



Этапы анализа требований и проектирования, являющиеся наиболее трудноформализуемыми, как раз и явились теми, где CASE - технологии получили наибольшее распространение. Основой для этих этапов в большинстве разработанных CASE-средствах являются методологии структурного анализа и проектирования.
1.7.2. Понятие о структурном анализе
Структурным анализом (структурным подходом) принято называть метод исследования системы, основанный на представлении ее в виде иерархии взаимосвязанных элементов. Обычно число элементов на каждом уровне иерархии ограничено (от 3 до 6 – 7); описание каждого уровня включает в себя только существенные для этого уровня элементы; используются строгие формальные правила записей и изображения системы и ее элементов.
Наиболее распространенные методологии структурного подхода базируются на следующих принципах [19]:
q решение сложных проблем путем их разбиения на множество меньших независимых задач, легких для понимания и решения;
q иерархическое упорядочение или организация составных частей ПО в иерархические древовидные структуры с добавлением новых деталей на каждом уровне;
q абстрагирование, т. е. выделение существенных аспектов системы и отбрасывание несущественных;
q непротиворечивость, которая требует обоснованности и согласованности элементов.
Ранее уже отмечалось, что любая система может иметь множество структур, отличающихся признаком выделения элементов (см. п. 1.1). Структурный анализ информационных систем предполагает следующие три вида анализа (и, следовательно, три типа структурных моделей): анализ функций системы; анализ данных; анализ поведения системы.

Для анализа функций системы (функционального моделирования) используются структурные модели типа диаграммы потоков данных (DFD — Data Flow Diagrams), для анализа данных (информационное моделирование) — модели типа диаграммы «сущность - связь» (ERD — Entity - Relationship Diagrams), для анализа поведения систем (событийное моделирование) — модели типа диаграммы переходов состояний (STD —State Transition Diagrams). Ниже мы опишем способы представления этих моделей.
1.7.3. Состав средств CASE-технологий
Большинство CASE-средств характеризуется сочетанием методологии, методов, нотаций и средств поддержки.
Методология — это последовательность выполнения работ, правил выбора методов и решений на разных этапах разработки.
Методы — это систематические процедуры построения моделей проектируемой системы (например, построения моделей данных, потоков и т. д.).
Нотации — это установленные способы (обозначения), используемые для описания элементов системы, т. е. графы, таблицы, блок схемы, формальные и естественные языки.
Средства поддержки — это инструментарий для реализации методов, например, поддержка создания и редактирования графического проекта в интерактивном режиме и др.
CASE - пакет (CASE - средства) может содержать следующие четыре основных функциональных компонента [18]:
средства централизованного хранения всей информации о проектируемом ПО в течении всего жизненного цикла ПО (это так называемый репозитарий); средства ввода данных в репозитарий; средства анализа, проектирования и разработки ПО, обеспечивающие планирование и анализ различных описаний, а также их преобразование в процессе разработки; средства вывода, предназначенные для документирования проекта.
Все вышеперечисленные компоненты должны поддерживать графические модели, контролировать ошибки, поддерживать репозитарий.
1.7.4. SADT— технология структурного анализа и проектирования
SADT (Structured Analysis and Design Techniqe) — одна из наиболее распространенных технологий анализа и проектирования систем, разработана Дугласом Россом (США) в 1973 г.
Полная методология SADT заключается в построении множества моделей для описания сложной системы. Основным рабочим элементом при моделировании является диаграмма. Модель SADT объединяет и организует диаграммы в иерархические древовидные структуры, при этом, чем выше уровень диаграммы, тем она менее детализирована. Наибольшее распространение получили только функциональные модели SADT-технологий, поддерживаемые стандартом IDEFO, разработанным Министерством обороны США [IDEF — аббревиатура слов Integrated DEFinition, интегральная спецификация (описание)]. Ниже мы опишем IDEFO-технологию как один из вариантов SADT-технологий.
1.7.4.1. Функциональное моделирование. IDEF0-модель
В IDEF0-технологии проектируемая система представляется иерархически упорядоченным множеством функциональных диаграмм, отображающих на каждом уровне выполняемые функции и информационные связи между функциями, а также между функцией и внешней средой. В терминах IDEF0 процедура представляется в виде комбинации функциональных блоков и дуг. Блоки используются для представления функций, составляющих процедуру, и сопровождаются текстами на естественном языке. Дуги представляют множество объектов, таких как физические объекты, информация или действия, с помощью которых осуществляются связи между функциональными блоками.
Место соединения дуги с блоком определяет тип интерфейса. Управляющие, регламентирующие или нормативные данные входят в блок сверху. Исходные данные (запросы, документы), которые обрабатываются при выполнении данной функции, указываются с левой стороны блока. Результаты выполнения функции отображаются с правой стороны. Механизм или исполнитель, осуществляющий операцию, изображается дугой, входящей в блок снизу.
Функциональный блок преобразует входную информацию в выходную. Управление определяет, когда и как это преобразование может или должно произойти. Исполнитель (человек или автоматизированная система) непосредственно осуществляет это преобразование.
При необходимости описания функция может быть детализирована на диаграмме следующего (нижнего) уровня.
