



1. , Пархомов технологии в экономике: Учеб. пособие Иркутск: Изд-во БГУЭП, 2004 г.
2. К. Дж. Дейт Введение в системы баз данных Издательство: Вильямс, 2006 г. 1328 стр.
3. Мишенин экономических информационных систем. - М.: Финансы и статистика, 2008. – 12 л.
4. , Салмин экономических информационных систем. Практикум - М.: Финансы и статистика, 20c.
5. , , Трубилин системы и технологии в экономике: Учебник. / Под ред. . - М.: Финансы и статистика, 2л.
Дополнительная
1. Объектно-ориентированный анализ и проектирование. М.:Бином, 1998
2. Вендров A. M. CASE - технологии. Современные методы и средства проектирования информационных систем. . М.: Финансы и статистика, 1998.
3. - Базы данных: проектирование и использование. Учебник. - М.: Финансы и статистика, 2л.
4. Калянов и средства системного структурного анализа и проектирования. М.: МГУ, 1995
5. Кузнецов баз данных. Курс лекций. Издательство: Интернет-университет информационных технологий, 2005 г.488 стр.
6. Г. Хансен., Д. Хансен. Базы данных. Разработка и управление. Москва, ЗАО “Издательство БИНОМ”, 1999.
7. Системы управления базами данных и знаний. /Под ред. . М., 1991.
8. Уэно X. и др. Представление и использование знаний. / Пер. с япон:- М.: Мир, 19с.
Методическое обеспечение дисциплины
1. Лекции по дисциплине «Теория экономических информационных
систем» - выдаются студентам в электронном виде.
2. Лабораторные работы по дисциплине.
3.УМК «Теория экономических информационных систем».М. РГТЭУ, 2008.
Материально-техническое и информационное обеспечение дисциплины
1. - Компьютерное и мультимедийное оборудование;
2. - Электронная библиотека курса;
3. Интернет ресурсы:
http://www. ecsocman. *****/db/ - федеральный образовательный портал
http://www. *****/ - Профессиональная работа с информационными ресурсами Интернета
http://www. ecsocman. *****/db/msg/117106.html - Проектирование интеллектуальных систем в экономике
10. ИННОВАЦИОННЫЕ ТЕХНОЛОГИИ, ИСПОЛЬЗУЕМЫЕ В ПРЕПОДАВАНИИ ДИСЦИПЛИНЫ
Будем считать инновационным такой подход к учебному процессу, при котором целью обучения является развитие у учащихся возможностей осваивать новый опыт на основе целенаправленного формирования творческого и критического мышления, опыта и инструментария учебно-исследовательской деятельности, ролевого и имитационного моделирования.
(Инновационным подход использован в лабораторных работах №4,5 и в тестах).
11. ПРИЛОЖЕНИЯ
Лабораторные работы
Лабораторная работа № 1. История и основные направления развития ЭИС
Понятие информационной системы (ИС) на протяжении своего существования претерпело значительные изменения. Первоначально ИС считалась любая система, позволяющая собирать, хранить и обрабатывать информацию, например – система каталогов в библиотеке, телефонный справочник и т. п. С появлением ЭВМ к ИС стали относить программы, которые выполняют перечисленные функции и имеют дело с большими объемами информации. Условно можно выделить три поколения ИС. Рассмотрим основные характеристики компонентов этих ИС.
Первое поколение предназначалось для решения установившихся задач, которые четко определялись на этапе создания системы и затем практически не изменялись.
Основные черты1-го поколения ИС:
- Техническое обеспечение систем составляли ЭВМ 2-3 поколения. Информационное обеспечение (ИО) представляло собой массивы (файлы) данных, структура которых определялась той программой, в которой они использовались. Программное обеспечение - специализированные прикладные программы, например, программа начисления заработной платы. Архитектура ИС - централизованная. Как правило, применялась пакетная обработка задач. Конечный пользователь не имел непосредственного контакта с ИС, вся предварительная обработка информации и ввод производились персоналом ИС.
Недостатки ИС 1-го поколения:
- Сильная взаимосвязь между программами и данными, то есть изменения в предметной области приводили к изменению структуры данных, а это заставляло переделывать программы. Трудоемкость разработки и модификации систем. Сложность согласования частей системы, разработанных разными людьми в разное время.
