



Связь 1 : М - это такая, при которой каждой сущности понятия А соответствует несколько (или 0) сущностей понятия В, например: ГРУППА -> СТУДЕНТ.
Связь N : M - это такая, при которой каждой сущности понятия А соответствует несколько (или 0) сущностей понятия В и наоборот, например: СТУДЕНТ <-> ПРЕПОДАВАТЕЛЬ.
Операции над единицами информации
Связи (отношения) между понятиями возникают в результате осмысления человеком задач реального мира. Основной механизм познания мира - это абстрагирование, которое состоит в выделении существенных и игнорировании не существенных свойств и связей. Оно позволяет разбить задачу на более простые подзадачи и упорядочивает наши знания о реальном мире.
Различают три основных типа абстрагирования и соответственно три вида операций над понятиями: агрегация, обобщение, ассоциация. Соответственно обратные логические операции над понятиями - это декомпозиция, специализация и индивидуализация.
Агрегация - это метод абстрагирования, при котором понятие - агрегат связано с другими понятиями, как целое связано с частями. Декомпозиция - это деление сложного понятия на компоненты.
Свойства агрегата - это совокупность свойств компонентов. Обычно составные части агрегата имеют совершенно разный набор свойств. Например, понятия ОБОРУДОВАНИЕ, АУДИТОРИЯ, СОТРУДНИКИ, ДИСЦИПЛИНЫ являются компонентами понятия КАФЕДРА. КАФЕДРА представляет собой понятие - агрегат.
На ER - диаграмме компоненты и агрегат изображаются прямоугольниками. Агрегат связан с компонентами связями типа "имеет / входит в" .
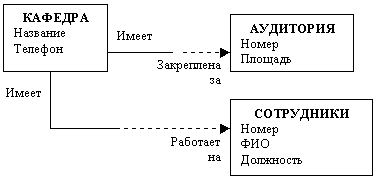
Рис. Графическое представление агрегата. Агрегат КАФЕДРА состоит из двух компонентов: АУДИТОРИЯ и СОТРУДНИКИ.
Обобщение - это метод абстрагирования, при котором обобщенное понятие связано с другими понятиями отношением “род - вид”, специализация - операция обратная обобщению. Например, обобщенное понятие - УЧАЩИЕСЯ может быть разделено на категории СТУДЕНТЫ, ШКОЛЬНИКИ, АСПИРАНТЫ.
Категории обычно имеют много общих свойств, но некоторые свойства у них различны. Свойства обобщенного понятия представляют собой перечень общих свойств категорий, но могут включать и дополнительные свойства по сравнению с исходными, чаще всего это такие свойства, как Среднее значение, Сумма и т. п. На ER - диаграмме категории изображаются треугольниками, а обобщенное понятие - прямоугольником, который соединен с категориями связями типа "является видом…( is kind of..)".
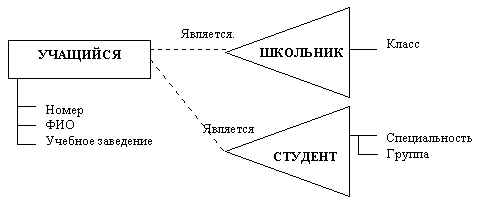
Рис. Графическое представление обобщенного понятия
Ассоциация - это такая логическая операция, которая устанавливает связи между конкретными сущностями разных понятий. Индивидуализация - это независимое рассмотрение связанных ассоциацией понятий. Обычно ассоциативные связи возникают в ходе реальных экономических процессов (бизнес - процессов). Например - понятия СТУДЕНТ, ПРЕПОДАВАТЕЛЬ, ДИСЦИПЛИНА ассоциируются с понятием ЧТЕНИЕ ЛЕКЦИЙ или СДАЧА ЭКЗАМЕНА. Понятия ТОВАР, МАГАЗИН, ПРОДАВЕЦ связаны отношением ПРОДАЖИ. Чаще всего свойства ассоциации соответствуют реквизитам экономического документа, в котором отражается результат соответствующего
бизнес - процесса, например, свойствами понятия ПРОДАЖИ могут быть такие реквизиты товарного и кассового чека, как дата продажи, номер документа, сумма.
