



Управление складом, ассортиментом, закупками
Далее, можно автоматизировать процесс анализа движения товара, тем самым отследив и зафиксировав те двадцать процентов ассортимента, которые приносят восемьдесят процентов прибыли. Это же позволит ответить на главный вопрос — как получать максимальную прибыль при постоянной нехватке средств? «Заморозить» оборотные средства в чрезмерном складском запасе — самый простой способ сделать любое предприятие, производственное или торговое, потенциальным инвалидом. Можно просмотреть перспективный товар, вовремя не вложив в него деньги.
Управление производственным процессом
Управление производственным процессом представляет собой очень трудоёмкую задачу. Основными механизмами здесь являются планирование и оптимальное управление производственным процессом. Автоматизированное решение подобной задачи дает возможность грамотно планировать, учитывать затраты, проводить техническую подготовку производства, оперативно управлять процессом выпуска продукции в соответствии с производственной программой и технологией. Очевидно, что чем крупнее производство, тем большее число бизнес-процессов участвует в создании прибыли, а значит, использование информационных систем жизненно необходимо.
Управление маркетингом
Управление маркетингом подразумевает сбор и анализ данных о фирмах-конкурентах, их продукции и ценовой политике, а также моделирование параметров внешнего окружения для определения оптимального уровня цен, прогнозирования прибыли и планирования рекламных кампаний. Решение большинства этих задач могут быть формализованы и представлены в виде информационной системы, позволяющей существенно повысить эффективность управления маркетингом.

Документооборот
Документооборот является очень важным процессом деятельности любого предприятия. Хорошо отлаженная система учетного документооборота отражает реально происходящую па предприятии текущую производственную деятельность и дает управленцам возможность воздействовать на нее. Поэтому автоматизация документооборота позволяет повысить эффективность управления.
Оперативное управление предприятием
Информационная система, решающая задачи оперативного управления предприятием, строится на основе базы данных, в которой фиксируется вся возможная информация о предприятии. Такая информационная система является инструментом для управления бизнесом и обычно называется корпоративной информационной системой.
Информационная система оперативного управления включает в себя массу программных решений автоматизации бизнес-процессов, имеющих место на конкретном предприятии. Одно из наиболее важных требований, предъявляемых к таким информационным системам - гибкость, способность к адаптации и дальнейшему развитию.
Предоставление информации о фирме
Активное развитие сети Интернет привело к необходимости создания корпоративных серверов для предоставления различного рода информации о предприятии. Практически каждое уважающее себя предприятие сейчас имеет свой web-сервер. Web-сервер предприятия решает ряд задач, из которых можно выделить две основные:
· создание имиджа предприятия;
· максимальная разгрузка справочной службы компании путем предоставления потенциальным и уже существующим абонентам возможности получения необходимой информации о фирме, предлагаемых товарах, услугах и ценах.
Кроме того, использование web-технологий открывает широкие перспективы для электронной коммерции и обслуживания покупателей через Интернет.
Жизненный цикл информационных систем
Разработка корпоративной информационной системы, как правило, выполняется для вполне определенного предприятия. Особенности предметной деятельности предприятия, безусловно, будут оказывать влияние на структуру информационной системы. Но в то же время структуры разных предприятий в целом похожи между собой. Каждая организация, независимо от рода ее деятельности, состоит из ряда подразделений, непосредственно осуществляющих тот или иной вид деятельности компании. И эта ситуация справедлива практически для всех организаций, каким бы видом деятельности они ни занимались.
Таким образом, любую организацию можно рассматривать как совокупность взаимодействующих элементов (подразделений), каждый из которых может иметь свою, достаточно сложную, структуру. Взаимосвязи между подразделениями тоже достаточно сложны. В общем случае можно выделить три вида связей между подразделениями предприятия:
· функциональные связи - каждое подразделение выполняет определенные виды работ в рамках единого бизнес-процесса;
· информационные связи - подразделения обмениваются информацией
· внешние связи – некоторые подразделения взаимодействуют с внешними системами, причем их взаимодействие также может быть, как информационным, так и функциональным.