Второе поколение. Стремление преодолеть указанные недостатки породило в 70-х годах технологию баз данных. База данных создается для группы взаимосвязанных задач, для многих пользователей и это позволяет частично решить перечисленные проблемы. Вначале СУБД разрабатывались для больших ЭВМ, и их количество не превышало десятка. Каждая система была уникальным и очень сложным произведением, но на ее основе можно было намного быстрее и эффективнее разрабатывать прикладные ЭИС. Однако стоимость самой развитой СУБД была и остается очень большой. Благодаря появлению ПЭВМ технология БД стала массовой, создано большое количество инструментальных средств и СУБД для разработки ИС, что в свою очередь вызвало появление огромного количества прикладных ИС в разных областях, в том числе в области экономики, которые отличаются эффективностью, полнотой функций и уровнем сервиса.
Основные черты 2-го поколения ИС:
- Основу ИО составляет база данных, Программное обеспечение состоит из прикладных программ и СУБД. Технические средства: ЭВМ 3-4 поколения и ПЭВМ. Средства разработки ИС: процедурные языки программирования 3-4 поколения, расширенные языком работы с БД (SQL, QBE). Архитектура ИС: наиболее популярны две разновидности: персональная локальная ИС, централизованная БД с сетевым доступом.
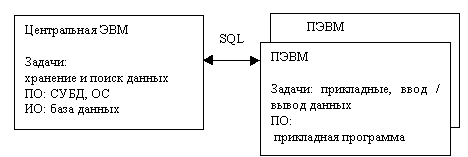
Рис. Архитектура централизованной БД с сетевым доступом
Большим шагом вперед явилось развитие принципа "дружественного интерфейса" по отношению к пользователю (как к конечному, так и к разработчику ИС). Например, повсеместно применяется графический интерфейс, развитые системы помощи и подсказки пользователю, разнообразные инструменты для упрощения разработки ИС: системы быстрой разработки приложений (RAD-системы),средства автоматизированного проектирования ИС (CASE - средства).
К концу 80-хгодов выявились и недостатки систем 2-го поколения:
- большие капиталовложения в компьютеризацию предприятий не дали ожидаемого эффекта, соответствующего затратам (увеличились накладные расходы, но не произошло резкого повышения производительности); внедрение ИС столкнулось с инертностью людей, нежеланием конечных пользователей менять привычный стиль работы, осваивать новые технологии; к квалификации пользователей стали предъявляться более высокие требования (знание персонального компьютера, конкретных прикладных программ и СУБД, способность постоянно повышать свою квалификацию).
В связи с этим постепенно стало формироваться 3-е поколение ИС. Рассмотрим основные черты современного поколения ИС.
Техническая платформа - мощные ЭВМ 4-5поколения, использование разных платформ в одной ИС (большие ЭВМ, мощные стационарные ПК, мобильные ПК). Наиболее характерно широкое применение вычислительных сетей - от локальных до глобальных.
Информационное обеспечение: ведутся интенсивные разработки с целью повышения интеллектуальности банка данных в следующих направлениях:
- новые модели знаний, учитывающие не только структуру информации, но и активный характер знаний,
· средства оперативного анализа информации OLAP (аббревиатура от английского On-Line Analytical Processing; предназначение OLAP систем - предоставлении информации для принятия решений) и средства поддержки принятия решений (СППР, DSS - Decision Support System, метод организации взаимодействия человека и компьютера в виде итерационного процесса 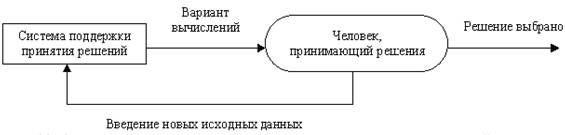 )
)
- новые формы представления информации, более естественные для человека (мультимедиа, полнотекстовые БД, гипертекстовые БД, средства восприятия и синтеза речи).
Программное обеспечение: существенно новым является появление и развитие открытой компонентной архитектуры ИС. Компонент - это программа, выполняющая какой-либо осмысленный с точки зрения конечного пользователя набор функций и имеющая открытый интерфейс. ПО ИС собирается из готовых компонентов, как мозаика из фрагментов. С другой стороны, компонент может функционировать на разных типах ЭВМ и связь между компонентами устанавливается не на этапе компиляции, а в реальном масштабе времени. Такой принцип построения позволяет использовать огромный накопленный опыт программистов, ускорять разработку ИС, создавать распределенные ИС.