Каждая детальная диаграмма является декомпозицией блока из более общей диаграммы. Дуги, входящие в блок и выходящие из него на диаграмме верхнего уровня, те же, что и дуги, входящие в диаграмму нижнего уровня и выходящие из нее.
Если данные, представляемые этими дугами, не рассматриваются на данном уровне детализации, то на диаграмме используют особый тип дуг, называемых тоннельными. Такие дуги заключаются в скобки.
На рис. 1.5 дан пример контекстной диаграммы (диаграммы верхнего уровня) описания функции "Согласование приказа о приеме на работу".
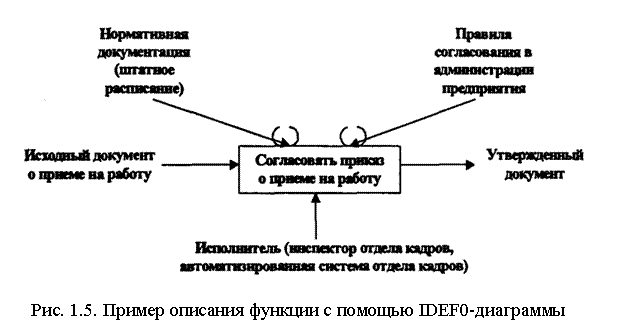 На рисунке 1.5 имеем:
На рисунке 1.5 имеем:
Вход: исходный документ о приеме на работу.
Управляющая
и нормативная
информация: штатное расписание; правила согласования приказа в администрации предприятия.
Выход: утвержденный документ
(приказ о приеме на работу).
Исполнитель: инспектор отдела кадров, автоматизированная система отдела кадров.
Технология IDEF0 не ограничивает количество уровней декомпозиции. Это дает возможность получить модель процедуры с требуемой степенью детализации.
IDEF0-технология поддерживается пакетами BPWin, Design/IDEF.
1.7.4.2. Пример построения функциональной модели диспетчера районов курсирования грузовых вагонов Дирекции совета по железнодорожному транспорту
Дирекция совета по железнодорожному транспорту (ЦСЖТ) дает разрешение на курсирование грузовых вагонов, являющихся собственностью предприятий, организаций и физических лиц, по путям общего пользования в пределах стран СНГ и Балтии (в межгосударственном сообщении).
Установлен следующий порядок выдачи разрешений:
1. Собственник, которому принадлежат вагоны, отправляет на свою дорогу приписки заявку на расширение района курсирования принадлежащих ему вагонов. Заявка содержит следующие показатели: наименование собственника; требуемый район курсирования; список номеров вагонов; род перевозимого груза.
2. В управление дороги заявку рассматривают и оформляют телеграмму-заявку на расширение района курсирования в ЦСЖТ.
3. При получении телеграммы-заявки в ЦСЖТ диспетчер районов курсирования должен:
· проверить ее корректность, т. е. проверить принадлежность номеров вагонов данному собственнику, технические характеристики вагонов, их соответствие роду перевозимого груза, а также признаки качества каждого вагона, определяющие возможность курсирования по путям общего пользования;
· составить телеграмму-заявку на согласование в адрес причастных железнодорожных администраций, в которой указать наименования собственника, номера вагонов, род груза, район курсирования, дорогу приписки вагона;
· согласовать требуемый район курсирования с причастными железнодорожными администрациями. Для этого диспетчер направляет телеграмму-заявку причастным железнодорожным администрациям; в течение установленного срока диспетчер должен получить ответ от всех причастных железнодорожных администраций, который содержит разрешение или отказ данным вагонам курсировать в районе;
· если от железнодорожной администрации пришел положительный ответ, оформить телеграмму-разрешение на расширение района курсирования в адрес дороги приписки данного собственника и телеграмму-сообщение о согласованных районах курсирования в адрес всех причастных железнодорожных администраций;
· после утверждения начальником ЦСЖТ телеграммы отправить по указанным адресам;
· как только телеграмме будет присвоен номер, можно формировать корректировочный файл, который направляется в информационно-технологический центр (ИТЦ) Главного вычислительного центра (ГВЦ) МПС России.
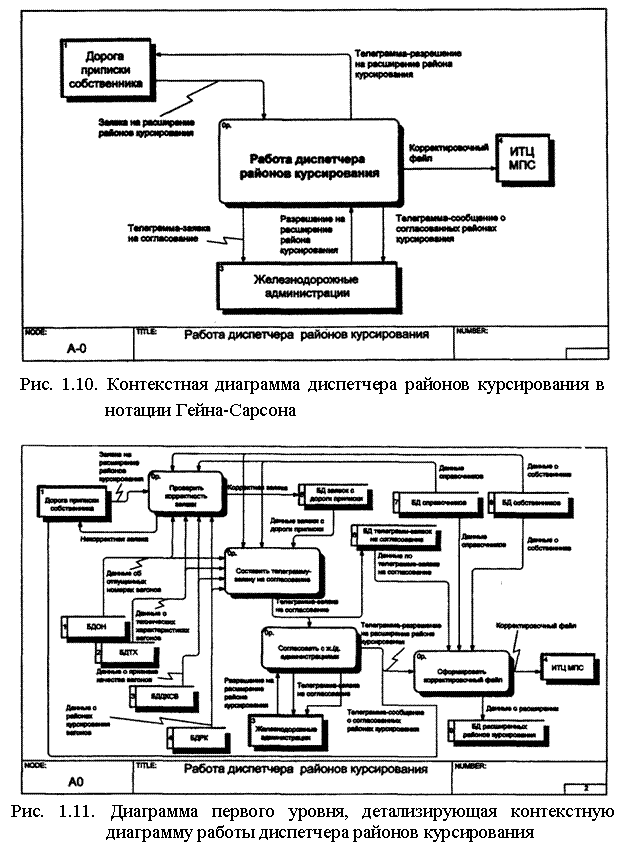
На рис. 1.6 приведена контекстная диаграмма диспетчера районов курсирования, выполненная в стандарте IDEF0 с помощью пакета BPWin в рамках работ по созданию автоматизированного рабочего места (АРМ) диспетчера районов курсирования. Диаграмма содержит одну операцию (активность), названную "Работа диспетчера районов курсирования".