Общность структуры разных предприятий позволяет сформулировать некоторые единые принципы построения корпоративных информационных систем.
В общем случае процесс разработки информационной системы может быть рассмотрен с двух точек зрения:
· по содержанию действий разработчиков (групп разработчиков). В данном случае рассматривается статический аспект процесса разработки, описываемый в терминах основных потоков работ: исполнители, действия, последовательность действий и т. п.;
· по времени, или по стадиям жизненного цикла разрабатываемой системы. В данном случае рассматривается динамическая организация процесса разработки, описываемая в терминах циклов, стадий, итераций и этапов.
Вопросы:
Какова область применения информационных систем? Примеры реализации ИС? Что подразумевает жизненный цикл информационных систем?Лекция 4
Базы данных: основные сведения
Всегда, когда возникает потребность манипулировать большими массивами данных, используются базы данных.
База данных (мы будем говорить о так называемых реляционных базах данных) — это прежде всего набор таблиц, хотя, как мы увидим позднее, в базу данных могут входить также процедуры и ряд других объектов.
С точки зрения пользователя, база данных — это программа, которая обеспечивает работу с информацией. При запуске такой программы на экране, как правило, появляется таблица, просматривая которую пользователь может найти интересующие его сведения. Если система позволяет, то он может внести изменения в базу данных: добавить новую информацию или удалить ненужную.
С точки зрения программиста, база данных — это набор файлов, содержащих информацию. Разрабатывая базу данных для пользователя, программист создает программу, которая обеспечивает работу с файлами данных.
В настоящее время существует достаточно большое количество программных систем, позволяющих создавать и использовать локальные {dBASE, FoxPro, Access, Paradox) и удаленные (Interbase, Oracle, Sysbase, Infomix, Microsoft SQL Server) базы данных.
СУБД позволяют структурировать, систематизировать и организовывать данные для их компьютерного хранения и обработки. Именно системы управления базами данных являются основой практически любой информационной системы.
СУБД можно определить как некую систему управления данными, обладающую следующими свойствами:
· поддержание логически согласованного набора файлов;
· обеспечение языка манипулирования данными;
· восстановление информации после разного рода сбоев;
· обеспечение параллельной работы нескольких пользователей.
Основные функции СУБД
К основным функциям, выполняемым системами управления базами данных, обычно относят следующие:
1. непосредственное управление данными во внешней памяти;
2. управление буферами оперативной памяти;
3. управление транзакциями;
4. протоколирование;
5. поддержка языков баз данных.
Рассмотрим каждую из указанных функций более подробно.
Непосредственное управление данными во внешней памяти
Функция непосредственного управления данными во внешней памяти включает обеспечение необходимых структур внешней памяти (постоянных запоминающих устройств — как правило, магнитных дисков) как для хранения данных, непосредственно входящих в базу данных, так и для служебных целей, например для ускорения доступа к данным в некоторых случаях (обычно для этого используются индексы). Причем пользователям базы данных в общем случае не нужно знать, использует ли СУБД файловую систему и если использует, то как организованы файлы. Обычно СУБД поддерживает собственную систему именования объектов БД. В зависимости от способа реализации СУБД может либо использовать возможности существующих файловых систем, либо работать с устройствами внешней памяти на низком уровне.
Управление буферами оперативной памяти
Объём информации, хранящейся в базе данных, с которой работает СУБД, обычно достаточно велик и практически всегда превышает доступный объем оперативной памяти. При этом время доступа к данным, хранящимся в оперативной памяти, существенно меньше, чем к данным, хранящимся на устройствах внешней памяти. Очевидно, что если при обращении к любому элементу данных будет производится обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти.
Увеличения скорости обмена данными Можно достичь, используя буферизацию данных в оперативной памяти. При этом, даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части базы данных. Поэтому в СУБД обычно поддерживается собственный набор буферов оперативной памяти с собственным механизмом замены буферов.