Рис. Трехступенчатая архитектура ЭИС
Архитектура ИС: стала более разнообразной в связи с многоплатформенностью. Так, в настоящее время развивается трехступенчатая модель ИС. Благодаря такому построению снижаются требования к клиентским машинам и общая стоимость системы, повышается общая эффективность и производительность. Узким местом является пропускная способность и надежность вычислительных сетей.
Методы разработки ИС: при традиционном подходе сначала выявлялись информационные потоки на предприятии, а затем к этой структуре привязывалась ИС, повторяя и закрепляя тем самым недостатки организации бизнеса. В90-93 г. г. бурно обсуждалась идея бизнес - реинжиниринга, предложенная М. Хаммером. Она состоит в том, что для получения существенного эффекта от ЭИС необходимо одновременно с разработкой ИС пересмотреть и бизнес-процессы, удалив и упростив некоторые из них. Например, в результате реорганизации службы оплаты поставок в компании Форда штат (500чел.) был сокращен на 75 %, а число полей в бланке с 14 до 3.
Другая идея - создание ИС с расчетом на длительную или постоянную модернизацию, причем система в каждый период своей жизни приносит пользу и способна развиваться дальше.
Наконец, при создании ИС необходим учет национальной, профессиональной и корпоративной культуры, так как человеческий фактор часто является решающим для успеха.
Таким образом, современная корпоративная ЭИС должна создаваться как часть предприятия, включающая бизнес-архитектуру, персонал и информационные технологии.
Лабораторная работа № 2. Экономические документы и их структура
Состав документов, которые обрабатываются ИС, определяется на этапе формулировки требований к ЭИС. При этом могут использоваться формальные модели типа DFD, а может быть составлен и простой перечень входных и выходных документов. В любом случае после определения состава документов необходим их анализ, чтобы определить, как же информация об объектах предметной области будет отображается в ИС.
Пусть, например, требуется хранить сведения о деталях, поступивших на склад. Как объект реального мира - деталь - будет отображена в базе данных? Для того чтобы ответить на этот вопрос, необходимо знать, какие свойства детали будут необходимы для работы ИС. Среди них могут быть название детали, ее вес, размер, цвет, дата изготовления, материал, из которого она сделана и т. д. Состав этих свойств зависит от решаемых системой задач. Значения этих свойств объектов являются единицами информации, и именно они хранятся в БД.
Каждый документ, как правило - это свидетельство какого-либо события реальной жизни, в процессе которого взаимодействуют два или несколько объектов. Например, Приходный ордер отображает факт поступления товара на склад, поэтому он содержит названия этих объектов и другие их свойства (количество, цена товара, номер склада, ФИО кладовщика, сведения о поставщике товара), дату события. То есть приходный ордер отображает взаимодействие таких объектов, как товары, склад, поставщик товаров.
Целью анализа документов является выявление актуальных, существенных для ИС свойств объектов и их группировка по смыслу.
Отдельные поля документа называют "реквизитами". Каждый реквизит отображает одно свойство какого-либо объекта, имеет имя и значение. Множество всех допустимых значений реквизита называется областью определения. Реквизиты делятся на два вида:
- признаки, которые определяют обстоятельства события (место, время, действующих лиц, единицы измерения, номера документов и т. п.);
- основания, которые определяют количественные свойства объектов или процессов (цена, количество, сумма, вес и др.).
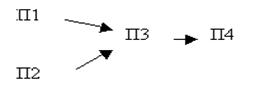
Реквизит является элементарной единицей информации. Они могут группироваться и образуют составные единицы информации (СЕИ), среди которых особо выделяют экономический показатель - элементарный осмысленный фрагмент документа, содержащий один атрибут - основание и ряд логически связанных с ним признаков П (О, Р1, Р2,….Рn). Минимальный набор атрибутов показателя включает основание, имена объектов, участвующих в процессе, и время действия. Для наглядного изображения логических и расчетных связей между показателями и для показа последовательности их расчета применяют граф взаимосвязи показателей, в котором вершины соответствуют показателям, а дуга идет от П1 к П2, если при расчете П2 используется основание П1.
Пример. На рис. показан примерный вид приходного ордера. Выделим признаки, снования и показатели. Признаки: Номер ордера, Дата, Наименование п. п, Адрес, Код поставщика, Ном.№, Наим. Товара.
