


1. 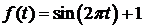 ;
;
2. ![]() ;
;
3. ![]() ;
;
4. ![]() .
.
3. Содержание отчета
1. Цель работы.
2. График функции ![]() .
.
3. Аналитический расчет величины F.
4. Описание разработанной программы: список использованных переменных, блок-схема, текст программы.
5. Табличное представление результатов моделирования ![]() .
.
6. График по рассчитанной таблице. Ось абсцисс представить в логарифмическом масштабе по основанию 2. На графике отметить уровнем величину F.
7. Выводы.
4. Вопросы для самопроверки
1. Объясните два алгоритма оценки определенного интеграла методом Монте-Карло. Назовите преимущества и недостатки каждого.
2. Вычислите математическое ожидание оценки площади методом Монте-Карло.
3. Обоснуйте гипотезу о нормальном распределении вероятностей для оценки определенного интеграла по методу Монте-Карло.
4. Какие величины связываются неравенством Чебышева.
5. Сформулируйте теорему Бернулли.
6. Сформулируйте закон трёх сигма.
7. Как зависит погрешность оценки площади от числа экспериментов?
5. Список рекомендованной литературы
1. Вентцель вероятности. М.: Наука. 1969 г.
2. Соболь Монте-Карло. М.: Наука. 1985 г.
3. , , Шрейдер статистических испытаний (метод Монте-Карло). М.: Физматгиз. 1962 г.
Лабораторная работа №2
Датчики случайных чисел. Построение гистограмм.
1. Необходимые теоретические сведения.
1.1 Введение
При имитационном моделировании разработчику модели часто требуется формировать на ЭВМ последовательности случайных чисел, отображающие реальный случайный процесс. Одной из основных характеристик случайного процесса является его закон распределения вероятностей, и погрешность моделирования определяется прежде всего тем, насколько точно воспроизводится закон распределения вероятностей случайной величины.
Таким образом, необходима методика построения датчиков случайных чисел с заданным законом распределения вероятностей а также методика оценки точности работы датчика.
В последующем изложении закон и плотность распределения вероятностей считаются синонимами. При этом, слово «вероятностей» в отдельных случаях для сокращения текста может быть опущено.
1.2 Формирование датчиков случайных чисел с заданным законом распределения вероятностей
Практически все языки программирования обладают встроенным генератором равномерно распределенных чисел. Будем называть его базовым датчиком. Существует ряд способов, позволяющих на основе базового датчика получить последовательность чисел с заданным законом распределения. Основной способ, называемый методом обратного преобразования, базируется на следующей теореме.
Теорема. Пусть случайная величина a имеет плотность распределения вероятностей fa(x). Тогда случайная величина 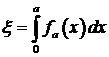 имеет равномерный закон распределения на интервале [0,1].
имеет равномерный закон распределения на интервале [0,1].
Из теоремы следует, что для формирования последовательности чисел ai, имеющих закон распределения fa(x), необходимо разрешить относительно ai уравнение

где Ri - число, сформированное базовым датчиком случайных чисел, имеющим равномерный закон распределения на интервале [0,1]. Недостатком метода обратного преобразования является невозможность его применения в случаях, когда для заданного закона распределения интеграл в (1) не вычисляется в замкнутом виде (например, для нормального закона). Тогда необходимо использовать специальные методы.
Ниже рассмотрены несколько датчиков для конкретных, популярных на практике распределений вероятностей.
1). Датчик чисел с равномерным законом распределения на заданном интервале.
Пусть необходимо создать датчик случайных чисел ai, имеющих закон распределения:
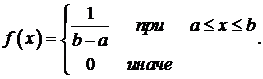
В данном случае уравнение (1) может быть записано следующим образом:
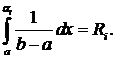
Преобразуем левую часть уравнения по формуле Ньютона-Лейбница:
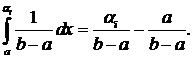
Тогда:
![]() .
.
2). Датчик чисел с экспоненциальным законом распределения.
Датчик чисел с экспоненциальным законом распределения широко используется при моделировании систем массового обслуживания. В частности, в пуассоновском потоке заявок интервалы времени между соседними заявками распределены по экспоненциальному закону. Плотность вероятности записывается следующим образом:
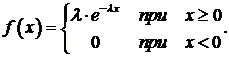
Пользуясь методом обратного преобразования, можно вывести следующее соотношение:
![]()
3). Датчик чисел с нормальным законом распределения.