На ER-диаграмме ассоциация может отображаться по-разному (рис. ):
A. В виде понятия, которое изображается ромбом(или  ), который соединен линиями со связанными понятиями.
), который соединен линиями со связанными понятиями.
B. В виде множества бинарных связей между простыми понятиями.
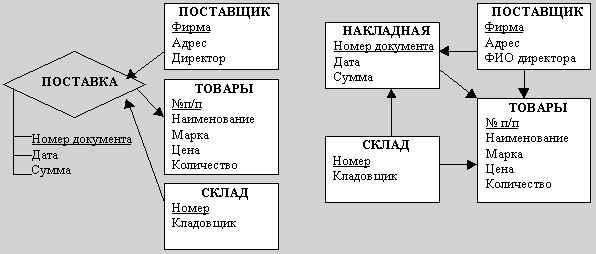
а) б)
Рис. Графическое представление ассоциации
Вариант А применяется обычно в двух случаях: если ассоциация соответствует процессу, который сопровождается составлением документов, реквизиты которых не отображены в виде свойств других понятий, либо если процесс соединяет более двух понятий.
ER - модели широко применяются как при ручном, так и при автоматизированном проектировании баз данных. При этом в некоторых системах, например, в системе IDEF, отсутствуют сложные понятия (агрегаты, ассоциации, обобщенные понятия), они заменяются связями. В разных системах применяются различные обозначения мощности связей и классов членства (обязательности связи) и т. д.
В заключение приведем рекомендуемый порядок построения ER-модели:
1. В каждом внешнем представлении выявить понятия и их свойства, исходя из анализа экономических документов. Их должно быть не более 6-7 в каждом представлении.
2. Обозначить понятия именами, которые должны быть краткими, отражать смысл и быть привычными для пользователя.
3. Выбрать ключевое свойство (свойства). Если такого нет, то вводят условное свойство “Порядковый №”.
4. Выявить связи между понятиями и сущностями.
a. Найти общие свойства понятий (обобщение);
b. Рассмотреть все пары понятий и определить ассоциативные связи;
c. Определить степень каждой связи.
d. Записать формулы расчета, связывающие вычисляемые свойства.
5. Объеденить модели, построенные для разных внешних представлений. Объединение ведут по 2-4 модели за один шаг, получая более сложные объекты и устраняя противоречия (например, разные наименования одних свойств и одинаковые - для разных понятий).
Задача построения модели ПО осложняется тем обстоятельством, что деление информации на свойства, понятия и связи условно, и один и тот же элемент информации можно описать по-разному. Например, информацию о преподавателе можно рассматривать как понятие, а можно и как свойство понятия ДИСЦИПЛИНА; любое ассоциированное понятие можно рассматривать как связь между несколькими понятиями. Принятие конкретного решения зависит от специфики предметной области и применяемых средств автоматизации проектирования.
Пример построения ER- модели
В качестве предметной области рассмотрим видеотеку. Детализируя диаграмму потоков данных, для каждого из 4-х основных процессов мы получили 4 хранилища данных: Члены видеотеки, Фильмы, Аренда и Поставщики. В ER - модели им будут соответствовать 4 одноименных понятия: Определим структуру каждого понятия, принимая во внимание реквизиты документов, которые обрабатываются в видеотеке: учетные карточки членов видеотеки, карточки учета фильмов, справочник поставщиков фильмов и журнал учета аренды фильмов. Свойства понятий сведем в таблицу:
Понятие | Свойства | Понятие | Свойства |
Члены видеотеки | ФИО Адрес Телефон Интересы | Фильмы | № по каталогу Название Тип (тематика) Страна-производитель Год выпуска Анонс Цена Количество лент |
Поставщики | Фирма Адрес Телефон Расчетный счет К кому обращаться | Аренда | № п/п Дата выдачи Отметка о возврате Фильм ФИО клиента |
Рассмотрим ассоциативные связи между понятиями, которые соответствуют информационным процессам.
A. В процессе учета членов видеотеки при регистрации нового члена необходимо убедиться, не был ли он записан раньше, не является ли должником. При исключении из членов следует проверить, вернул ли клиент все арендованные фильмы. Данный процесс использует информацию из понятий Члены и Аренда (рис. а). Линия со стрелкой отображает связь между понятиями типа "один ко многим", например, каждому члену видеотеки может соответствовать много записей в журнале аренды, но каждой записи в журнале соответствует только один конкретный клиент. При регистрации каждого нового клиента нужно проверить все карточки о членах видеотеки, поэтому на диаграмме показана рекурсивная связь.