ПРИХОДНЫЙ ОРДЕР № 000 от 1.02.05
Наименование п. п. АО РУБИН Адрес: Москва, ул. | Код поставщика 34 | |||
Номенкл. № | Наименование товара | Цена (тыс. руб) | Количество | Сумма |
11 22 | ПК Бумага | 5. 0.1 | 2 20 | 10 2 |
ИТОГО: | 12 |
Рис. Общий вид экономического документа
Основания: Цена, Кол., Сумма, Итог.
Показатели: П1 (Кол., Номер ордера, Дата, Ном. №)
П2 (Цена, Ном. номер, Код поставщика, Дата)
П3 (Сумма, Номер ордера, Дата, Ном. №)
П4 (Итог, Номер ордера, Дата).
Рас четные формулы, отражающие связь оснований показателей:
Сумма = Цена * Кол |
Рис. а. Граф взаимосвязи показателей |
Таким образом, анализ документов проводят в следующем порядке:
- Анализ структуры документов, выделение существенных признаков, оснований, показателей.
- Выявление взаимосвязей между показателями, запись расчетных формул.
- Построение графа взаимосвязи показателей.
После этого начинается следующий этап: определение структур данных, хранящихся в базе данных. Для этого чаще всего применяют диаграммы структуры данных (DSD) и ERD-диаграммы.
Информационный процесс. Диаграмма потоков данных.
Модель, разработанная Гэном и Сарсоном, представляет собой несколько иерархически связанных диаграмм потоков данных (ДПД), которые описывают процесс преобразования данных от ввода в систему до выдачи пользователю.
На верхнем уровне диаграмма определяет входы, выходы системы и основные процессы. На более детальных диаграммах каждый процесс уточняется. Достоинствами модели являются ее относительная простота, возможность установления логических связей с другими видами моделей, возможность строгого определения структуры ИС на самой ранней стадии разработки, что особенно важно для сложных систем.
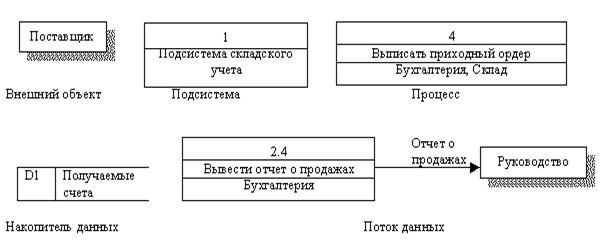
Рис.3.1. Изображение компонентов диаграмм
Внешний объект - это предмет или лицо, являющийся источником или приемником информации, например, - заказчик, поставщик, клиент. Система и подсистемы - это части ИС.
Процесс - это преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. Процесс изображается так же, как подсистема, прямоугольником и имеет номер, имя (имя начинается глаголом в неопределенной форме - "вычислить", "создать"…) и поле физической реализации. Физически процесс может быть отделом фирмы, который обрабатывает документы, либо программой, либо техническим устройством обработки данных, например - оформление приходного ордера производится в бухгалтерии.
Накопитель данных - это устройство для хранения информации. Физически это может быть ящик в картотеке, файл на магнитном носителе, оперативная память ЭВМ. Накопитель данных - это прообраз будущей базы данных, поэтому описание хранящихся в нем данных должно быть увязано с информационной ER - моделью.
Поток данных - это информация, передаваемая через некоторое соединение от источника к приемнику, например, - почтовые отправления, переносимые магнитные носители (диски), передаваемые курьером документы.
Порядок построения диаграммы
Шаг 1. Построение контекстных диаграмм верхнего уровня иерархии.
- для простых систем строится одна звездообразная диаграмма, в центре которой - главный процесс, соединенный потоками с внешними объектами;
- для сложных систем (с числом внешних объектов больше 10) диаграмма содержит не один главный процесс, а набор подсистем, соединенных потоками данных.
- подробно описывают все потоки и накопители данных с помощью диаграмм структур данных и списка событий.
Диаграмма структуры данных показывает, из каких компонентов состоит поток данных, и строится в виде дерева. 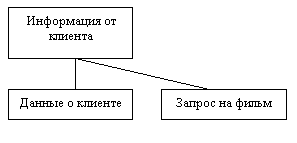
Рис. Пример структурной диаграммы
Список событий описывает различные действия внешних объектов и реакцию системы на них, он представляется в виде таблицы "Событие / Реакция". Список событий соответствует потокам данных: каждое событие формирует входной поток, а реакция - выходной поток ИС
Шаг 2. Детализация подсистем и процессов.