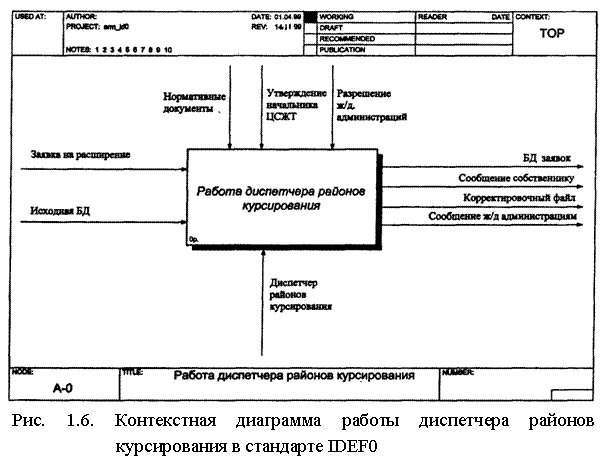
Стрелки, входящие в активность слева, указывают на входы операции (заявка на расширение, исходная база данных); стрелки справа, выходящие из активности, — это выходы операции (заявки, направляемые в базу данных заявок; сообщение собственнику; сообщения железнодорожным администрациям; корректировочный файл, направляемый в ИТЦ ГВЦ МПС); стрелки, входящие в активность сверху, указывают на необходимые для выполнения операции управляющие воздействия (утверждение текста телеграммы начальником ЦСЖТ, разрешения железнодорожных администраций) и нормативные сведения; стрелка, входящая снизу, определяет исполнителя операции (диспетчера районов курсирования).
На рис. 1.7. показана функциональная диаграмма следующего уровня, детализирующая контекстную диаграмму (см. рис. 4.6). Сохранены все потоки, которые были указаны на контекстной диаграмме. Активность контекстной диаграммы представлена четырьмя активностями второго уровня (дочерними процессами): проверить корректность заявки; составить телеграмму-заявку на согласование; согласовать с железнодорожными администрациями; сформировать корректировочный файл.
На этой диаграмме раскрыто содержание заявки на расширение районов курсирования.
Каждая операция этой диаграммы может быть детализирована в 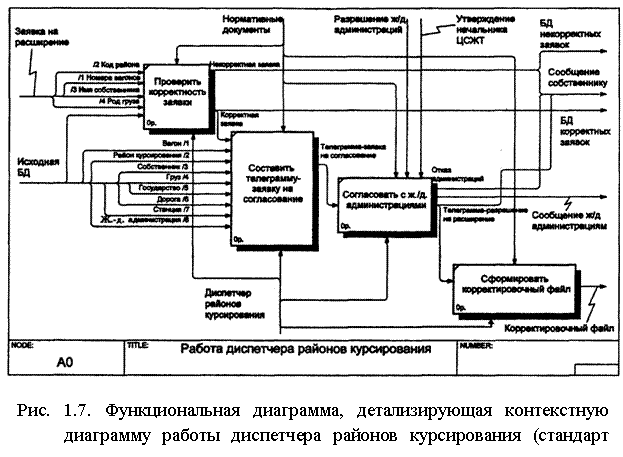 диаграммах следующих уровней.
диаграммах следующих уровней.
1.7.4.3. Информационное моделирование. IDEF1 - модель
При информационном моделировании в современных CASE-тех-нологиях используется аппарат диаграмм "сущность - связь" или ER-моделей, введенных Ченом в 1976 г. Диаграммы "сущность - связь" (ERD — Entiry Relationship Diagrams) обеспечивают стандартный способ определения данных и отношений между ними. Фактически с помощью ERD осуществляется детализация баз данных проектируемой системы, а также документируются сущности системы, способы их взаимодействия, включая идентификацию объектов (сущностей), свойств этих объектов (атрибутов) и их отношений с другими объектами (связей).
Объекты предметной области описываются совокупностью параметров или атрибутов; однотипные объекты описываются одним и тем же набором параметров и объединяются в множества или классы - "сущности". Сущность — это реальные или воображаемые объекты, имеющие существенное значение для рассматриваемой предметной области, информация о которых подлежит хранению. Конкретные объекты, входящие в класс, называются экземплярами.