B. При выдаче фильмов в аренду регистратор должен проверить, является ли клиент членом видеотеки, не числятся ли за ним несданные фильмы, затем в журнал аренды заносятся сведения об аренде фильма, а количество имеющихся лент уменьшается на 1. При возврате фильмов следует в журнале внести пометку о возврате, а количество имеющихся в наличии лент данного фильма увеличить на 1. Кроме того, регистратор может предложить клиентам справки о имеющихся в наличии фильмах. Соответствующая диаграмма показана на рис. б.
C. Процесс "Учет поставщиков" соединяет понятия Фильмы и Поставщики (рис. 3.6в) с помощью ассоциированного понятия "Поставки".
D. Управление фильмотекой заключается в периодическом предоставлении руководству отчетов об имеющихся фильмах и о ходе их аренды, поэтому данный процесс соединяет понятия "Фильмы" и "Аренда" (рис. 3.6г). Содержание отчетов отображает простое понятие "Отчеты начальству".
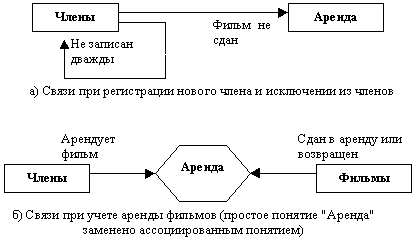
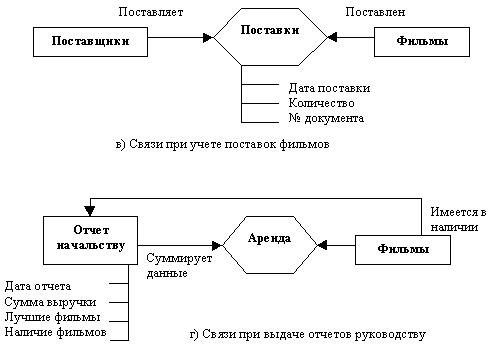
Рис. Построение фрагментов ER-модели при анализе информационных процессов
Обратите внимание, что ассоциированные понятия, как правило, имеют временное свойство (Дата поставки, Дата регистрации и т. п.) и ключевое свойство типа "Номер документа", так как они соответствуют информационным процессам, протекающим во времени.
В заключение объединим модели, полученные при анализе разных внешних представлений, устранив двусмысленности, дублирование атрибутов и рекурсивную связь.
![]()



|


|
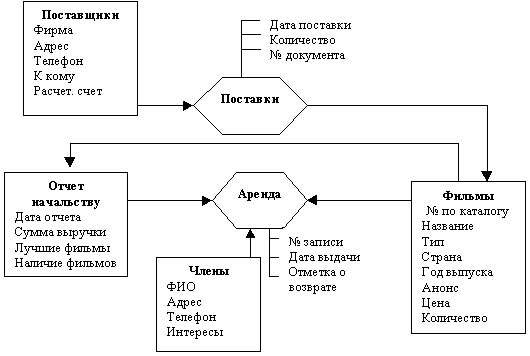
Рис. Объединенная диаграмма ER-модели предметной области "Видеотека"
Можно построить другой вариант ER- диаграммы, в которой ассоциированные понятия заменены непосредственными бинарными связями между объектами. Таким образом, варианты модели могут различаться. Следует выбрать тот вариант, который наиболее просто, понятно и полно отображает необходимую информацию о предметной области.
Лабораторная работа № 3. Классификация ЭИС
По режиму работы: пакетные, диалоговые и смешанные. Пакетные ЭИС работают в пакетном режиме: вначале данные накапливаются и формируется пакет данных, а затем пакет последовательно обрабатывается рядом программ. Недостаток этого режима - низкая оперативность принятия решений и обособленность пользователя от системы. Диалоговые ЭИС работают в режиме обмена сообщениями между пользователями и системой(например, система продажи авиабилетов). Этот режим особенно удобен, когда пользователь может выбирать перспективные варианты из числа предлагаемых системой.