Для каждого блока строится своя детальная диаграмма, при этом следует соблюдать правила:
- правило балансировки: детальная ДПД любого блока в качестве внешних источников и приемников может иметь только те компоненты, с которыми имел связь родительский блок;
- правило нумерации: следует соблюдать иерархическую нумерацию процессов, например, при детализации процесса 5 вложенные процессы будут нумероваться 5.1, 5.2 и т. п.
Детализация ведется до тех пор, пока процессы не станут простейшими и дальнейшее уточнение нецелесообразно (у процесса остается не более 2-3 потоков, несложно составить и кратко описать алгоритм процесса). На самом нижнем уровне детализации для каждого процесса составляется мини-спецификация (описание логики алгоритма, которое может быть представлено в словесной форме и/или в виде схемы алгоритма).
Шаг 3. Проверка построенных диаграмм на полноту и правильность связей.
Все процессы должны быть детализированы, для всех потоков и накопителей данных должно соблюдаться правило сохранения информации (все входящие данные должны быть считаны, а все выходящие должны быть записаны).
Пример построения диаграммы
В качестве предметной области рассмотрим работу видеотеки, которая получает запросы от клиентов на фильмы, проверяет членство клиентов, контролирует возврат лент, не допуская выдачу фильмов тем, кто просрочил аренду фильма. За аренду начисляется плата, за просрочку возврата - пени. Информация об аренде лент хранится отдельно от записей о членстве клиентов. Новые фильмы видеотека получает от поставщиков, фиксируя информацию о них. Служащие регулярно готовят отчеты для руководства за определенный период времени о членах видеотеки, поставщиках лент, выдаче фильмов и приобретенных лентах.
Итак, приступим к анализу предметной области. Из его описания следует, что в работе видеотеки участвуют следующие группы людей: клиенты, поставщики, руководство и работники Видеотеки. К внешним объектам можно отнести первые три группы пользователей. Начальная ДПД будет иметь звездообразный вид. В центре находится процесс 0-го уровня "Видеотека", соединенный потоками данных с внешними объектами.
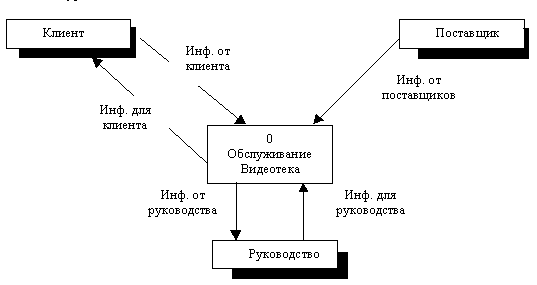
Рис. Начальная контекстная диаграмма
Уточним содержание потоков данных:
1. Информация от клиента включает данные о клиенте и запрос на фильм;
2. Информация для клиента включает ответ на запрос об аренде фильма и членскую карточку.
3. Информация от поставщика включает данные о поставщике и о новых фильмах;
4. Информация от руководства включает: запросы отчетов о новых членах, о новых поставщиках, о новых фильмах; об аренде фильмов, о составе видеотеки, о поставщиках вообще.
5. Информация для руководства включает все эти виды отчетов.
Каждый входной поток данных порожден каким-либо событием, а выходной поток данных является ответом (реакцией) системы. Составим список событий в виде таблицы:
Событие | Реакция системы |
Новый клиент хочет стать членом видеотеки | Регистрация клиента |
Клиент сообщает об изменении адреса | Регистрация нового адреса |
Клиент просит фильм в аренду | Рассмотрение запроса |
Клиент возвращает фильм | Регистрация возврата |
Руководство находит нового поставщика | Регистрация нового поставщика |
Изменение данных о поставщике | Регистрация изменений |
Поставщик передает новый фильм | Получение нового фильма |
Руководство запрашивает отчет о работе | Формирование требуемого отчета |
Теперь можно разбить процесс 0-го уровня "Обслуживание видеотеки" на 4 процесса, отражающие основные виды деятельности видеотеки: учет членов, учет поставщиков, учет аренды фильмов, управление фондом фильмов. Поскольку компонентов системы все еще не очень много, то можно изобразить ДПД в целом.