Связь — это поименованная ассоциация между сущностями. Связь может существовать между разными сущностями или между сущностью и ею же самой (рекурсивная связь). Связь обычно именуется глаголом (состоит, руководит, имеет и т. д.). Иногда имя связи указывают на каждом ее конце. Связь между двумя сущностями характеризуется числом экземпляров каждой сущности, которые могут участвовать в связи. Так связь "один к одному" (1:1) указывает, что от каждой сущности в связи участвует не более одного экземпляра; связь "один ко многим" (1:М) указывает, что одному экземпляру первой сущности может соответствовать любое число экземпляров второй сущности. При этом каждый конец связи характеризуется:
-степенью (мощностью) связи — числом экземпляров сущности, которые могут связываться;
-обязательностью связи — возможностью отсутствия экземпляров сущности для связи. Степень и обязательность каждого конца связи определяют показатель, называемый кардинальностью связи. Этот показатель содержит две цифры: первая (0 или 1) указывает наименьшее, а вторая (1 или М) — наибольшее число экземпляров сущности, которые могут участвовать в связи. Если первая цифра "0" , то связь является необязательной (см. также раздел «Проектирование БД»). Например, обозначение (1,1) указывает на обязательную связь, в которой участвует один экземпляр сущности; (0,М) - необязательная связь, число экземпляров любое (т. е. 0,1, или много)и т. д.
Если связь между сущностями Х и Y такова, что наличие сущности Х зависит от наличия сущности Y, то сущность Х называют зависимой, а Y—независимой (сильной, правильной). Такую связь иногда определяют как связь между сущностью-родителем (независимая сущность) и сущностью-потомком (зависимая или дочерняя сущность)
Технология IDEF1 включает в себя набор правил, процедур построения и графического отображения информационной модели (IDEF1-модели)
IDEF1-модель содержит два основных компонента: диаграмму "сущность-связь" и диаграмму атрибутов, словари данных, содержащие смысловое значение каждого элемента модели, выраженное с помощью текста и обозначений, которые в совокупности точно определяют информацию, отображенную в модели.
Детализация сущности осуществляется с помощью диаграмм атрибутов, которые раскрывают ассоциированные с сущностью атрибуты.
Диаграмма атрибутов состоит из детализируемой сущности, соответствующих атрибутов и доменов, описывающих области значений атрибутов.
При построении ER-диаграмм используется следующая система обозначений. Сущности обозначают прямоугольниками, сверху записывается имя сущности, ниже вписываются перечни атрибутов. При этом атрибуты, составляющие первичный ключ1) сущности группируются в верхней части прямоугольника и отделяются горизонтальной чертой. Ключевые атрибуты родительской сущности входят в состав ключевых или неключевых атрибутов сущности-потомка (дочерней сущности). В первом случае связь называют идентифицирующей (экземпляры дочерней сущности идентифицируются через связь с родительской сущностью). Идентифицирующие связи обозначаются сплошными линиями, неидентифицирующие - штриховыми. Соединительные линии заканчиваются точкой со стороны дочерней сущности. Над линией записывается наименование связи (включает, одобряет, использует и т. д.). Дочерние сущности обозначаются прямоугольниками с закругленными углами, если связь этой сущности хотя бы с одной родительской является идентифицирующей. Для обозначения степени концов связи и обязательности связи (кардинальности связи) принята система символов, приведенная в табл. 1.7.
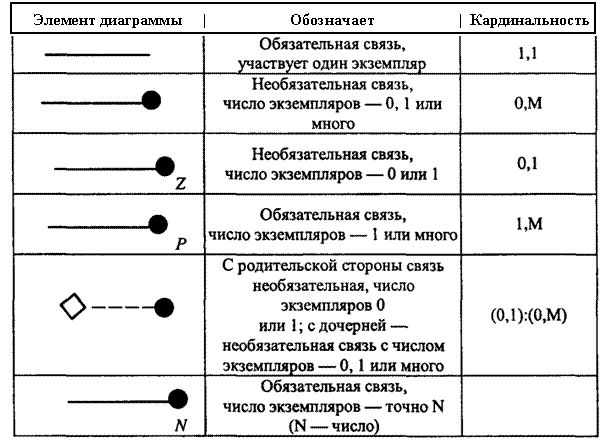 Таблица 1.7
Таблица 1.7
IDEF1 -модель можно считать завершенной, если выполнены следующие условия: каждая сущность полностью определена; каждая сущность может быть идентифицирована через ее атрибуты; все отношения (связи) между сущностями являются отношениями типа "один к одному" или "один ко многим"; сущность появляется в модели только один раз.
На рис. 1.8 приведен фрагмент ER-диаграммы диспетчера районов курсирования (см. п. 1.7.4.2.). На диаграмме представлены 7 сущностей из функциональной модели (см. рис.1.7): ВАГОН, СОБСТВЕННИК, ГОСУДАРСТВО, Ж.-Д. АДМИНИСТРАЦИЯ, РАЙОН КУР-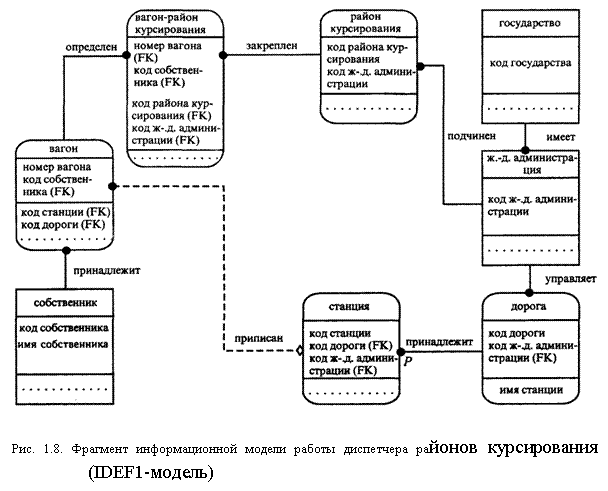 СИРОВАНИЯ, дорога, станция.