По способу распределения вычислительных ресурсов: локальные и распределенные. Локальные ЭИС используют одну ЭВМ, а в распределенных ЭИС взаимодействуют несколько ЭВМ, связанных сетью. Отдельные узлы сети обычно территориально удалены друг от друга, решают разные задачи, но используют общую информационную базу.
По функциям: информационно - поисковые системы (ИПС), системы обработки данных (СОД) и автоматизированные системы управления (АСУ).
Системы обработки данных предназначены для решения задач расчета заработной платы, статистической отчетности, то есть таких, которые наряду с функциями ввода, выборки, коррекции информации выполняют математические расчеты без применения методов оптимизации. АСУ отличается от СОД тем, что сама выполняет управленческие функции по отношению к объекту. В АСУ включаются прикладные программы для принятия и оптимизации управленческих решений. Примером АСУ является система для оптимального управления запасами материалов на складе.
Информационно-поисковые системы предназначены для поиска требуемого документа или факта во множестве документов.
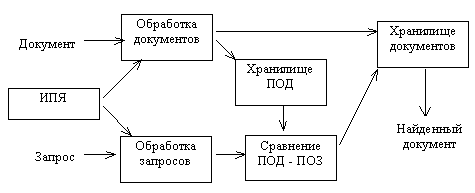
Рис. Схема ИПС
Поисковый образ документа (ПОД) получается в результате процесса индексирования, которое выполняется квалифицированными специалистами и состоит из двух этапов: выявление смысла документа и описание смысла на специальном информационно-поисковом языке(ИПЯ).
Запрос к ИПС описывается также на этом языке. Поиск документа состоит в сравнении множества хранящихся в системе ПОД и текущего ПОЗ, в результате чего пользователю выдается требуемый документ или отказ. Различают два режима работы ИПС: текущее информирование пользователей о новых поступлениях и ретроспективный поиск по разовым запросам.
По концепции построения ЭИС: файловые системы, автоматизированные банки данных (АБД), интеллектуальные банки данных (банки знаний) и хранилища данных.
Информационное обеспечение ЭИС первого типа построено в виде файловых систем. В современных ЭВМ операционная система берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным. Программное обеспечение ЭИС напрямую использует функции ОС для работы с файлами. Файловые системы обычно обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию прикладным программам. В таких системах сложно решить проблемы согласования данных в разных файлах, коллективного доступа к данным, модификации структуры данных.
Банком данных называют систему специальным образом организованных баз данных, программных, технических, языковых и организационно – методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
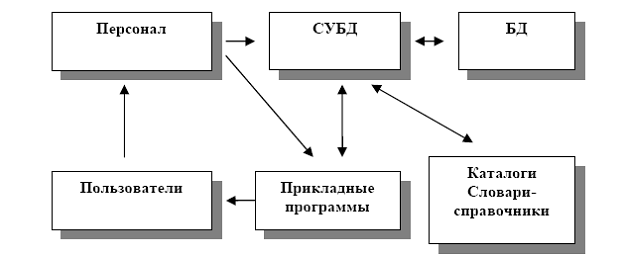
Рис. Структура банка данных
В отличие от файловых систем, структура базы данных меньше зависит от прикладных программ, а все функции по работе с БД сосредоточены в специальном компоненте – системе управления базами данных (СУБД), которая играет центральную роль в функционировании банка данных, так как обеспечивает связь прикладных программ и пользователей с данными. Сведения о структуре БД сосредоточены в словаре-справочнике (репозитории)АБД, этот вид информации называется метаинформацией. В состав метаинформации входит семантическая информация, физические характеристики данных и информация об их использовании. С помощью словарей данных автоматизируется процесс использования метаинформации в ЭИС.
Интеллектуальный банк данных (ИБД) – это сравнительно новый способ построения ЭИС, при котором информация о предметной области условно делится между двумя базами.
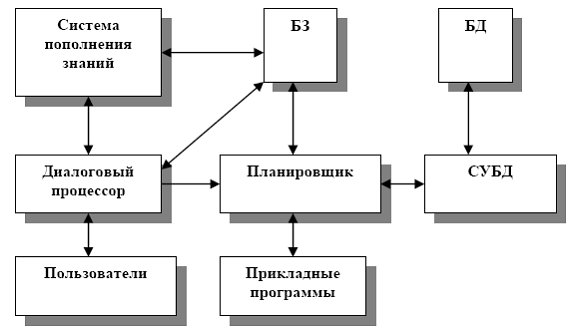
Рис. Структура банка знаний.