примечание
следует отметить, что существует направление развития СУБД, ориентированное на постоянное присутствие в оперативной памяти всей информации из базы данных. это направление основывается на предположении, что в будущем объем оперативной памяти компьютеров будет настолько велик, что буферизация станет не нужна. если исходить из темпов снижения цен на оперативную память, то такие СУБД действительно могут стать актуальными в достаточно недалеком будущем.
Управление транзакциями
Транзакцией называется последовательность операций над базой данных, рассматриваемых СУБД как единое целое. Если все операции успешно выполнены, то транзакция также считается успешно выполненной и СУБД фиксирует (COMMIT) все изменения данных, произведенные этой транзакцией (то есть заносит изменения во внешнюю память). Если же хотя бы одна операция транзакции заканчивается неудачей, то транзакция считается невыполненной и производится откат (ROLLBACK) — отмена всех изменений данных, произведенных в ходе выполнения транзакции, и возврат базы данных к состоянию до начала выполнения транзакции. Управление транзакциями необходимо для поддержания логической целостности базы данных. Поддержка механизма транзакций является обязательным условием даже однопользовательских, а тем более для многопользовательских СУБД. То свойство, что каждая транзакция начинается при целостном состоянии базы данных и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к базе данных. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может, в принципе, ощущать себя единственным пользователем СУБД.
С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций. Под сериализациями параллельно выполняющихся транзакций понимается такое планирование их работы, при котором суммарный результат смеси транзакций эквивалентен результату их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций - это такой план, который приводит к сериализации транзакций. Попятно, что если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы по сравнению с однопользовательским режимом).
Существует несколько базовых алгоритмов сериализации транзакций. В централизованных СУБД наиболее распространены алгоритмы, основанные на синхронизационных захватах объектов базы данных. При использовании любого алгоритма сериализации возможны конфликты между несколькими транзакциями по доступу к объектам базы данных, В этом случае для поддержания сериализации необходимо выполнить откат одной или нескольких транзакций. Это один из случаев, когда пользователь многопользовательской СУБД может реально (и достаточно неприятно) ощутить присутствие в системе транзакций других пользователей.
Журнализация
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Аппаратные сбои обычно подразделяются на два вида:
1) мягкие сбои связаны с внезапной остановкой работы компьютера. Обычно являются следствием внезапного выключения питания или "зависания" операционной системы (что особенно характерно для операционных систем Windows);
2) жесткие сбои характеризуются потерей информации на носителях внешней памяти.
Программные сбои обычно возникают вследствие ошибок в программах. Причем эти ошибки могут быть как в самой СУБД, что может привести к аварийному завершению ее работы, так и в пользовательской программе. Первый случай можно рассматривать как разновидность мягкого аппаратного сбоя. Во втором случае незавершенной остается только одна транзакция.
В любом случае для восстановления информации в базе данных необходимо иметь некоторую дополнительную информацию. Таким образом, для поддержания надежности хранения данных требуется избыточность данных. Причем та часть информации, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений базы данных. Журнал представляет собой особую часть базы данных, недоступную пользователям СУБД и поддерживаемую с особой тщательностью (иногда используются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части базы данных. В разных СУБД изменения базы данных журнализируются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения базы данных, иногда — минимальной внутренней операции модификации страницы внешней памяти. Могут также использоваться одновременно оба подхода. Во всех случаях придерживаются стратегии «упреждающей» записи в журнал (так называемого протокола Write Ahead Log — WAL). Несколько утрированно можно сказать, что эта стратегия заключается в том, что запись об изменении любого объекта базы данных должна быть занесена в журнал до того, как будет выполнено и зафиксировано изменение этого объекта. Если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления базы данных после любого сбоя.
Самая простая ситуация восстановления — индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений базы данных. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации базы данных, выполненных в этой транзакции, и производить откат транзакции путем выполнения обратных операций, следуя' от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи, относящиеся к одной транзакции, связывают обратным списком (от конца к началу). При мягком сбое во внешней памяти основной части базы данных могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является приведение внешней памяти основной части базы данных в такое состояние, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для того чтобы этого добиться, сначала производят откат незавершенных транзакций, а потом повторно воспроизводят те операции завершенных транзакций, результаты которых не отображены во внешней памяти.