СИРОВАНИЯ, дорога, станция.
В прямоугольники, обозначающие сущности, вписаны наименования атрибутов, например, для сущности СОБСТВЕННИК — КОД СОБСТВЕННИКА и ИМЯ СОБСТВЕННИКА. Атрибут КОД СОБСТВЕННИКА — ключевой. Сущность СТАНЦИЯ имеет три ключевых атрибута (КОД СТАНЦИИ, КОД Ж.-Д. АДМИНИСТРАЦИИ и КОД ДОРОГИ), причем атрибуты КОД ДОРОГИ и КОД Ж.-Д. АДМИНИСТРАЦИИ являются ключевыми для родительской сущности ДОРОГА и поэтому снабжены указателем (FK).
На диаграмме рис. 1.8 имеется сущность ВАГОН-РАЙОН КУР-СИРОВАНИЯ, которой нет на функциональной схеме. Необходимость введения этой сущности связана с требованием, чтобы все связи были типа "один к одному" или "один ко многим". Рассмотрим связь сущностей ВАГОН и РАЙОН КУРСИРОВАНИЯ. Пусть N — число экземпляров вагона, а М — число районов курсирования. Тогда связь (отношение) между этими сущностями типа N:M (любой вагон может курсировать в любом районе и любой район курсирования допускать любое число вагонов). Чтобы преобразовать это отношение к типу "один ко многим", вводится дополнительная сущность ВАГОН-РАЙОН КУРСИРОВАНИЯ. Теперь каждому экземпляру вагона соответствует М экземпляров дочерней сущности ВАГОН-РАЙОН КУРСИРОВАНИЯ, а каждый экземпляр дочерней сущности ассоциирован только с одним экземпляром родительской сущности ВАГОН. Связь между сущностями ВАГОН и ВАГОН-РАЙОН КУРСИРОВАНИЯ относится к типу 1:М.
Разработка информационных моделей в различных средах (ERWin, Design2000, Design/IDEF и др.) включает в себя не только построение модели логического типа, к которому относится и IDEF1 - модель, но и ее преобразование в физическую модель (т. е. в совокупность баз данных).
1.7.4.4. Событийное (динамическое) моделирование. IDEF0 PN-модель
Событийное моделирование предназначено для анализа поведения системы или динамики информационного процесса, реализуемого проектируемой системой.
IDEF0 PN-модель представляет собой иерархическую сеть Петри с раскрашенными маркерами (см. гл. «Анализ информационных процессов»), в которой функциональная диаграмма верхнего уровня (контекстная диаграмма) IDEF0 — модели трансформируется в корневой компонент иерархической сети Петри, а нижестоящие функциональные диаграммы — в соответствующие компоненты сети Петри. IDEF0 PN - модель отображает реальный (протекающий во времени и в пространстве) процесс функционирования моделируемой системы. Взаимодействие системы и информационной среды описывается интерфейсом IDEF0 PN и IDEF1 в виде совокупности условий и правил, отнесенных к переходам IDEF0 РМ-модели и выполняемых над компонентами IDEF1 - модели.
Процедура моделирования функционирования системы, основанная на использовании перечисленных моделей, включает в себя четыре взаимосвязанных этапа.
На первом этапе строятся параллельно, взаимно дополняя друг друга, IDEF0- и IDEF1-модели. Взаимосвязь между ними проявляется в том, что обозначения на управляющих, входных и выходных стрелках IDEF0- модели соответствует именам сущностей, указанным в IDEF1-модели.
На втором этапе выполняется детализация описанных в IDEF0-модели функций, в результате чего определяется иерархия функций. Диаграммы нижестоящего уровня "раскрывают" (детализируют) блок на "родительской" диаграмме" IDEF0-модели.
На третьем этапе IDEF0-модель преобразуется в IDEF0 PN-модель следующим образом. Каждая IDEF0-диаграмма трансформируется в сеть Петри (СП). Позиция СП соответствует в IDEFO-модели функциям, а переходы отображают передачу активности от одних функций к другим. Условия активизации функций изображаются раскрашенными маркерами, помещаемыми в позиции СП. Маркеры перемещаются из позиции в позицию по определенным правилам вследствие срабатывания переходов. Перемещение маркера отображает динамику моделируемого процесса. Сеть Петри нижестоящего уровня раскрывает позицию родительской сети (подобно IDEFO-модели).
На четвертом этапе определяются правила срабатывания переходов иерархической сети Петри в зависимости от значений, которые принимают атрибуты сущностей модели ЮЕП. Для этого составляется таблица, содержащая для каждого перехода сети Петри разрешающее условие, временное условие и продукционные правила (типа "если - то"), в соответствии с которым осуществляется коррекция информационной модели.
