



Отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 2NF и каждый неключевой атрибут не транзитивно зависит от первичного ключа.
Можно произвести декомпозицию отношения СОТРУДНИКИ-ОТДЕЛЫ в два отношения СОТРУДНИКИ и ОТДЕЛЫ:
СОТРУДНИКИ (СОТР_НОМЕР, ОТД_НОМЕР)
Первичный ключ:
СОТР_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР -> ОТД_НОМЕР
ОТДЕЛЫ (ОТД_НОМЕР, СОТР_ЗАРП)
Первичный ключ:
ОТД_НОМЕР
Функциональные зависимости:
ОТД_НОМЕР -> СОТР_ЗАРП
Каждое из этих двух отношений находится в 3NF и свободно от отмеченных аномалий. Если отказаться от того ограничения, что отношение обладает единственным ключом, то определение 3NF примет следующую форму: отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 1NF, и каждый неключевой атрибут не является транзитивно зависимым от какого-либо ключа R. На практике третья нормальная форма схем отношений достаточна в большинстве случаев, и приведением к третьей нормальной форме процесс проектирования реляционной базы данных обычно заканчивается. Однако иногда полезно продолжить процесс нормализации.
8.1.3. Нормальная форма Бойса-Кодда
Рассмотрим следующий пример схемы отношения:
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, СОТР_ИМЯ, ПРО_НОМЕР, СОТР_ЗАДАН)
Возможные ключи:
СОТР_НОМЕР, ПРО_НОМЕР
СОТР_ИМЯ, ПРО_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР -> CОТР_ИМЯ
СОТР_НОМЕР -> ПРО_НОМЕР
СОТР_ИМЯ -> CОТР_НОМЕР
СОТР_ИМЯ -> ПРО_НОМЕР
СОТР_НОМЕР, ПРО_НОМЕР -> CОТР_ЗАДАН
СОТР_ИМЯ, ПРО_НОМЕР -> CОТР_ЗАДАН
В этом примере мы предполагаем, что личность сотрудника полностью определяется как его номером, так и именем (это снова не очень жизненное предположение, но достаточное для примера). В соответствии с определением 7 отношение СОТРУДНИКИ-ПРОЕКТЫ находится в 3NF. Однако тот факт, что имеются функциональные зависимости атрибутов отношения от атрибута, являющегося частью первичного ключа, приводит к аномалиям. Например, для того, чтобы изменить имя сотрудника с данным номером, согласованным образом, нам потребуется модифицировать все кортежи, включающие его номер.
Детерминант – любой атрибут, от которого полностью функционально зависит некоторый другой атрибут.
Отношение R находится в нормальной форме Бойса-Кодда (BCNF) в том и только в том случае, если каждый детерминант является возможным ключом.
Очевидно, что это требование не выполнено для отношения СОТРУДНИКИ-ПРОЕКТЫ. Можно произвести его декомпозицию к отношениям СОТРУДНИКИ и СОТРУДНИКИ-ПРОЕКТЫ:
СОТРУДНИКИ (СОТР_НОМЕР, СОТР_ИМЯ)
Возможные ключи:
СОТР_НОМЕР
СОТР_ИМЯ
Функциональные зависимости:
СОТР_НОМЕР -> CОТР_ИМЯ
СОТР_ИМЯ -> СОТР_НОМЕР
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР, СОТР_ЗАДАН)
Возможный ключ:
СОТР_НОМЕР, ПРО_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР, ПРО_НОМЕР -> CОТР_ЗАДАН
Возможна альтернативная декомпозиция, если выбрать за основу СОТР_ИМЯ. В обоих случаях получаемые отношения СОТРУДНИКИ и СОТРУДНИКИ-ПРОЕКТЫ находятся в BCNF, и им не свойственны отмеченные аномалии.