Нормальный закон распределения встречается повсеместно и описывает большое количество процессов в природе: начиная от шумов в радиотехнических системах до размера плодов в сельском хозяйстве. Он описывается следующей формулой:
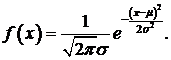
Применение метода обратного преобразования невозможно в силу того, что интеграл от данной функции не выражается конечной формулой. Один из наиболее распространенных способов построения датчика нормально распределенных чисел заключается в следующем: формируются две независимые случайные величины Ri и Ri+1. Тогда, по формулам 4, известным как преобразование Бокса-Мюллера, можно сформировать две независимые случайных величины, распределенных по нормальному закону с нулевым математическим ожиданием и единичной дисперсией.
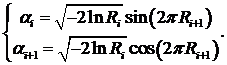
4). Датчик чисел с эрланговским законом распределения.
Случайная величина, распределенная по закону Эрланга порядка k и параметром l, является суммой k независимых случайных величин, имеющих экспоненциальное распределение с параметром l. Таким образом,
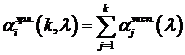 .
.
Поэтому последовательность чисел с эрланговским законом распределения можно получить путем суммирования заданного числа последовательностей с экспоненциальным законом распределения, созданных, например, по формуле (2.3).
1.3 Оценивание закона распределения случайной величины
Как было отмечено в подразделе 1.1, для качественного моделирования закон распределения вероятностей на выходе датчика случайных чисел должен максимально совпадать с законом распределения для реального процесса. Для оценки закона распределения вероятностей используется экспериментальная гистограмма.
Построение экспериментальной гистограммы сводится к следующим действиям:
1. Определение граничных значений интервала оценивания xmin и xmax.
2. Разбиение интервала (xmin, xmax) на подинтервалы D1,D2,…, Dn. Количество и длительности подинтервалов выбираются, исходя из требуемой точности.
3. Создание выборки независимых значений случайной величины.
4. Формирование вектора Y=[y1,y2,…,yn]. Компоненты вектора вычисляются по формуле 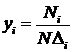 , где Ni - число элементов выборки, попавших в подинтервал Di, N – объем выборки.
, где Ni - число элементов выборки, попавших в подинтервал Di, N – объем выборки.
Гистограммой называется визуальная интерпретация вектора Y. Гистограмма имеет ступенчатый вид. При этом высота «ступеньки» над интервалом Di равна yi.
Пример 1 .
Дана выборка, объем которой равен десяти: 0, 7, 4, 9, 5, 4, 8, 5, 2, 7. Минимальный элемент выборки равен 0, максимальный – 9. Разобьем интервал [0,9] на три интервала: [0,3), [3,6) и (6,9]. Длины всех трех интервалов одинаковы и равны D1=D2=D3=3. Тогда в первый интервал попадут два элемента (0 и 2), во второй – четыре (4, 4, 5 и 5), в третий – четыре (7, 9, 8, и 7). Вектор Y при этом будет иметь следующий вид: 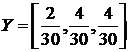 . Гистограмма данной выборки приведена на рис. 4.
. Гистограмма данной выборки приведена на рис. 4.
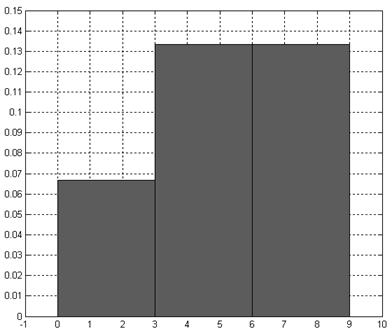
Рис. 4. Гистограмма выборки из примера 1.
Теоретическая гистограмма строится следующим образом: высота ступеньки над подинтервалом ![]() равна интегралу от плотности распределения вероятностей по этому подинтервалу.
равна интегралу от плотности распределения вероятностей по этому подинтервалу.
При построении гистограммы важным является правильный выбор объема выборки N, граничных значений xmin и xmax, а также конфигурации подинтервалов. Например, с увеличением N точность результатов моделирования возрастает, но возрастают и затраты на проведение моделирования. Для правильного выбора этих параметров гистограммы разработчику придется решать непростые задачи из области математической статистики, поэтому на практике, как правило, пользуются эмпирическими, инженерными правилами.