База данных содержит сведения о количественных и качественных характеристиках конкретных объектов. База знаний содержит сведения о закономерностях в ПО, позволяющие выводить новые факты из имеющихся в БД; метаинформацию; сведения о структуре предметной области; сведения, обеспечивающие понимание запроса и синтез ответа.
Диалоговый процессор предназначен для понимания смысла запроса и его перевода в термины знаний, заложенных в БЗ. Планировщик преобразует полученный запрос в рабочую программу, составляя ее из модулей, имеющихся в БЗ. Подсистема пополнения знаний позволяет ЭИС обучаться.
Если в традиционном банке данных знания о предметной области заложены программистом в каждую прикладную программу, а также в структуру БД, то в интеллектуальном банке данных они хранятся в базе знаний и отделены от прикладных программ. В отличие от данных, знания активны: на их основе формируются цели и выбираются способы их достижения. Например, ИБД в системе складского учета может автоматически реагировать на такое событие, как уменьшение количества деталей на складе до критической нормы, при этом ИБД без участия пользователя генерирует документы для заказа этих деталей и отправляет их по электронной почте поставщику.
Другое характерное отличие знаний отданных - связность, причем знания отражают как структурные взаимосвязи между объектами предметной области, так и вызванные конкретными бизнес - процессами, например такие связи, как“происходит одновременно”,“следует из...”, "если - то" идр.
Наконец, существенную роль в ИБД играет форма представления информации для пользователя: она должна быть как можно ближе к естественным для человека способам обмена данными(профессиональный естественный язык, речевой ввод / вывод, графическая форма).
В настоящее время в корпоративных базах данных накоплены гигантские объемы информации, однако она недостаточно эффективно используется в процессе управления бизнесом, поэтому бурно развивается новая форма построения ЭИС - склады (хранилища) данных.
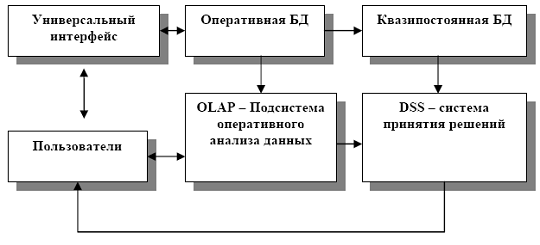
Рис. Структура хранилища данных
Хранилище данных представляет собой АБД, в котором база данных разделена на два компонента: оперативная БД хранит текущую информацию, квазипостоянная БД содержит исторические данные, например, в оперативной БД могут содержаться данные о продажах за текущий год, а в квазипостоянной БД хранятся систематизированные годовые отчеты и балансы за все время существования предприятия. Подсистема оперативного анализа данных позволяет эффективно и быстро анализировать текущую информацию. Подсистема принятия решений пользуется обобщенной и исторической информацией, применяет методы логического вывода. Для общения с пользователем служит универсальный интерфейс.
Выбор того или иного класса ЭИС зависит от ее назначения, конкретных условий применения и экономических критериев
Лабораторная работа № 4. Семантика предметных областей в экономике
Представление знаний зависит от того, какая модель для этого используется. К моделям предъявляют следующие требования:
- формальность представления, ясность и простота, которые влияют на сложность программной реализации модели;
- дедуктивные возможности (возможности получения новых знаний) определяют правильность и непротиворечивость базы знаний и время получения ответов на запросы;
- реализация механизмов абстракции важна для понимания больших объемов информации и объединения представлений разных пользователей;
- возможность преобразования на естественный язык, в графическую форму, в таблицу и наоборот, что имеет значение для создания удобного пользовательского интерфейса, который обеспечивает отсутствие искажений и потерь информации при преобразованиях ее формы.
Ранее мы рассмотрели неформальную модель представления знаний “сущность - связь”. Рассмотрим еще три модели: продукционную, фреймовую модель и семантическую сеть. Каждая из моделей имеет свои достоинства и недостатки.