Для восстановления базы данных после жесткого сбоя используют журнал и архивную копию базы данных. Архивная копия — это полная копия базы данных к моменту начала заполнения журнала (хотя имеется много вариантов трактовки смысла архивной копии). Для нормального восстановления базы данных после жесткого сбоя, естественно, необходимо, чтобы журнал не пропал. Тогда восстановление базы данных состоит в том, что, исходя из архивной копии, по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления. Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным.
Поддержка языков баз данных
Для работы с информацией, хранящейся в базе данных, используются специальные языки, носящее общее название языков баз данных. Чаще всего выделяются два языка:
язык определения схем данных (Schema Definition Language, SDL) служит главным образом для определения логической структуры базы данных;
язык манипулирования данными (Data Manipulation Language, DML) содержит набор операторов манипулирования данными, то есть операторов, позволяющих заносить данные в базу, а также удалять, модифицировать или выбирать существующие данные.
Несколько разных специализированных языков баз данных поддерживалось лишь в ранних СУБД. В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с базой данных, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). Таким образом, указанные выше языки баз данных на сегодняшний день фактически являются подмножествами единого стандартного языка SQL.
Язык SQL позволяет определять схему реляционной базы данных и манипулировать данными. При этом именование объектов базы данных (для реляционной базы данных — именование таблиц и их полей) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов.
Язык SQL содержит специальные средства определения ограничений целостности базы данных. Опять же, ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности базы данных производится на языковом уровне — при компиляции операторов модификации базы данных компилятор SQL на основании имеющихся в базе данных ограничений целостности генерирует соответствующий программный код.
Специальные операторы языка SQL позволяют определять так называемые представления базы данных, фактически являющиеся хранимыми в базе данных запросами (результатом любого запроса к реляционной базе данных является таблица) с именованными столбцами, называемыми полями. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в базе данных, но с помощью представлений можно ограничить или, наоборот, расширить видимость данных для конкретного пользователя. Поддержка представлений производится также на языковом уровне.
Наконец, авторизация доступа к объектам базы данных производится также на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу базы данных, обладает полным набором полномочий для работы с данной таблицей. В число этих полномочий входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне.
Лекция 5
Классификация информационных систем
Информационные системы классифицируются по разным признакам. Рассмотрим наиболее часто используемые способы классификации.
Классификация по масштабу
По масштабу информационные системы подразделяются на следующие группы:
(рис. 1.1):
одиночные;
групповые;
корпоративные.

Рис. 1.1. Деление информационных систем по масштабу
Одиночные информационные системы
Одиночные информационные системы реализуются, как правило, на автономном ПК (сеть не используется). Такая система может содержать несколько простых приложений, связанных общим информационным фондом, и рассчитана на работу одного пользователя или группы пользователей, разделяющих по времени одно рабочее место. Подобные приложения создаются с помощью так называемых настольных или локальных систем управления базами данных (СУБД). Среди локальных СУБД наиболее известными являются Clarion, Clipper, FoxPro, Paradox, dBase и Qicrosoft Access.
Групповые информационные системы
Групповые информационные системы ориентированы на коллективное использование информации членами рабочей группы и чаще всего строятся на базе локальной вычислительной сети. При разработке таких приложений используются серверы баз данных (называемые также SQL-серверами) для рабочих групп. Существует довольно большое количество различных SQL-серверов, как коммерческих, так и свободно распространяемых. Среди них наиболее известны такие серверы баз данных, как Oracle, DB2. Qicrosoft SQL Server, InlerBase, Sybase, Inforqix.
Корпоративные информационные системы
Корпоративные информационные системы являются развитием систем для рабочих групп, они ориентированы на крупные компании и могут поддерживать территориально разнесенные узлы или сети. В основном они имеют иерархическую структуру из нескольких уровней. Для таких систем характерна архитектура клиент-сервер со специализацией сервером или же многоуровневая архитектура. При разработке таких систем могут использоваться те же серверы баз данных, что и при разработке групповых информационных систем. Однако в крупных информационных системах наибольшее распространение получили серверы Oracle, DB2 и Qocrosoft SQLServer.