Фактически IDEF0-, IDEF1-, IDEF0 PN-модели являются компонентами интегрированной технологии разработки программного обеспечения: статические IDEF0-модели преобразуются в динамическую модель IDEF0 PN, которая затем исполняется в различных режимах с целью получения динамических (поведенческих) характеристик проектируемой системы.
1.7.5. Методология структурного анализа Йодана де Марко и Гейна-Сарсона
1.7.5.1. Функциональное моделирование. Подход Гейна-Сарсона
Для решения задачи функционального моделирования на базе методов структурного анализа и проектирования широко применяются DFD-модели (Data Flow Diagrams — диаграммы потоков данных). Автоматизированная поддержка DFD-моделей существует в большинстве CASE-пакетов. DFD-модель создавалась как средство проектирования именно информационных систем, тогда как технология SADT была ориентирована на проектирование систем вообще.
Методология структурного анализа и проектирования базируется на интеграции следующих средств:
DFD — диаграмм потоков данных, которые являются графическими иерархическими спецификациями (описаниями) систем с позиций потоков данных; в DFD-моделях используются четыре графических символа, и представляющих собой потоки данных, процессы преобразования входных потоков данных в выходные, внешние источники и получатели данных, а также файлы и базы (накопители) данных (БД);
словарей данных, являющихся каталогами всех элементов данных, присутствующих в DFD (потоки данных, накопители данных, процессы, а также все их атрибуты);
миниспецификаций процедур обработки, описывающие DFD-процессы диаграмм нижнего уровня и являющиеся базой для автоматизации разработки программ (кодогенерации). Фактически миниспецификации представляют собой алгоритмы процедур обработки. Множество всех мини-спецификаций является полной спецификацией информационного процесса.
Каждый узел-процесс а DFD может развертываться в диаграмму нижнего уровня. Таким образом, начиная с самой общей функции (контекстная диаграмма), описывающей весь процесс в целом, последовательно описание разбивается на более детальные функции (детальные диаграммы).
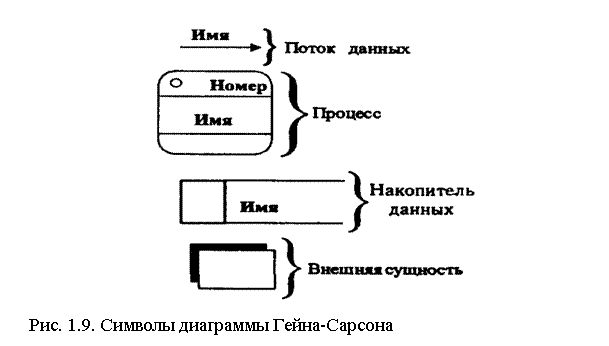 Простота DFD заключается в использовании только четырех символов для описания функций любой информационной системы на любом уровне детализации: символа для идентификации внешних объектов (внешних сущностей — материальных предметов или физических лиц, являющихся источником или приемником информации), символа для идентификации накопителей данных, символа для указания процессов и символа для указания направления движения данных (рис. 1.9).
Простота DFD заключается в использовании только четырех символов для описания функций любой информационной системы на любом уровне детализации: символа для идентификации внешних объектов (внешних сущностей — материальных предметов или физических лиц, являющихся источником или приемником информации), символа для идентификации накопителей данных, символа для указания процессов и символа для указания направления движения данных (рис. 1.9).
Рассмотрим диаграммы потоков данных (контекстную и первого уровня) для описания деятельности диспетчера районов курсирования (см. п. 1.7.4.2.). Контекстная диаграмма в нотации Гейна-Сарсона показана на рис. 1.10. Выделены три внешние сущности: ДОРОГА ПРИПИСКИ СОБСТВЕННИКА, ИТЦ ГВЦ МПС, ЖЕЛЕЗНОДОРОЖНЫЕ АДМИНИСТРАЦИИ; показаны потоки данных между диспетчером районов курсирования и этими объектами. На рис. 1.11 приведена диаграмма, детализирующая эту контекстную диаграмму. В отличие от IDEF0-моде-ли, приведенной на рис. 1.7, в этом случае кроме операций присутствуют элементы, обозначающие внешние сущности и базы данных (накопители данных).
1.7.5.2. Информационное моделирование. ERD-модель в нотации Баркера
На ER-диаграммах в нотации Баркера сущности представляются прямоугольниками любого размера, содержащим внутри себя имя сущности, список имен атрибутов и указатели ключевых атрибутов (знак # перед именем атрибута).
Все связи являются бинарными и представляются линиями соединяющими сущности, для которых определено имя, степень связи (один или много объектов участвуют в связи) и степень обязательности, т. е. обязательная или необязательная связь между сущностями. Если любой экземпляр сущности А может быть связан с несколькими экземплярами сущности Д, то со стороны прямоугольника сущности А линия присоединяется к прямоугольнику сущности В в трех точках (для одиночной связи в одной точке).
Если любой экземпляр сущности А обязательно должен быть связан с каким-либо экземпляром сущности В, то прилегающая к прямоугольнику А половина линии — сплошная, в противном случае — штриховая.