8.1.4. Четвертая нормальная форма
Рассмотрим пример следующей схемы отношения:
ПРОЕКТЫ (ПРО_НОМЕР, ПРО_СОТР, ПРО_ЗАДАН)
Отношение ПРОЕКТЫ содержит номера проектов, для каждого проекта список сотрудников, которые могут выполнять проект, и список заданий, предусматриваемых проектом. Сотрудники могут участвовать в нескольких проектах, и разные проекты могут включать одинаковые задания. Каждый кортеж отношения связывает некоторый проект с сотрудником, участвующим в этом проекте, и заданием, который сотрудник выполняет в рамках данного проекта (мы предполагаем, что любой сотрудник, участвующий в проекте, выполняет все задания, предусмотренные этим проектом). По причине сформулированных выше условий единственным возможным ключом отношения является составной атрибут ПРО_НОМЕР, ПРО_СОТР, ПРО_ЗАДАН, и нет никаких других детерминантов. Следовательно, отношение ПРОЕКТЫ находится в BCNF. Но при этом оно обладает недостатками: если, например, некоторый сотрудник присоединяется к данному проекту, необходимо вставить в отношение ПРОЕКТЫ столько кортежей, сколько заданий в нем предусмотрено.
В отношении R (A, B, C) существует многозначная зависимость R. A -> -> R. B в том и только в том случае, если множество значений B, соответствующее паре значений A и C, зависит только от A и не зависит от С. В отношении «ПРОЕКТЫ» существуют следующие две многозначные зависимости:
ПРО_НОМЕР -> -> ПРО_СОТР
ПРО_НОМЕР -> -> ПРО_ЗАДАН
Легко показать, что в общем случае в отношении R (A, B, C) существует многозначная зависимость R. A -> -> R. B в том и только в том случае, когда существует многозначная зависимость R. A -> -> R. C. Дальнейшая нормализация отношений, подобных отношению ПРОЕКТЫ, основывается на следующей теореме:
Теорема Фейджина. Отношение R (A, B, C) можно спроецировать без потерь в отношения R1 (A, B) и R2 (A, C) в том и только в том случае, когда существует MVD A -> -> B | C. Под проецированием без потерь понимается такой способ декомпозиции отношения, при котором исходное отношение полностью и без избыточности восстанавливается путем естественного соединения полученных отношений.
Отношение R находится в четвертой нормальной форме (4NF) в том и только в том случае, если в случае существования многозначной зависимости A -> -> B все остальные атрибуты R функционально зависят от A.
В нашем примере можно произвести декомпозицию отношения ПРОЕКТЫ в два отношения ПРОЕКТЫ-СОТРУДНИКИ и ПРОЕКТЫ-ЗАДАНИЯ:
ПРОЕКТЫ-СОТРУДНИКИ (ПРО_НОМЕР, ПРО_СОТР)
ПРОЕКТЫ-ЗАДАНИЯ (ПРО_НОМЕР, ПРО_ЗАДАН)
Оба эти отношения находятся в 4NF и свободны от отмеченных аномалий.
8.1.5. Пятая нормальная форма
Во всех рассмотренных до этого момента нормальных формах производилась декомпозиция одного отношения в два. Иногда это сделать не удается, но возможна декомпозиция в большее число отношений, каждое из которых обладает лучшими свойствами. Рассмотрим, например, отношение
СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ (СОТР_НОМЕР, ОТД_НОМЕР, ПРО_НОМЕР)
Предположим, что один и тот же сотрудник может работать в нескольких отделах и работать в каждом отделе над несколькими проектами. Первичным ключом этого отношения является полная совокупность его атрибутов, отсутствуют функциональные и многозначные зависимости. Поэтому отношение находится в 4NF. Однако в нем могут существовать аномалии, которые можно устранить путем декомпозиции в три отношения.
Отношение R (X, Y, ..., Z) удовлетворяет зависимости соединения * (X, Y, ..., Z) в том и только в том случае, когда R восстанавливается без потерь путем соединения своих проекций на X, Y, ..., Z.
Отношение R находится в пятой нормальной форме (нормальной форме проекции-соединения - PJ/NF) в том и только в том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R. Введем следующие имена составных атрибутов:
СО = {СОТР_НОМЕР, ОТД_НОМЕР}
СП = {СОТР_НОМЕР, ПРО_НОМЕР}
ОП = {ОТД_НОМЕР, ПРО_НОМЕР}
Предположим, что в отношении СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ существует зависимость соединения:
* (СО, СП, ОП)
На примерах легко показать, что при вставке и удалении кортежей могут возникнуть проблемы. Их можно устранить путем декомпозиции исходного отношения в три новых отношения:
СОТРУДНИКИ-ОТДЕЛЫ (СОТР_НОМЕР, ОТД_НОМЕР)
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР)
ОТДЕЛЫ-ПРОЕКТЫ (ОТД_НОМЕР, ПРО_НОМЕР)
Пятая нормальная форма – это нормальная последняя форма, которую можно получить путем декомпозиции. Ее условия достаточно нетривиальны, и на практике 5NF не используется. Заметим, что зависимость соединения является обобщением многозначной зависимости и функциональной зависимости.