1. 5.1. Продукционная модель
На использовании данной модели основаны многие современные экспертные системы, например, справочные средства текстовых и графических редакторов.
Модель основана на логике предикатов или продукционных правилах, которые описывают знания в форме "если - то". Под продукцией понимают выражение следующего вида:
Q (i); P, A=>B, N,
где i - имя продукции, например, "продажа товара",
Р - логическое выражение, описывающее условие применимости продукции, например, условием продукции "продажа товара" может быть "Товар имеется на складе";
N - описание постусловий продукции, то есть действий, которые выполняются после реализации В.
A=>B - ядро продукции, где А называют посылкой, а В - выводом или целью. Правило А => В читается как "Если справедливо А, то верно В" или "если выполняется условие А, то выполнить действие В".
Посылка “ЕСЛИ” содержит обычно один или несколько фактов, объединенных логической операцией “И”; вывод “ТО” представляет собой новый факт.
Экспертные системы, которые базируются на продукциях, состоят из 3-х компонентов: базы данных, базы правил и интерпретатора:
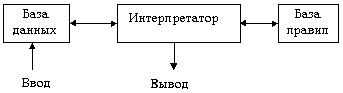
Рис. 5.1. Структура продукционной экспертной системы
БД хранит исходные факты и результаты выводов. Правила содержатся в базе правил. Интерпретатор (механизм логического вывода) соединяет факты и правила, чтобы получить новые факты; работа интерпретатора не зависит от того, что он интерпретирует, - этим логическое программирование принципиально отличается от обычного. Имеются языки логического программирования, например, ПРОЛОГ.
Различают прямой и обратный вывод.
В прямом выводе исходной точкой являются факты, которые содержатся в БД. Из БД выбирается факт и подставляется в очередное правило. Если посылка истинна, то получается новый факт, который заносится в БД либо выполняется какое-то действие. Процесс заканчивается, когда очередной факт подставлен во все правила. Не все правила приводят к появлению новых фактов.
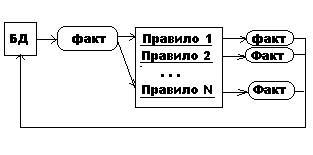
Рис. Схема прямого вывода
Обратный вывод начинается от поставленной цели. Этот факт (гипотеза) подставляется в заключительную часть очередного правила, а посылка этого правила принимается за новую цель - гипотезу. Если посылка имеется в БД, то процесс заканчивается.
Нельзя сказать, какой из способов вывода лучше, так как это зависит от решаемой проблемы. В системах с обратным выводом можно часть правил исключить из перебора и тем самым сократить время вывода, поэтому такие системы более распространены.
Пример. Пусть имеются факты и правило:
Факт 1: Иванов - служащий
Факт 2 : Петров - начальник Иванова
Факт 3: Сидоров - начальник Петрова
Правило: Если X начальник для Y, то Х - служащий.
Прямой вывод: подставляем Факт 1 в Правило: Факт не подходит,
Факт 2: Х = Петров, Y= Иванов, получаем вывод: Петров - служащий,
Факт 3: аналогично получаем вывод: Сидоров - служащий.
Обратный вывод: Выдвигаем гипотезу: Сидоров - служащий и подставляем этот факт в правило:
Если Сидоров начальник для Y, то Сидоров служащий.
Ищем в БД левую часть правила - факт “Сидоров начальник для Y”. Путем перебора находим, что подходит факт 3 (при этом переменная Y принимает значение "Петров"). Значит, выдвинутая гипотеза верна.
Достоинства продукционной модели:
1. Простота создания и описания правил,
2. Простота механизмов выводов,
3. Возможность описания модели на языке логического программирования ПРОЛОГ.
Недостатки модели:
Правила могут быть противоречивы и эти противоречия может устранить только человек - разработчик модели, что затруднительно при решении больших задач.
Семантические сети
Идея модели состоит в том, чтобы представить в формальном виде предложения естественного языка. Семантическая сеть представляет собой ориентированный граф, в котором понятия предметной области моделируются вершинами графа, а связи между ними - дугами. Выделяют три вида вершин сети: конкретные значения свойств сущностей, понятия (объекты) предметной области, ситуации.