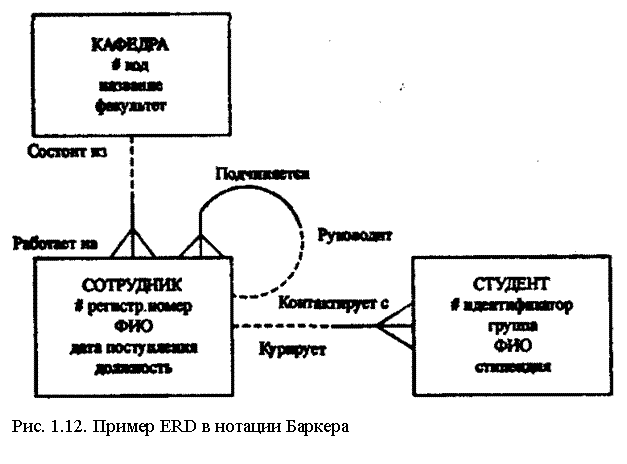 На рис.1.12 приведен пример ERD в нотации Баркера, в котором выделены сущности КАФЕДРА, СОТРУДНИК, СТУДЕНТ, определены отношения между ними, степень связи и обязательности отношения.
На рис.1.12 приведен пример ERD в нотации Баркера, в котором выделены сущности КАФЕДРА, СОТРУДНИК, СТУДЕНТ, определены отношения между ними, степень связи и обязательности отношения.
1.7.5.3. Событийное (динамическое) моделирование. STD-модель
В подходе Йодана для моделирования поведения системы используется расширенное описание DFD благодаря введению управляющих потоков (сигналов) и управляющих процессов, фактически являющихся интерфейсом между DFD и спецификациями управления, моделирующими поведение системы. Для формализации спецификации управления используют диаграммы STD (State Transition Diagrams), позволяющие задавать состояние различных объектов системы (например, запрос в системе может иметь состояния ОБСЛУЖИТЬ, ОЖИДАТЬ, ЗАБЛОКИРОВАТЬ), условия переходов из одного состояния в другое (как внешние по отношению к системе, так и внутренние, возникающие в самой системе), а также 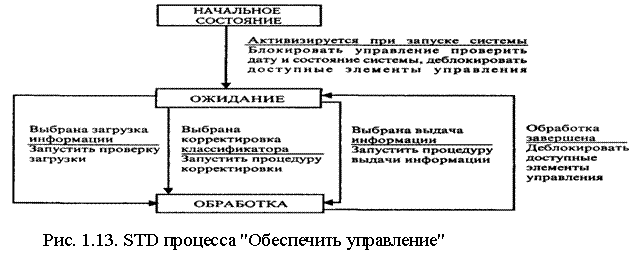 совершаемые при переходах действия (рис. 1.13).
совершаемые при переходах действия (рис. 1.13).
На STD состояния представляются узлами, а переходы - дугами. Условия (стимулирующие события) идентифицируются именем перехода и инициируют выполнение перехода.
Действия или отклики привязываются к переходам и записываются под соответствующей детализацией на нижних уровнях.
На рис. 1.13 приведены пример STD процесса ОБЕСПЕЧИТЬ УПРАВЛЕНИЕ. Здесь введены следующие состояния: НАЧАЛЬНОЕ СОСТОЯНИЕ, ОЖИДАНИЕ, ОБРАБОТКА. В свою очередь ОБРАБОТКА означает выполнение одной из трех процедур (ЗАГРУЗКА ИНФОРМАЦИИ, КОРРЕКТИРОВКА КЛАССИФИКАТОРА, ВЫДАЧА ИНФОРМАЦИИ).
Переходы из состояния в состояние осуществляются при выполнении условий, указанных над чертой рядом с дугами. Например, переход от «обработки» к «ожиданию» имеет место при завершении обработки. Под чертой приведены действия, которые следует произвести (например, «запустить процедуру загрузки» при выполнении условия «Выбрана загрузка информации»)
1.7.5.4. Последовательность действий при реализации методологий
Йодана де Марко и Гейна-Сарсона
Средства функционального, информационного и событийного (динамического) моделирования дают полное описание системы без рассмотрения путей ее реализации. Это описание является логической моделью проектируемой системы. Логическая модель позволяет разработчику и заказчику согласовывать конечные результаты, которые должны быть получены при реализации системы.
Последовательность действий при построении логической модели проектируемой системы на основе методологии Йодана де Марко и Гейна-Сарсона следующая:
q разработка общесистемной DFD-модели, описывающей области приложения системы, используемые данные и процедуры их обработки;
q определение списка элементов данных, размещаемых в каждом накопителе данных, описание информационных потоков;
q определение отношений между объектами предметной области, идентификация отношений между сущностями и указание типов отношений;
q представление всей информации в виде связанных двумерных таблиц, нормализация таблиц по схеме, предложенной Коддом (Codd), подразумевающая исключение повторяющихся групп, неполной функциональной зависимости, избыточности;
q составление спецификации процесса (в случае отсутствия необходимости детализировать его с помощью DFD). Фактически спецификация представляет собой алгоритмы задач, представленные с помощью структурированного естественного языка или визуальных языков проектирования;
q составление спецификации управления системой с помощью диаграммы переходов состояний STD.
q разбиение логической модели системы на процедурные единицы — автоматические и ручные процедуры, которые могут разрабатываться как отдельные части;
q составление спецификаций деталей каждой процедурной единицы, которые будут необходимы при реализации системы. Такие спецификации будут включать в себя фрагмент DFD, в котором специфицируемая процедура используется, фрагменты ERD, доступные процедурной единице базы данных, спецификации процесса процедурной единицы и управления им на структурированном языке.