8.1.6. Семантическое моделирование данных, ER-диаграммы
Широкое распространение реляционных СУБД и их использование в самых разнообразных приложениях показывает, что реляционная модель данных достаточна для моделирования предметных областей. Однако проектирование реляционной базы данных в терминах отношений на основе кратко рассмотренного нами механизма нормализации часто представляет собой очень сложный и неудобный для проектировщика процесс. При этом проявляется ограниченность реляционной модели данных. Модель не предоставляет достаточных средств для представления смысла данных. Семантика реальной предметной области должна независимым от модели способом представляться в голове проектировщика. В частности, это относится к упоминавшейся нами проблеме представления ограничений целостности. Для многих приложений трудно моделировать предметную область на основе плоских таблиц. В ряде случаев на самой начальной стадии проектирования проектировщику приходится производить насилие над собой, чтобы описать предметную область в виде одной (возможно, даже ненормализованной) таблицы. Хотя весь процесс проектирования происходит на основе учета зависимостей, реляционная модель не предоставляет каких-либо средств для представления этих зависимостей. Несмотря на то, что процесс проектирования начинается с выделения некоторых существенных для приложения объектов предметной области ("сущностей") и выявления связей между этими сущностями, реляционная модель данных не предлагает какого-либо аппарата для разделения сущностей и связей.
8.2. Семантические модели данных
Потребности проектировщиков баз данных в более удобных и мощных средствах моделирования предметной области вызвали к жизни направление семантических моделей данных. Притом, что любая развитая семантическая модель данных, как и реляционная модель, включает структурную, манипуляционную и целостную части, главным назначением семантических моделей является обеспечение возможности выражения семантики данных. Прежде чем мы коротко рассмотрим особенности одной из распространенных семантических моделей, остановимся на их возможных применениях. Наиболее часто на практике семантическое моделирование используется на первой стадии проектирования базы данных. При этом в терминах семантической модели производится концептуальная схема базы данных, которая затем вручную преобразуется к реляционной (или какой-либо другой) схеме. Этот процесс выполняется под управлением методик, в которых достаточно четко оговорены все этапы такого преобразования. Менее часто реализуется автоматизированная компиляция концептуальной схемы в реляционную схему. При этом известны два подхода: на основе явного представления концептуальной схемы как исходной информации для компилятора и построения интегрированных систем проектирования с автоматизированным созданием концептуальной схемы на основе интервью с экспертами предметной области. И в том, и в другом случае в результате производится реляционная схема базы данных в третьей нормальной форме (более точно следовало бы сказать, что автору неизвестны системы, обеспечивающие более высокий уровень нормализации). Наконец, третья возможность, которая еще не вышла (или только выходит) за пределы исследовательских и экспериментальных проектов, – это работа с базой данных в семантической модели, т. е. СУБД, основанные на семантических моделях данных. При этом снова рассматриваются два варианта: обеспечение пользовательского интерфейса на основе семантической модели данных с автоматическим отображением конструкций в реляционную модель данных (это задача примерно такого же уровня сложности, как автоматическая компиляция концептуальной схемы базы данных в реляционную схему) и прямая реализация СУБД, основанная на какой-либо семантической модели данных. Наиболее близко ко второму подходу находятся современные объектно-ориентированные СУБД, модели данных которых по многим параметрам близки к семантическим моделям (хотя в некоторых аспектах они более мощны, а в некоторых – более слабы).

8.2.1. Модель Entity-Relationship (Сущность-Связи)
Семантическую модель данных – модель «Сущность-Связи» часто ее называют кратко ER-моделью. На использовании разновидностей ER-модели основано большинство современных подходов к проектированию баз данных (главным образом, реляционных). Модель была предложена в 1976 году. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных. Среди множества разновидностей ER-моделей одна из наиболее развитых моделей применяется в системе CASE фирмы ORACLE. Основными понятиями ER-модели являются сущность, связь и атрибут. Сущность – это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности. При этом имя сущности – это имя типа, а не некоторого конкретного экземпляра этого типа. Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа.
Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности (это требование в некотором роде аналогично требованию отсутствия кортежей-дубликатов в реляционных таблицах). Связь – это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). В любой связи выделяются два конца (в соответствии с существующей парой связываемых сущностей), на каждом из которых указывается имя конца связи, степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т. е. любой ли экземпляр данной сущности должен участвовать в данной связи). Связь представляется в виде линии, связывающей две сущности или ведущей от сущности к ней же самой. При этом в месте "стыковки" связи с сущностью используются трех точечный вход в прямоугольник сущности, если для этой сущности в связи могут использоваться много (many) экземпляров сущности, и одноточечный вход, если в связи может участвовать только один экземпляр сущности. Обязательный конец связи изображается сплошной линией, а необязательный – прерывистой линией. Как и сущность, связь – это типовое понятие, все экземпляры обеих пар связываемых сущностей подчиняются правилам связывания. В изображенном ниже примере связь между сущностями БИЛЕТ и ПАССАЖИР связывает билеты и пассажиров. При том конец сущности с именем «для» позволяет связывать с одним пассажиром более одного билета, причем каждый билет должен быть связан с каким-либо пассажиром. Конец сущности с именем «имеет» означает, что каждый билет может принадлежать только одному пассажиру, причем пассажир не обязан иметь хотя бы один билет.
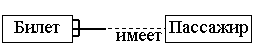 |
Лаконичной устной трактовкой изображенной диаграммы является следующая фраза: «Каждый БИЛЕТ предназначен для одного и только одного ПАССАЖИРА; каждый ПАССАЖИР может иметь один или более БИЛЕТОВ». На следующем примере изображена рекурсивная связь, связывающая сущность ЧЕЛОВЕК с ней же самой. Конец связи с именем "сын" определяет тот факт, что у одного отца может быть более чем один сын. Конец связи с именем "отец" означает, что не у каждого человека могут быть сыновья.
 |
Лаконичной устной трактовкой изображенной диаграммы является следующая фраза: «Каждый ЧЕЛОВЕК приходится сыном одному и только одному ЧЕЛОВЕКУ; каждый ЧЕЛОВЕК может приходиться отцом для одного или более ЛЮДЕЙ. Атрибутом сущности является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности. Имена атрибутов заносятся в прямоугольник, изображающий сущность, под именем сущности и изображаются малыми буквами, возможно, с примерами. Пример: уникальным идентификатором сущности является атрибут, комбинация атрибутов, комбинация связей или комбинация связей и атрибутов, уникально отличающая любой экземпляр сущности от других экземпляров сущности того же типа.
8.2.2. Нормальные формы ER-схем
Как и в реляционных схемах баз данных, в ER-схемах вводится понятие нормальных форм, причем их смысл очень близко соответствует смыслу нормальных реляционных форм. Заметим, что формулировки нормальных форм ER-схем делают более понятным смысл нормализации реляционных схем. Мы приведем только очень краткие и неформальные определения трех первых нормальных форм. В первой нормальной форме ER-схемы устраняются повторяющиеся атрибуты или группы атрибутов, то есть производится выявление неявных сущностей, "замаскированных" под атрибуты. Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального идентификатора. Эта часть уникального идентификатора определяет отдельную сущность. В третьей нормальной форме устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности.
8.2.3. Более сложные элементы ER-модели
Мы остановились только на самых основных и наиболее очевидных понятиях ER-модели данных. К числу более сложных элементов модели относятся следующие:
· Подтипы и супертипы сущностей. Как в языках программирования с развитыми типовыми системами (например, в языках объектно-ориентированного программирования), вводится возможность наследования типа сущности, исходя из одного или нескольких супертипов. Интересные нюансы связаны с необходимостью графического изображения этого механизма.
· Связи "many-to-many". Иногда бывает необходимо связывать сущности таким образом, что с обоих концов связи могут присутствовать несколько экземпляров сущности (например, все члены кооператива сообща владеют имуществом кооператива). Для этого вводится разновидность связи "многие-со-многими".