Группа взаимосвязанных понятий и утверждение об их истинности называется ситуацией. Ситуации являются основной категорией для описания предметной области. Связь между понятиями отражает простейший факт. Более сложные утверждения, которые в естественном языке составляют отдельное предложение, соответствуют подграфу сети. Дуги сети делятся на три типа: сущность - сущность, сущность - понятие, понятие - понятие.
В сети каждая связь (дуга) имеет имя, которое выражает роль понятия в данной ситуации. В отличие от других моделей, одна и та же сущность может быть связана ролевыми отношениями с несколькими понятиями. Например, сущность в разных ситуациях играет разные роли: Член профсоюза, Автор книги, Преподаватель, Садовод, Налогоплательщик, Автолюбитель и т. д.
Наиболее типичные роли:
- АГЕНТ - инициатор действия
- ОБЪЕКТ - кто (что) подвергается действию
- ИСТОЧНИК - местонахождение объекта до действия:
- ПРИЕМНИК - куда попал объект после совершения действия,
- ВРЕМЯ - когда происходит действие,
- МЕСТО - где происходит действие
- ЦЕЛЬ - зачем производится действие.
Пример. Ситуация описывается предложением: Шигина читает лекции по дисциплине ТЭИС для студентов потока 98Э в 5 семестре в аудитории 227.
Построим семантическую сеть, описывающую данную ситуацию.
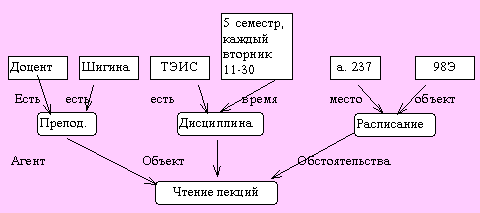
Рис. 5.3. Пример семантической сети
Все вершины в данной сети соответствуют конкретным понятиям.
В естественном языке часто встречаются предложения типа "Все волки серые". Таким связям между понятиями в математике соответствует квантор всеобщности. В семантической сети для отображения такой логической связи вводится вершина-переменная. Например, на рис. 5.4 представлен граф утверждения "В каждой группе есть староста и куратор".
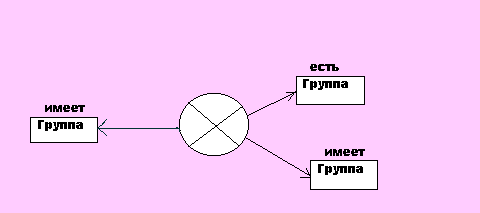
Рис. Сеть с переменной вершиной (обозначена кружком)
Для представления логических операций в семантических сетях используют рамки, охватывающие соответствующие дуги. Для операции "И" рамка не указывается, для операций "ИЛИ", "НЕ" и "Если -То" внутри рамки пишут название операции. Например, на рис. 5.5-а показана сеть для утверждения "Иванов учится в институте или работает на заводе, рис. 5.5-б изображает сеть для утверждения "Все студенты ПТИ специальности 0719 выпускаются кафедрой АИСТ".
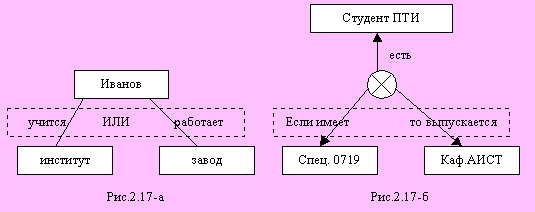
Рис. Представление логических операций
Особенность семантической сети состоит в том, что эта модель не имеет механизма вывода новых фактов. Для поиска ответов в семантической сети используют следующие методы:
A. Установление соответствия сети фактов и целевой сети;
B. Наследование свойств тех множеств, в которые входит понятие.
С помощью этих методов можно определить свойства понятий или наоборот, найти объект по заданным свойствам.
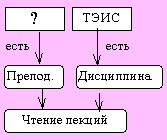
Идея метода А состоит в следующем. Для каждого запроса к базе знаний строится своя семантическая сеть, в которой искомые данные моделируются пустыми вершинами сети. Построенная сеть сравнивается с общей моделью предметной области, хранящейся в БЗ. При этом “пустые вершины” принимают конкретные значения.