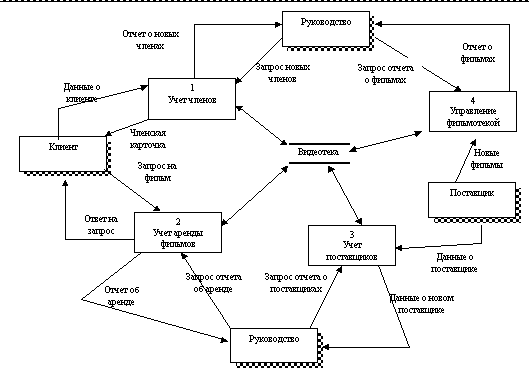
Рис. Уточненная контекстная диаграмма (уровень 1)
На следующем этапе можно продолжить детализацию процессов, например, рассмотрим детализацию процесса 1 - учет членов библиотеки. Этот процесс можно разбить на 4 подпроцесса 1.1-1.4 . В центре детальной диаграммы находится накопитель данных "Члены библиотеки".
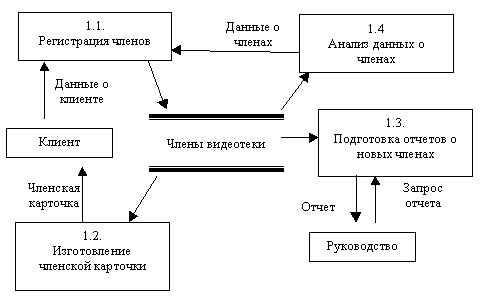
Рис. Детализация контекстной диаграммы
Каждый процесс на этой диаграмме имеет 2-3 входных и выходных потока данных, поэтому их дальнейшая детализация нецелесообразна.
Теперь можно составить описание алгоритма каждого процесса. Например, опишем алгоритм процесса 1.1:
а) начало
б) получить от клиента данные для регистрации
в) сравнить данные клиента со списком членов видеотеки (процесс 1.4)
г) проверить: был ли клиент зарегистрирован ранее,
д) если нет - то занести данные клиента в накопитель "Члены видеотеки"
е) в противном случае проверить: является ли клиент должником;
ж) если да - отказать клиенту в повторной регистрации и потребовать возврата долга; затем перейти к шагу "и";
з) в противном случае - обновить информацию о клиенте в накопителе "Члены видеотеки" и перейти к процессу 1.2.
и) конец.
Аналогично следует рассмотреть детализацию процессов 2-4, построить соответствующие детальные контекстные диаграммы и составить описание алгоритмов выполнения простейших процессов.
Построение диаграмм потоков данных можно облегчить и ускорить с помощью средств автоматизации (CASE-средств): пакета CASE-аналитик, программы BPWin и др.
Задание 3. Модель "сущность-связь" (ER-модель) .
Семантические модели предназначены для отображения смысла информации, циркулирующей в предметной области. Любая развитая модель включает в себя три компонента:
- средства описания структуры информации (структурная часть), описание операций над данными (манипуляционная часть) и описание ограничений целостности.
Одной из наиболее популярных семантических моделей является модель "сущность - связи" или ER - модель (Entity - Relationship), на использовании которой основано большинство современных подходов к проектированию баз данных. Модель была предложена Ченом (Chen) в 1976 г. и представляет собой ряд графических диаграмм, включающих небольшое число разнородных компонентов. Основными компонентами ER - модели являются сущность, связь и атрибут.
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна.
Основной единицей представления знаний об однородных сущностях является тип сущности (понятие). Понятие образуется при выделении тех свойств сущностей, которые наиболее важны для решения задач пользователя ЭИС. Например, понятие СТУДЕНТ объединяет сущности Иванов А, Ю., ; понятие ПРЕДПРИЯТИЕ включает в себя сущности завод ВЭМ, банк Тарханы, кафе “Пирожки”.
| В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя понятия. Иногда в прямоугольнике приводят примеры понятий. |
Считается, что каждое понятие полностью описывается совокупностью его свойств. Таким образом, каждое понятие должно иметь следующие характеристики:
- имя, объем (количество сущностей, которые можно описать данным понятием), содержание (совокупность свойств).
Свойство (атрибут) - это элементарная единица структуры понятия, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности.
Например, свойства понятия СТУДЕНТ - код студента, фамилия, имя, № зачетки, группа, адрес, возраст, пол и т. п.