· Уточняемые степени связи. Иногда бывает полезно определить возможное количество экземпляров сущности, участвующих в данной связи (например, служащему разрешается участвовать не более чем в трех проектах одновременно). Для выражения этого семантического ограничения разрешается указывать на конце связи ее максимальную или обязательную степень.
· Каскадные удаления экземпляров сущностей. Некоторые связи бывают настолько сильными (конечно, в случае связи "один-ко-многим"), что при удалении опорного экземпляра сущности (соответствующего концу связи "один") нужно удалить и все экземпляры сущности, соответствующие концу связи "многие". Соответствующее требование "каскадного удаления" можно сформулировать при определении сущности.
· Домены. Как и в случае реляционной модели данных полезна возможность определения потенциально допустимого множества значений атрибута сущности (домена).
Эти и другие, более сложные элементы модели данных "Сущность-Связи" делают ее существенно более мощной, но одновременно несколько усложняют ее использование. Конечно, при реальном использовании ER-диаграмм для проектирования баз данных необходимо ознакомиться со всеми возможностями. В нашей лекции мы немного подробнее разберем только один из упомянутых элементов – подтип сущности. Сущность может быть расщеплена на два или более взаимно исключающих подтипа. Каждый из подтипов включает общие атрибуты и/или связи. Эти общие атрибуты и/или связи явно определяются один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе под-типизация может продолжаться на более низких уровнях, но опыт показывает, что в большинстве случаев оказывается достаточно двух-трех уровней. Сущность, на основе которой определяются подтипы, называется супертипом. Подтипы должны образовывать полное множество, то есть любой экземпляр супертипа должен относиться к некоторому подтипу. Иногда для полноты приходится определять дополнительный подтип ПРОЧИЕ.
8.2.4. Получение реляционной схемы из ER-схемы
Процесс получения реляционной схемы складывается из нескольких этапов.
1. Каждая простая сущность превращается в таблицу. Простая сущность – сущность, не являющаяся подтипом и не имеющая подтипов. Имя сущности становится именем таблицы.
2. Каждый атрибут становится возможным столбцом с тем же именем; может выбираться более точный формат. Столбцы, соответствующие необязательным атрибутам, могут содержать неопределенные значения; столбцы, соответствующие обязательным атрибутам, – не могут.
3. Компоненты уникального идентификатора сущности превращаются в первичный ключ таблицы. Если имеется несколько возможных уникальных идентификаторов, выбирается наиболее используемый идентификатор. Если в состав уникального идентификатора входят связи, к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (этот процесс может продолжаться рекурсивно). Для именования этих столбцов используются имена концов связей и/или имена сущностей.
4. Связи «многие к одному» (и «один к одному») становятся внешними ключами. Т. е. делается копия уникального идентификатора с конца связи "один", и соответствующие столбцы составляют внешний ключ. Необязательные связи соответствуют столбцам, допускающим неопределенные значения; обязательные связи – столбцам, не допускающим неопределенные значения.
5. Индексы создаются для первичного ключа (уникальный индекс), внешних ключей и тех атрибутов, на которых предполагается в основном базировать запросы.
6. Если в концептуальной схеме присутствовали подтипы, то возможны два способа: либо все подтипы в одной таблице (а), либо для каждого подтипа имеется отдельная таблица (б). При применении способа (а) таблица создается для наиболее внешнего супертипа, а для подтипов могут создаваться представления. В таблицу добавляется, по крайней мере, один столбец, содержащий код ТИПА; он становится частью первичного ключа. При использовании метода (б) для каждого подтипа первого уровня (для нижних уровней – представления) супертип воссоздается с помощью представления UNION (из всех таблиц подтипов выбираются общие столбцы супертипа).
Все в одной таблице | Таблица – на подтип |
Преимущества | |
Все хранится вместе. Легкий доступ к супертипу и подтипам. Требуется меньше таблиц. | Ясные правила подтипов. Программы работают только с нужными таблицами |
Недостатки | |
Требуется дополнительная логика работы с разными наборами столбцов и разными ограничениями. Потенциально узкое место (блокировки). Столбцы подтипов должны быть необязательными. В некоторых СУБД для хранения неопределенных значений требуется дополнительная память. | Слишком много таблиц. Смущающие столбцы в представлении UNION. Потенциальная потеря производительности при работе через UNION. Над супертипом невозможны модификации. |
7. Имеется два способа работы при наличии исключающих связей: либо общий домен (а), либо явные внешние ключи (б).