Для групповых и корпоративных систем существенно повышаются требования к надежности функционирования и сохранности данных. Эти свойства обеспечиваются поддержкой целостности данных, ссылок и транзакции в серверах баз данных.
Классификация по сфере применения
По сфере применения информационные системы обычно подразделяются па четыре группы (рис. 1.2):
системы обработки транзакций;
системы принятия решений;
информационно-справочные системы;
офисные информационные системы.
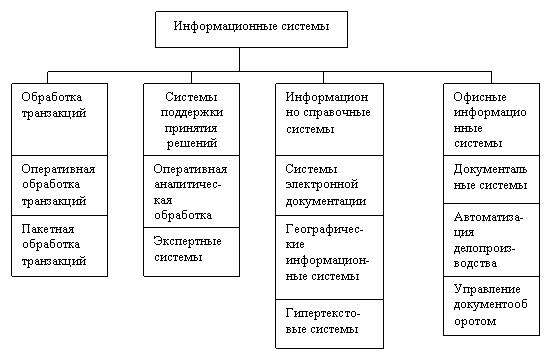

РисДеление информационных систем по сфере применения
Системы обработки транзакций, в свою очередь, по оперативности обработки данных, разделяются на пакетные информационные системы и оперативные информационные системы. В информационных системах организационного управления преобладает режим оперативной обработки транзакций - OLTP (OnLinc Transaction Processing), для отражения актуального состояния предметной области в любой момент времени, а пакетная обработка занимает весьма ограниченную часть. Для систем OLTP характерен регулярный поток довольно простых транзакций, играющих роль заказов, платежей, запросов и т. п. Важными требованиями для них являются:
высокая производительность обработки транзакций;
гарантированная доставка информации при удаленном доступе к БД по телекоммуникациям.
Системы поддержки принятия решений - DSS (Decision Support Systeq) - представляют собой другой тип информационных систем, в которых с помощью довольно сложных запросов производится отбор и анализ данных в различных разрезах: временных, географических и по другим показателям.
Обширный класс информационно-справочных систем основан на гипертекстовых документах и мультимедиа. Наибольшее развитие такие информационные системы получили в сети Интернет.
Класс офисных информационных систем нацелен на перевод бумажных документов в электронный вид, автоматизацию делопроизводства и управление документооборотом.
примечание
Следует отметить, что приводимая классификация по сфере применения в достаточной степени условна. Крупные информационные системы очень часто обладают признаками всех перечисленных выше классов. Кроме того, корпоративные информационные системы масштаба предприятия обычно состоят из ряда подсистем, относящихся к различным сферам применения.
Лекция 6
Классификация по способу организации
По способу организации групповые и корпоративные информационные системы подразделяются на следующие классы (рис. 1.3):
- системы на основе архитектуры файл-сервер; системы на основе архитектуры клиент-сервер; системы на основе многоуровневой архитектуры; системы на основе Интернет/интранеттехнологий.


Рис. 1.3. Деление информационных систем по способу организации
В любой информационной системе можно выделить необходимые функциональные компоненты (табл. 1.1), которые помогают понять ограничения различных архитектур Информационных систем. Рассмотрим более подробно особенности вариантой построения информационных приложений.