Набор свойств понятия в принципе бесконечен, но при разработке ЭИС он зависит от информационных потребностей пользователя и решаемых им задач. При составлении инфологической модели следует как можно более полно описать свойства понятий, учитывая не только текущие задачи, но и возможные будущие потребности пользователей ЭИС.
Свойства понятий делятся на три типа :
- Ключевые свойства позволяют различить сущности внутри одного понятия (ключ может состоять из нескольких свойств).
- Дифференциальные свойства содержат смысл понятия (то, что отличает его от других понятий).
- Валентные свойства служат для связи между разными понятиями.
Например, "Код студента" - ключевое свойство, так как оно уникально для каждого студента;
Фамилия, Имя, Адрес - дифференциальные свойства (они отличают это понятие, например, от понятия ПРЕДПРИЯТИЕ;
Группа - валентное свойство, так как оно может применяться для связи с понятием СПЕЦИАЛЬНОСТЬ.
Для краткого описания понятия используется его схема, которая представляет собой совокупность имен свойств понятия: P ( S1, S2, ... Sn). Ключевое свойство в схеме понятия выделяют подчеркиванием. Например: СТУДЕНТ (Код_студента, ФИО, Адрес, Группа); СПЕЦИАЛЬНОСТЬ (Код, Название, Факультет, Группы).
На ER - диаграммах свойства понятий отображаются по-разному в зависимости от разновидности модели. Например, на рис. а имена свойств записаны малыми буквами внутри прямоугольника, изображающего понятие, под именем понятия. На рис. б свойства вынесены за прямоугольник понятия и связаны с ним линиями, ключевое свойство выделено.
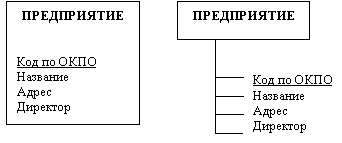
а) б)
Рис. Варианты изображения свойств понятия
Связь - это ассоциация между двумя понятиями. Она всегда является бинарной и может существовать между двумя разными понятиями или между понятием и им же самим (рекурсивная связь). В любой связи выделяются два конца, на каждом из которых указывается имя конца связи, степень конца связи (сколько сущностей данного понятия связывается), обязательность связи (т. е. любая ли сущность данного понятия должна участвовать в данной связи).
На диаграмме связь изображается в виде линии между понятиями. В месте присоединения связи к понятию используется "вилка" или стрелка, если связь может относиться к нескольким сущностям этого понятия. Одноточечный вход соответствует связи, в которой может участвовать только одна сущность из данного понятия. Обязательный конец связи изображается сплошной линией, а необязательный - прерывистой линией.
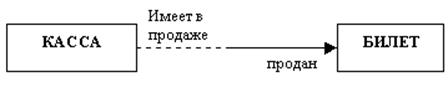
Рис. Изображение связи на ER- диаграмме.
Каждый БИЛЕТ продан одной конкретной КАССОЙ;
каждая КАССА может иметь в продаже 0, один или более билетов.
Характеристики связей и свойств
Важнейшими характеристиками связей между понятиями, а также между понятиями и их свойствами являются следующие:
- время существования - различают постоянные, долговременные и кратковременные связи. Например, значение свойства РАЗМЕР_СТИПЕНДИИ для понятия СТУДЕНТ обновляется раз в семестр, а свойство НОМЕР_ЗАЧЕТКИ постоянно на протяжении обучения. Время существования влияет на то, как отображается свойство или связь в базе данных: будет ли она заложена в структуру БД, либо будет реализована алгоритмическим путем (в программе). Кратковременные, легко вычисляемые свойства и связи рекомендуется реализовывать алгоритмически.
- избирательность - различают необязательные, возможные, условные и обязательные связи. Например, связь понятий СТУДЕНТ - СТИПЕНДИЯ зависит от успеваемости (условная связь), ЛИЧНОСТЬ - ИНОСТРАННЫЙ ЯЗЫК связаны необязательной связью, если предметная область - компрессорный завод и обязательной, если предметная область - лингвистический институт.
- ассоциативность (степень, мощность) - различают связи 1 : 1, 1 : М, N : M.
Связь 1 : 1 - это такая, при которой каждой сущности понятия А соответствует только одна сущность понятия В, например: СТУДЕНТ - АДРЕСНЫЕ ДАННЫЕ.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