Если остающиеся внешние ключи все в одном домене, т. е. имеют общий формат (способ (а)), то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различения связей, покрываемых дугой исключения. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи. Если результирующие внешние ключи не относятся к одному домену, то для каждой связи, покрываемой дугой исключения, создаются явные столбцы внешних ключей; все эти столбцы могут содержать неопределенные значения.
Общий домен | Явные внешние ключи |
Преимущества | |
Нужно только два столбца. | Явные условия соединения. |
Недостатки | |
Оба дополнительных атрибута должны использоваться в соединениях. | Слишком много столбцов. |
8.2.5. Альтернативные модели сущностей
Не рекомендуемая модель.
Рекомендуемая модель при условии реального существования подтипов.
Рекомендуемая модель при условии наличия осмысленного супертипа D).
9. Системы управления базами данных следующего поколения
В этом разделе очень кратко рассматриваются основные направления исследований и разработок в области так называемых постреляционных систем, то есть систем, относящихся к следующему поколению (хотя термин "next generation DBMS" зарезервирован для некоторого подкласса современных систем). Хотя отнесение СУБД к тому или иному классу в настоящее время может быть выполнено только условно (например, иногда объектно-ориентированную СУБД O2 относят к системам следующего поколения), можно отметить три направления в области СУБД следующего поколения. Чтобы не изобретать названий, будем обозначать их именами наиболее характерных СУБД.
Направление POSTGRES. Основная характеристика: максимальное следование (насколько это возможно с учетом новых требований) известным принципам организации СУБД (если не считать коренной переделки системы управления внешней памятью).
Направление Exodus/Genesis. Основная характеристика: создание собственно не системы, а генератора систем, наиболее полно соответствующих потребностям приложений. Решение достигается путем создания наборов модулей со стандартизованными интерфейсами, причем идея распространяется вплоть до самых базисных слоев системы.
Направление Starburst. Основная характеристика: достижение расширяемости системы и ее способности приспосабливаться к нуждам конкретных приложений путем использования стандартного механизма управления правилами. По сути дела, система представляет собой некоторый интерпретатор системы правил и набор модулей-действий, вызываемых в соответствии с этими правилами. Можно изменять наборы правил (существует специальный язык задания правил) или изменять действия, подставляя другие модули с тем же интерфейсом.
В целом можно сказать, что СУБД следующего поколения – это прямые наследники реляционных систем. Тем не менее, различные направления систем третьего поколения стоит рассмотреть отдельно, поскольку они обладают некоторыми разными характеристиками.
9.1. Ориентация на расширенную реляционную модель
Одним из основных положений реляционной модели данных является требование нормализации отношений: поля кортежей могут содержать лишь атомарные значения. Для традиционных приложений реляционных СУБД – банковских систем, систем резервирования и т. д. – это вовсе не ограничение, а даже преимущество, позволяющее проектировать экономные по памяти БД с предельно понятной структурой. Запросы с соединениями в таких системах сравнительно редки, для динамической поддержки целостности используются соответствующие средства SQL. Однако с появлением эффективных реляционных СУБД их стали пытаться использовать и в менее традиционных прикладных системах – САПР, системах искусственного интеллекта и т. д. Такие системы обычно оперируют сложно структурированными объектами, для реконструкции которых из плоских таблиц реляционной БД приходится выполнять запросы, почти всегда требующие соединения отношений. В соответствии с требованиями разработчиков нетрадиционных приложений появилось направление исследований баз сложных объектов. Основной смысл этого направления состоит в том, что в руки проектировщиков даются настолько же мощные и гибкие средства структуризации данных, как те, которые были присущи иерархическим и сетевым системам базам данных. Однако важным отличием является то, что в системах баз данных, поддерживающих сложные объекты, сохраняется четкая граница между логическим и физическим представлениями таких объектов. В частности, для любого сложного объекта (произвольной сложности) должна обеспечиваться возможность перемещения или копирования его как единого целого из одной части базы данных в другую ее часть или даже в другую базу данных. Это очень обширная область исследований, в которой затрагиваются вопросы моделей данных, структур данных, языков запросов, управления транзакциями, журнализации и т. д. Во многом эта область соприкасается с областью