Одно из них гласит о том, что если данное событие происходит в процессе моделирования не менее 100 раз, то с вероятностью, близкой к единице, экспериментальная оценка вероятности этого события будет иметь относительную погрешность, меньшую 10%. Это утверждение может быть строго обосновано только для некоторых частных случаев. В то же время, не известны примеры из практики, опровергающие его. Таким образом, для обеспечения приемлемой точности оценивания необходимо увеличивать объем выборки до тех пор, пока не выполнится следующее условие:
![]()
Граничные значения анализируемого интервала xmin и xmax должны выбираться так, чтобы вероятность попадания случайной величины за границы данного интервала Pвне интервала была меньше некой заранее заданной величины. На практике, xmin и xmax, как правило, выбираются таким образом, чтобы Pвне интервала < 0.01.
В задачах, не требующих высокой точности, длительности интервалов D1,D2,…, Dn выбираются равными (![]() ), а n = 10.
), а n = 10.
С учетом всего вышесказанного обобщенный алгоритм построения гистограммы можно представить следующим образом.
1. Массив выборки – пустой: A = Æ. xmin = 0, xmax = 0, D = 0, N = 0.
2. N = N + 1.
3. Формирование случайного числа a и добавление его к выборке: A=AÈa.
4. Ni = Ni + 1, где i - номер подинтервала, которому принадлежит a.
5. 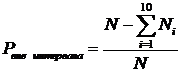 .
.
6. Если Pвне интервала ³ 0.01, то левой границей анализируемого интервала назначается минимальный элемент выборки А (xmin = minA), правой границей - максимальный элемент выборки А (xmax = maxA). 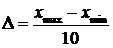 . Пересчет всех Ni.
. Пересчет всех Ni.
7. Выполняется условие min{N1,N2,…,Nn} = 100? Если нет, то возврат ко второму шагу.
8. Формирование вектора Y.
9. Построение гистограммы по вектору Y.
2. Цель работы
Изучение алгоритмов получения на ЭВМ чисел с заданным законом распределения и построения гистограмм.
3. Порядок выполнения работы
1. Выбрать из таблицы 3 в соответствии с вариантом закон распределения вероятностей.
2. Вывести соотношение, позволяющее из чисел, сформированных базовым датчиком, получить числа с заданным законом распределения.
3. Написать программу, реализующую датчик случайных чисел с заданным законом распределения. Входными параметрами программы являются характеристики закона распределения и требуемое количество чисел.
4. Написать программу построения гистограммы выборки, сформированной созданным датчиком с учетом параметров, заданных в таблице 2. Программа должна автоматически выбирать конфигурацию подинтервалов и объем выборки. Также должна быть предусмотрена возможность на каждом цикле программы вычислять оценки математического ожидания и дисперсии по текущей выборке.
5. При помощи программы построения гистограмм заполнить таблицу 1. Зафиксировать xmin и xmax.
Таблица 2 – Распределение элементов выборки по квантам гистограммы
Номер интервала | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
Число элементов, попавших в данный интервал |
6. На основании таблицы 2 построить гистограмму распределения сформированной выборки.
7. Построить график зависимости оценок математического ожидания и дисперсии от объема выборки.
4. Варианты заданий
Таблица 3 – Варианты заданий к лабораторной работе №2
Номер варианта | Закон распределения | Параметры закона |
1 | Равномерный | a = 0, b = 5 |
2 | Нормальный | m = 0, s = 1 |
3 | экспоненциальный | l = 1 |
4 | Эрланговский | k = 2, l = 2 |
5 | Равномерный | a = -3, b =3 |
6 | Нормальный | m = 3, s = 2 |
7 | экспоненциальный | l = 2 |
8 | Эрланговский | k = 3, l = 4 |
9 | Равномерный | a = 10, b = 25 |
10 | Нормальный | m = -1, s = 5 |
11 | экспоненциальный | l = 3 |
12 | Эрланговский | k = 4, l = 2 |
13 | Равномерный | a = -15, b = -10 |
14 | Нормальный | m = 0, s = 5 |
15 | экспоненциальный | l = 4 |
16 | Эрланговский | k = 3, l = 1 |
17 | Равномерный | a = 2, b = 3 |
18 | Нормальный | m = -5, s = 12 |
19 | экспоненциальный | l = 5 |
20 | Эрланговский | k = 5, l = 3 |
21 | Равномерный | a = -10, b = -10 |
22 | Нормальный | m = 0.5, s = 0.1 |
23 | экспоненциальный | l = 6 |
24 | Эрланговский | k = 3, l = 3 |
25 | Равномерный | a = 1, b = 6 |
5. Содержание отчета
1. Цель работы.