Последние два этапа не относятся к логическому моделированию, а отображают переход от логической модели к физической реализации.
1.7.6. Тенденции развития CASE-технологий
Появление CASE-технологий явилось естественным этапом в развитии средств разработки программного обеспечения. Появлению CASE-средств предшествовало использование в качестве инструментария при создании ПО таких средств, как ассемблеры, компиляторы, интерпретаторы, символические отладчики, системы анализа и управления исходными текстами.
В эволюции CASE-технологий можно выделить два этапа. Первый этап характеризуется развитием технологий и CASE-средств, основанных на методологии структурного анализа и ориентированных на поддержку первых двух стадий жизненного цикла (анализ требований, проектирование). К CASE-средствам этого типа относятся такие, как Design/IDEF (компании Meta Software), BPWin (Platinum), Design/2000 (ORACLE) и др. [18].
Второй этап характеризуется развитием технологий и средств, поддерживающих все стадии жизненного цикла, в первую очередь, стадии программирования, тестирования и отладки. Применение этих средств обеспечивает автоматическую кодогенерацию из полученных спецификаций с полным документированием разработанных программ. К CASE-средствам этого уровня относятся такие пакеты, как COBOL2/Workbench (Mikro Focus), DECASE (DEC) и др. CASE-средства второго этапа могут включать до 100 функциональных компонентов, поддерживающих все этапы жизненного цикла, предоставляя пользователям возможность выбора необходимых средств и их интеграцию в нужном составе [18].
С начала 90-х годов получают развитие CASE-технологии, основанные на комбинировании методологии структурного анализа и объектно-ориентированных методов создания ПО. Объектно-ориентированные методы имеют ряд преимуществ по сравнению со структурной методологией построения информационных систем (ИС) (см. раздел «Проектирование БД»).
Комбинированные CASE-средства поддерживают объектно-ориентированные и структурные методологии, что упрощает переход на объектно-ориентированные технологии разработчикам, которые использовали CASE-средства в структурных разработках.
Список литературы
1. ГОСТ 34.Автоматизированные системы. Стадии создания. Введены 01.01.1992.
2. Лецкий качества функционирования автоматизированных систем управления: Методические указания. — М.: МИИТ, 1982. — 52с.
3. Фоке Дж. Программное обеспечение и его разработка: — М.: Мир, 1985.—368с.
4. , Ратин информационные системы на железнодорожном транспорте. — М.: Транспорт, 1984. — 239 с.
5. , , и др.; Под ред. . Информационная система для управления перевозочным процессом. — М.: Транспорт, 1989. — 239 с.
6. Методы проектирования программных систем: — М.: Мир, 1985.—328с.
7. , , и др.; Под ред. . Расчеты АСУ (на примерах АСУ железнодорожного транспорта). — М. : Транспорт, 1985. — 232 с.
8. , Овчаров случайных процессов и ее инженерные приложения. —М.: Наука, 1991. — 384 с.
9. Лион Ф. Статистика и планирование эксперимента в технике и науке. Методы обработки данных. — М. : Мир, 1980. — 610 с.
10. Лецкий случайных процессов: Методические указания. — М.: МИИТ, 1991. — 56 с.
11. , Смирнов математической статистики. — М.: Наука, 1968. — 473 с.
12. ГОСТ 34.Виды, комплектность и обозначение документов при создании автоматизированных систем. //В сб: Информационная технология. Комплекс стандартов и руководящих документов на автоматизированные системы. - М.: Изд-во стандартов, 1991. — С. 3-14.
13. ГОСТ 34.Техническое задание на создание автоматизированной системы. // В сб. Информационная технология. Комплекс стандартов и руководящих документов на автоматизированные системы. — М.: Изд-во стандартов, 1991. — С. 15-29.
14. РД90. Автоматизированные системы. Требования к содержанию документов. // В сб. Информационная технология. Комплекс стандартов и руководящих документов на автоматизированные системы. — М.: Изд-во стандартов, 1991. — С. 66-104.
15. ГОСТ 34.Автоматизированные системы. Термины и определения. — М.: Изд-во стандартов, 1992. — С. 105-127
16. ГОСТ 28.Оценка качества программных средств. Общие положения. М.: Изд-во стандартов, 1989. — 38 с.
17. Мамиконов АСУ. - М. : Высшая школа, 1987. — 303 с.
18. CASE: структурный системный анализ (автоматизация и применение). — М.: ЛОРИ, 1996. — 242 с.
19. CASE-технологии: современные методы и средства проектирования информационных систем. — http://citforum. rn.
20. BPwin и ERwin. CASE-средства разработки информационных систем. — М.: ДИАЛОГ-МИФИ, 1999. — 256 с.
1) Основан на данных примера 1.4 из [7].
1) Первичный ключ — это атрибут или группа атрибутов, однозначно идентифицирующая экземпляр сущности [20].

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