объектно-ориентированных БД. И в этой области настолько же плохо обстоят дела с теоретическим обоснованием. Близкое, но, вообще говоря, основанное на других принципах направление представлено системами баз данных, основанных на реляционной модели, в которой не обязательно поддерживается первая нормальная форма отношений. Напомним, что требование атомарности значений, которые могут храниться в элементах кортежей отношений, является базовым требованием классической реляционной модели. Приведение исходного табличного представления предметной области к "плоскому" виду является обязательным первым шагом в процессе проектирования реляционной базы данных на основе принципов нормализации. С другой стороны, абсолютно очевидно, что такое "уплощение" таблиц, хотя и является необходимым условием получения не избыточной и "правильной" схемы реляционной базы данных, в дальнейшем потенциально вызывает выполнение многочисленных соединений, которые могут свести к нулю все преимущества "хорошей" схемы базы данных. Так вот, в "ненормализованных" реляционных моделях данных допускается хранение в качестве элемента кортежа кортежей (записей), массивов (регулярных индексированных множеств данных), регулярных множеств элементарных данных, а также отношений. При этом такая вложенность может быть, по существу, неограниченной. Если внимательно продумать эти идеи, то станет понятно, что они приводят (только) к логически обособленным (от физического представления) возможностям иерархической модели данных. Но это уже не так уж и мало, если учесть, что к настоящему времени фактически полностью сформировано теоретическое основание реляционных баз данных с отказом от нормализации. Скорее всего, в этой теории все еще имеются темные места. Они наличествуют даже в классической реляционной теории. Но, тем не менее, большинство известных теоретических результатов реляционной теории уже распространено на ненормализованную модель, и даже такой пурист реляционной модели, как Date, полагает возможным использование ограниченной и контролируемой реляционной модели в SQL-3.
9.2. Абстрактные типы данных
Одной из наиболее известных СУБД третьего поколения является система POSTGRES. В POSTGRES реализованы многие интересные средства: поддерживается временная модель хранения и доступа к данным (см. ниже) и в связи с этим абсолютно пересмотрен механизм журнализации изменений, откатов транзакций и восстановления БД после сбоев; обеспечивается мощный механизм ограничений целостности; поддерживаются ненормализованные отношения (работа в этом направлении началась еще в среде INGRES), хотя и довольно странным способом: в поле отношения может храниться динамически выполняемый запрос к БД. Одно свойство системы POSTGRES сближает ее со свойствами объектно-ориентированных СУБД. В POSTGRES допускается хранение в полях отношений данных абстрактных, определяемых пользователями типов. Это обеспечивает возможность внедрения поведенческого аспекта в БД, то есть решает ту же задачу, что и ООБД, хотя семантические возможности модели данных POSTGRES существенно слабее, чем у объектно-ориентированных моделей. Основная разница состоит в том, что системы класса POSTGRES не предполагают наличия языка программирования, одинаково понимаемого как внешней системой программирования, так и системой управления базами данных. Если с использованием такой системы программирования определяются типы данных, хранимых в базе данных, то СУБД оказывается не в состоянии контролировать безопасность этих определений, т. е. то отсутствует гарантия, что при выполнении процедур абстрактных типов данных не будет разрушена сама база данных. Заметим, что в середине 1995 г. компания Sun Microsystems объявила о выпуске нового продукта – языка и семейства интерпретаторов под названием Java. Язык Java является расширенным подмножеством языка C++. Основные изменения касаются того, что язык является пооператорным интерпретатором (в стиле языка Бейсик), а программы, написанные на языке Java, гарантированно безопасны. В частности, для этого из языка удалена арифметика указателей. В то же время Java остается мощным объектно-ориентированным языком, включающим развитые средства определения абстрактных типов данных. Компания Sun продвигает язык Java с целью расширения возможностей службы Всемирной Паутины (World Wide Web) Internet. Основная идея состоит в том, что из сервера WWW в клиенты передаются не данные, а объекты, методы которых запрограммированы на языке Java и интерпретируются на стороне клиента. Этот подход, в частности, решает проблему не стандартизованного представления мультимедийной информации. Интерпретируемый язык типа Java может быть успешно применен и в системах баз данных, допускающих хранение данных с типами, определенными пользователями.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