Таблица 1.1. Типовые функциональные компоненты информационной системы
Обозначение | Наименование | Характеристика |
PS | Presentation Services (средства представления) | Обеспечиваются устройствами, принимающими ввод от пользователя и отображающими то, что сообщает ему компонент логики представления PL, с использованием соответствующей программной поддержки |
PL | Presentation Logic (логика представления) | Управляет взаимодействием между пользователем и ЭВМ. Обрабатывает действия пользователя при выборе команды в меню, нажатии кнопки или выборе элемента из списка |
BL | Business or Application Logic (прикладная логика) | Набор правил для принятия решений, вычислений и операций, которые должно выполнить приложение |
DL | Data Logic (логика управления данными) | Операции с базой данных (SQL-операторы), которые нужно выполнить для реализации прикладной логики управления данными |
DS | Data Services (операции с БД) | Действия СУБД, вызываемые для выполнения логики управления данными, такие как манипулирование данными, определения данных, фиксация или откат транзакций и т. п. СУБД обычно компилирует SQL-предложения |
FS | File Services (файловые перации) | Дисковые операции чтения и записи данных для СУБД и других компонентов. Обычно являются функциями операционной системы (ОС) |
Архитектура файл-сервер
Архитектура файл-сервер не имеет сетевого разделения компонентов диалога PS и PL и использует компьютер для функций отображения, что облегчает построение графического интерфейса. Файл-сервер только извлекает данные из файлов, так что дополнительные пользователи и приложения добавляют лишь незначительную нагрузку на центральный процессор. Каждый новый клиент добавляет вычислительную мощность к сети.
Объектами разработки в файл-серверном приложении являются компоненты приложения, определяющие логику диалога PL, а также логику обработки BL и управления данными DL. Разработанное приложение реализуется либо в виде законченного загрузочного модуля, либо в виде специального кода для интерпретации.
Однако такая архитектура имеет существенный недостаток: при выполнении некоторых запросов к базе данных клиенту могут передаваться большие объемы данных, загружая сеть и приводя к непредсказуемости времени реакции. Значительный сетевой трафик особенно сильно сказывается при организации удаленного доступа к базам данных на файл-сервере через низкоскоростные каналы связи. Одним из вариантов устранения данного недостатка является удаленное управление файл-серверным приложением в сети. При этом в локальной сети размещается сервер приложений, совмещенный с телекоммуникационным сервером (обычно называемым сервером доступа), в среде которого выполняются обычные файл-серверные приложения. Особенность состоит в том, что диалоговый ввод-вывод поступает от удаленных клиентов через телекоммуникации. Приложения не должны быть слишком сложными, иначе велика вероятность перегрузки сервера, или же нужна очень мощная платформа для сервера приложений.
примечание
Одним из традиционных средств, на основе которых создаются файл-серверные системы, являются локальные СУБД. Однако такие системы, как правило, не отвечают требованиям обеспечения целостности данных (в частности, они не поддерживают транзакции). Поэтому при их использовании задача обеспечения целостности данных возлагается на программы клиентов, что приводит к усложнению клиентских приложений. Однако эти инструменты привлекают своей простотой, удобством использования и доступностью. Поэтому файл-серверные информационные системы до сих пор представляют интерес для малых рабочих групп и, более того, нередко используются в качестве информационных систем масштаба предприятия.
Архитектура клиент-сервер
Архитектура клиент-сервер предназначена для разрешения проблем файл-серверных приложений путем разделения компонентов приложения и размещения их там, где они будут функционировать наиболее эффективно. Особенностью архитектуры клиент-сервер является использование выделенных серверов баз данных, понимающих запросы на языке структурированных запросов SQL (Structured Query Language) и выполняющих поиск, сортировку и агрегирование информации. Отличительная черта серверов БД – наличие справочника данных, в котором записана структура БД, ограничения целостности данных, форматы и даже серверные процедуры обработки данных по вызову или по событиям в программе. Объектами разработки в таких приложениях помимо диалога и логики обработки являются, прежде всего, реляционная модель данных и связанный с ней набор SQL-операторов для типовых запросов к базе данных.
Большинство конфигураций клиент-сервер использует двухуровневую модель, в которой клиент обращается к услугам сервера. Предполагается, что диалоговые компоненты PS и PL размешаются на клиенте, что позволяет обеспечить графический интерфейс. Компоненты управления данными DS и FS размешаются на сервере, а диалог (PS, PL), логика BL и DL - на клиенте. Двухуровневое определение архитектуры клиент-сервер использует именно этот вариант: приложение работает у клиента. СУБД – на сервере (рис. 1.4.).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
