длины этой записи. | Например, в ЕС ЭВМ структура записей переменной длины такова:
|
в) Последовательный доступ с записями неопределенной длины.
Конец каждой записи помечается специальным символом. Например, в MS DOS текстовые файлы состоят из записей, каждая из которых кончается символом “конец строки”. |
|
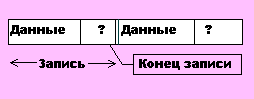
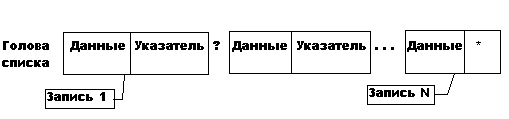
г) Простой линейный список.
Возможны два варианта: когда указатель хранится вместе с записью и когда указатели хранятся отдельно от данных.
Вариант 1:
Вариант 2:
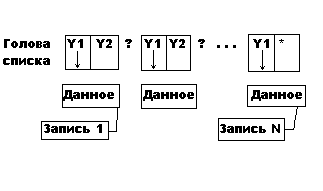
где Y1 - указатель на данные, а Y2 - указатель на следующую запись.
Голова списка (адрес начала списка) хранится в специальной фиксированной ячейке памяти и может быть, как в ОП, так и файле.
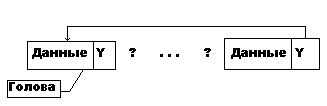
д) циклический однонаправленный список
Связь от последней записи идет к первой. Здесь можно получить доступ к любой записи, начиная с любой.
е) Двунаправленный список (простой и циклический).
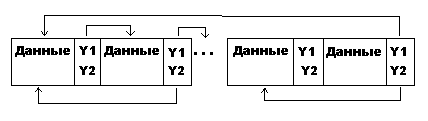
![]()
Каждая запись имеет два указателя, кроме того, список имеет две головы. Достоинство списка: ускоряет доступ к записям.
Заключение
Основой построения списковых структур являются указатели, в качестве которых применяют либо физический адрес записи, либо символический указатель (номер записи или ключ). Первый тип указателей применяют, когда надо получить наибольшую скорость обработки данных. Второй тип указателей позволяет перемещать записи друг относительно друга, включать и удалять записи в список без изменения указателей во всех остальных записях списка, но скорость доступа меньше, чем в первом случае.
Если указатели хранятся вместе с записью, то они называются встроенными; если же отдельно - то они образуют справочник, или индекс.
Индексные методы доступа
Основная идея состоит в следующем: в дополнение к основному файлу данных создается индексный файл, который содержит значения ключей и указатели на соответствующую запись. Индексный файл упорядочен по значению ключа. Обычно индексный файл меньше по размеру, чем основной, и скорость поиска в нем выше, так как он отсортирован.
ж) Метод доступа с полным индексом
Для каждой записи основного файла в индексном файле существует отдельная запись (ключ + адрес блока записей).
Индексный файл организован последовательно (метод а):
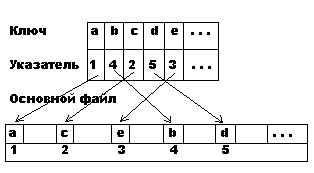
Такая организация используется, когда основной файл не очень велик. Если надо упорядочить исходный файл по нескольким ключам, для него создается столько же индексных файлов.
Когда индексный файл содержит вторичные ключи, он называется инвертированным по данному ключу по отношению к основному файлу.
Так как значения вторичных ключей не уникальны, то индексный файл организован по методу б) или в).
Пример:
Найдем записи, для которых X = 5 и Y = b1. По файлу 2 находим адреса для Х=5 (По файлу 1 находим адреса для Y=b1 (Пересечение этих массивов дает результат: запись 500.
Основной эффект инвертированных массивов проявляется при поиске уникальной записи по нескольким условиям. Алгоритм поиска можно построить так, чтобы обращаться только к индексным файлам. Это ускоряет поиск, особенно если весь индексный файл помещается в оперативной памяти. Рассмотренный метод становится неэффективным, если требуется обработка всех записей.
з) Индексно - последовательный метод.
Основной файл всегда упорядочен по первичному ключу; индексный файл содержит ссылки не на каждую запись, а на группу (блок) записей и значение одного из ключей в группе - первого или последнего ключа. Повторение ключей в группе недопустимо. В группе должно быть одинаковое число записей. Блок обычно образуется как физический блок записей (дорожка МД, цилиндр МД, сектор МД и т. п.).
Таким образом, объем индексного файла уменьшается. Основной эффект достигается, когда основной файл на внешнем ЗУ, а индексный в ОП.
На рис. 8.1. приведен пример индексно-последовательной организации данных.
Так как индексный файл упорядочен по ключу, к нему можно построить еще один индексный файл и т. д., пока на верхнем уровне не окажется всего один блок. Такая многоуровневая структура называется бинарным деревом (В-деревом).
Достоинство В-дерева: меньший объем индексного файла, простота расширения индекса, высокая скорость поиска. На эффективность доступа и хранения влияет размер блока: чем больше размер блока, тем их меньше и меньше элементов индекса, но больше время перебора внутри блока.