2. Формула и график моделируемого закона распределения.
3. Описание разработанных программ: список использованных переменных, список использованных функций, блок-схема, листинг.
4. Табличное представление результатов анализа сформированной выборки (данные таблицы 2).
5. Гистограмма сформированной выборки.
6. Графики зависимости оценок математического ожидания и дисперсии от объема выборки. На графиках уровнем отметить теоретические значения эти величин.
7. Выводы.
6. Вопросы для самопроверки
1. Чем отличается плотность распределения вероятности от интегральной функции распределения вероятности? Приведите пример.
2. Как по плотности распределения вероятностей вычислить вероятность попадания случайного значения в заданный интервал?
3. Как по интегральной функции распределения вероятности вычислить вероятность попадания случайного значения в заданный интервал?
4. В чем заключается метод обратного преобразования?
5. Для каких распределений вероятности можно использовать другие методы построения датчиков?
6. Как строится экспериментальная гистограмма?
7. Как выбираются границы области построения гистограммы?
8. Как определить необходимый объем выборки для построения гистограммы?
7. Список рекомендованной литературы
7. Вентцель вероятности. М.: Наука. 1969 г.
8. , , Имитационное моделирование. М.: Издательство МГТУ им. Баумана, 2008 г.
9. , , Исследование на ЦВМ датчиков случайных чисел. СПб.: СПбГУАП, 1997 г.
10. , , Шрейдер статистических испытаний (метод Монте-Карло). М.: Физматгиз. 1962 г.
Лабораторная работа № 3.
Моделирование входного потока запросов
1. Необходимые теоретические сведения
1.1 Введение
Имитационное моделирование является эффективным, а часто и единственным инструментом исследования систем массового обслуживания (СМО).
Модель СМО, как правило, декомпозируется на три составляющие:
- входной поток заявок,
- буфер (очередь),
- обслуживающее устройство (ОУ).
Для точного моделирования СМО необходимо наряду с параметрами буфера и ОУ также знать статистические характеристики входного потока заявок.
1.2 Модели входного потока заявок
Для описания входного потока запросов часто бывает достаточно задать последовательность моментов поступления запросов на вход СМО. В зависимости от классификации этой последовательности потоки делятся на стохастические и детерминированные, на однородные и неоднородные. Стохастические потоки делятся в свою очередь на стационарные и нестационарные. Остановимся подробней на каждом из этих видов.
Детерминированные потоки заявок.
Такие потоки могут задаваться либо в виде расписания (таблицы моментов поступления заявок), либо указанием алгоритма, позволяющего вычислить моменты поступления заявок без использования случайных чисел и случайного выбора. Примером СМО с детерминированным потоком заявок является аэропорт. Обслуживающим устройством является взлётно-посадочная полоса, а входной поток запросов задается расписанием отправления самолетов, использующих эту полосу.
Стохастические стационарные потоки заявок.
В стохастическом (случайном) потоке моменты поступления запросов случайны, и в общем случае их описание требует большого количества информации. Поэтому здесь рассматриваются лишь наиболее простые модели потоков. Будем полагать, что длительности временных интервалов между моментами поступления соседних запросов являются случайными величинами u1,u2,…, которые попарно статистически независимы и все имеют одну и ту же плотность распределения вероятностей fu(x) (такой поток называется рекуррентным потоком или потоком Пальма). Интенсивностью потока называется величина 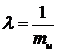 , где mu – математическое ожидание случайной величины u. Интенсивность потока l равна среднему числу запросов на промежутке времени, выбранном за единицу (1сек., 1мин., 1час и т. д.). Важной характеристикой рекуррентного потока, характеризующей уровень его случайности, является коэффициент вариации, равный отношению среднеквадратического значения к среднему значению случайной величины u, то есть . Для большинства реальных потоков значение vu лежит в пределах от 0 до 1, причем, vu = 0 для детерминированных потоков.
, где mu – математическое ожидание случайной величины u. Интенсивность потока l равна среднему числу запросов на промежутке времени, выбранном за единицу (1сек., 1мин., 1час и т. д.). Важной характеристикой рекуррентного потока, характеризующей уровень его случайности, является коэффициент вариации, равный отношению среднеквадратического значения к среднему значению случайной величины u, то есть . Для большинства реальных потоков значение vu лежит в пределах от 0 до 1, причем, vu = 0 для детерминированных потоков.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