Например, рассмотрим запрос: “Кто читает лекции по ТЭИС?” Сначала строим граф для заданного запроса (рис. 5.6), затем сравниваем этот граф с сетью (рис.5.3), начиная с вершин, моделирующих ситуацию (ситуация => понятия => сущность). В результате находим ответ: Шигина. |
|
Достоинства модели: наглядность и понятность, легкость отображения отношений абстракции и единство представления для всех видов знаний, возможность преобразования в естественный язык и графическую форму, наличие ассоциативных связей допускает целенаправленный поиск, в отличие от перебора в продукционной модели..
Недостатки модели: ограниченные возможности логического вывода; трудоемкость перебора вариантов для вывода при больших размерностях задач, отсутствие в настоящее время формального аппарата для описания и представления модели.
Фреймовая модель
Фреймовая модель была предложена М. Мински в 1975 году. Фрейм - это некоторая “пустая рамка ”, структура для представления знаний, которая при заполнении конкретными значениями превращается в описание конкретного факта, события или ситуации. Центральная идея данного подхода состоит в отказе от формирования модели внешнего мира на основе разрозненных фактов и понятий. Фрейм должен строиться как модель стереотипной, часто повторяющейся ситуации или группы сходных ситуаций.
Модель знаний о предметной области представляет собой сеть фреймов. Основной тип связи между фреймами - связи по иерархии. Обычно верхний уровень иерархии (название ситуации, название действия) заполнен знаниями, а нижний уровень не полностью определен и уточняется, когда фрейм применяют к конкретной обстановке. Группа фреймов может объединяться в систему, в которой каждый фрейм играет свою роль. Систематизация знаний, то есть построение модели, возлагается на человека.
Основная структурная единица фрейма называется слотом, который описывает некоторое действие, понятие или связь.
Параметрами слота являются уникальное имя, значение, тип данных и наследование.
Наследование определяет, какую информацию наследует данный слот из одноименного слота в фрейме верхнего уровня.
Тип данных слота может принимать следующие значения: указатель на фрейм верхнего уровня (для иерархической взаимосвязи фреймов), переменная, текст, список и процедура. Обратите внимание, что в отличие от других моделей, фрейм может включать в себя активные знания (процедуры).
Пример. Рассмотрим сеть фреймов, представляющую знания о студентах
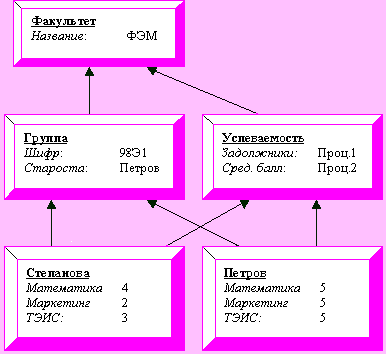
Рис. Пример сети фреймов
Фреймы "Степанова", "Петров" хранят уникальную информацию для каждого студента. Более общая информация о группе и факультете собрана в отдельных фреймах и может наследоваться. Процесс наследования состоит в получении данных при движении вверх по иерархии фреймов, например, следуя вверх по связи "Степанова" - "группа", можно узнать, что старостой группы, в которой учится Степанова, является Петров.
Между фреймами установлены связи типа "является частью", например, студенческая группа является частью факультета. Связь направлена к фрейму более высокого уровня.
Наряду с декларативными знаниями фрейм "Успеваемость" содержит процедурные знания - процедуры определения списка задолжников ("Проц.1") и расчета среднего балла ("Проц.2").
Различают два вида присоединенных процедур:
1. "демоны", которые автоматически активизируются при изменении данных в фрейме (например, как только Степанова сдает экзамен по маркетингу, она автоматически исключается из списка задолжников);
2. "слуги", которые активизируются по запросу пользователя (например, - "Проц.2" - расчет итогов в конце сессии).
Дополнительное новшество фреймовой модели по сравнению с другими моделями - наличие значений "по умолчанию", которые изначально приписываются слотам и могут в дальнейшем уточняться. Это помогает анализировать ситуации без их детального описания.
Запросы к базе знаний в данной модели реализуются следующим образом. Первоначально задаются значения слотов исходных данных, это может привести к активизации слотов-процедур, которые “генерируют” новые данные, в том числе могут задавать пользователю уточняющие вопросы, когда данных для ответа не хватает. В результате пользователю выдаются найденные значения искомых слотов.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