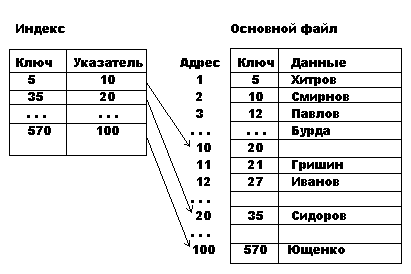
Рис. 8.1
Пример. Построим бинарное дерево, содержащее ссылки на конец группы (будем изображать только значения ключа).
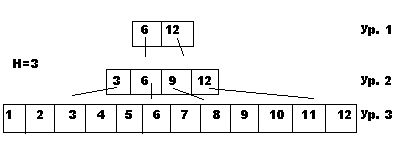
Поиск записи требует H обращений к индексному файлу, где H - число уровней индексов. Например, найдем запись с ключом К=8. Путь поиска: Ур<8<12), Ур<8<9), ур.3 - перебор двух ячеек (от 9 к 8).
Адресные методы доступа
В этих методах значение ключа К с помощью специальной адресной функции преобразуется в значение адреса записи. Адресные функции бывают двух видов:
- реализуют взаимно-однозначное соответствие А <-> K (прямой доступ к записи); реализуют однозначное соответствие К->A, но не наоборот (хеширование).
и) прямой доступ к записи
Здесь физический адрес записи непосредственно определяется из записи. Например: ключ файла “СТУДЕHТ” - HОМЕP ГPУППЫ + HОМЕP СТУДЕHТА В ГPУППЕ. Пусть Номер группы Nгр = 1...100, Номер_студента Nстуд = 1..25. Тогда Номер записи Nзап = (Nгр - 1) * 25 + Nстуд
Hедостатки метода:
1. низкая эффективность хранения данных при нерациональной кодировке или низкой плотности значений ключа;
2. обязательна уникальность ключа.
Достоинство: высокая скорость выборки и простота.
к) произвольный метод доступа (хеширование)
Хеширование в переводе означает “перемешивание”. Суть метода - вычисление адреса записи в соответствии с алгоритмом хеширования, который в общем случае для разных значений ключей может дать один адрес записи. Этот случай называется коллизией. Варианты данного метода доступа отличаются друг от друга видом хеш-функции и методом разрешения коллизий.
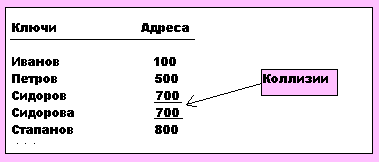
Хеш - функция должна равномерно отображать множество возможных значений ключа в множество адресов записей. Существуют различные хеш - функции. Например, остаток от деления ключа на число М : H(К) = К * mod(M) . В данном случае выбор М - решающий для числа коллизий. Рекомендуется выбирать в качестве М простое число, равное или близкое к размеру участка памяти.
Когда память не заполнена, коллизия возникает редко, но со временем память заполняется записями и вероятность коллизии возрастает. Есть два способа разрешения коллизий:
1. Метод открытой адресации - при появлении коллизии во время добавления записи ищется свободный участок памяти, куда и добавляется новая запись. При поиске записи поступают аналогично: сначала производят поиск по адресу, а затем - если запись с искомым ключом не найдена - последовательно просматриваются остальные участки памяти.
2. Метод цепочек - каждая запись имеет ссылку на область переполнения, где записаны цепочки коллизий (см. рис. 8.2).
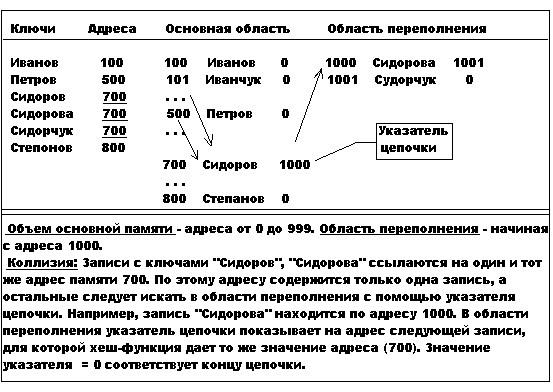
На эффективность данного метода влияют три фактора:
- распределение исходных ключей (чаще всего оно отличается от равномерного), распределение памяти (то есть объем памяти определяет вероятность коллизии), соответствие функций распределения ключей записей и адресов памяти.
Тесты
Основные понятия ЭИС.
Тест 1. Установите соответствие между терминами и их определениями, вписав соответствующий номер определения в столбец слева от термина.
База данных | 1. Программно-аппаратный комплекс, предназначенный для автоматизированного сбора, хранения, обработки и выдачи информации | |
Система | 2. Поименованная совокупность взаимосвязанных данных | |
Информация | 3. Часть реального мира отображаемая в информационной системе | |
СУБД | 4. Операционная система и технические средства | |
Предметная область | 5. Комплекс языковых и программных средств, предназначенный для управления работой базы данных | |
Персонал | 6. Материальный носитель информации, имеющий юридическую силу и оформленный в установленном порядке | |
Данные | 7. Специалисты, которые обеспечивают создание, работу и развитие банка данных | |
Документ | 8. Комплекс взаимосвязанных средств, выступающих как единое целое | |
Информационная система | 9.Некоторые сведения, знания об объектах и процессах реального мира | |
Программно-аппаратная платформа | 10. Информация, представленная в формализованном виде, который позволяет передавать или обрабатывать ее при помощи технических средств |
Тест 2. Выбрать один из предложенных ответов

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
