



2.2.4. Журнализация
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции. Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД. Журнал – это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда - минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода. Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя. Самая простая ситуация восстановления – индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции. При этом требуется производить откат транзакции с помощью выполнения обратных операций, следуя от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу). При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для того, чтобы этого добиться, сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом. Более подробно мы рассмотрим это в соответствующей лекции. Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Грубо говоря, архивная копия - это полная копия БД к моменту начала заполнения журнала (имеется много вариантов более гибкой трактовки смысла архивной копии). Конечно, для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. Как уже отмечалось, к сохранности журнала во внешней памяти в СУБД предъявляются особо повышенные требования. Тогда восстановление БД состоит в том, что, исходя из архивной копии по журналу, воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе, можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления. Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным.
2.2.5. Поддержка языков БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL – Schema Definition Language) и язык манипулирования данными (DML – Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т. е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, то есть операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные. Мы рассмотрим более подробно языки ранних СУБД в следующей лекции. В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). В нескольких лекциях этого курса язык SQL будет рассматриваться достаточно подробно, а пока мы перечислим основные функции реляционной СУБД, поддерживаемые на "языковом" уровне (т. е. функции, поддерживаемые при реализации интерфейса SQL). Прежде всего, язык SQL сочетает средства SDL и DML, т. е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД – именование таблиц и их столбцов) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов. Язык SQL содержит специальные средства определения ограничений целостности БД. Опять же, ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т. е. при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код. Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне. Наконец, авторизация доступа к объектам БД производится также на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В число этих полномочий входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне. Более точное описание возможных реализаций этих функций на основе языка SQL будет приведено в лекциях, посвященных языку SQL и его реализации.
2.3. Типовая организация современной СУБД
Естественно, организация типичной СУБД и состав ее компонентов соответствует рассмотренному нами набору функций. Напомним, что мы выделили следующие основные функции СУБД:
- управление данными во внешней памяти; управление буферами оперативной памяти; управление транзакциями; журнализация и восстановление БД после сбоев; поддержание языков БД.
Логически в современной реляционной СУБД можно выделить наиболее внутреннюю часть – ядро СУБД (часто его называют Data Base Engine), компилятор языка БД (обычно SQL), подсистему поддержки времени выполнения, набор утилит. В некоторых системах эти части выделяются явно, в других – нет, но логически такое разделение можно провести во всех СУБД. Ядро СУБД отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями и журнализацию. Соответственно, можно выделить такие компоненты ядра (по крайней мере, логически, хотя в некоторых системах эти компоненты выделяются явно), как менеджер данных, менеджер буферов, менеджер транзакций и менеджер журнала. Как можно было понять из первой части этой лекции, функции этих компонентов взаимосвязаны, и для обеспечения корректной работы СУБД все эти компоненты должны взаимодействовать по тщательно продуманным и проверенным протоколам. Ядро СУБД обладает собственным интерфейсом, не доступным пользователям напрямую и используемым в программах, производимых компилятором SQL (или в подсистеме поддержки выполнения таких программ) и утилитах БД. Ядро СУБД является основной резидентной частью СУБД. При использовании архитектуры "клиент-сервер" ядро является основной составляющей серверной части системы. Основной функцией компилятора языка БД является компиляция операторов языка БД в некоторую выполняемую программу. Основной проблемой реляционных СУБД является то, что языки этих систем (а это, как правило, SQL) являются непроцедурными, т. е. в операторе такого языка специфицируется некоторое действие над БД, но эта спецификация не является процедурой, а лишь описывает в некоторой форме условия совершения желаемого действия (вспомните примеры из первой лекции). Поэтому компилятор должен решить, каким образом выполнять оператор языка прежде, чем произвести программу. Применяются достаточно сложные методы оптимизации операторов, которые мы подробно рассмотрим в следующих лекциях. Результатом компиляции является выполняемая программа, представляемая в некоторых системах в машинных кодах, но более часто в выполняемом внутреннем машинно-независимом коде. В последнем случае реальное выполнение оператора производится с привлечением подсистемы поддержки времени выполнения, представляющей собой, по сути дела, интерпретатор этого внутреннего языка. Наконец, в отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно выполнять с использованием языка БД, например, загрузка и выгрузка БД, сбор статистики, глобальная проверка целостности БД и т. д. Утилиты программируются с использованием интерфейса ядра СУБД, а иногда даже с проникновением внутрь ядра.
3. Модели данных
С ростом популярности СУБД в 70-80-х годах появилось множество различных моделей данных. У каждой из них имелись свои достоинства и недостатки, которые сыграли ключевую роль в развитии реляционной модели данных, появившейся во многом благодаря стремлению упростить и упорядочить первые модели данных. Среди моделей данных различают
ü системы управления файлами;
ü иерархические модели данных;
ü сетевые модели данных;
ü реляционные модели данных;
ü постреляционные модели данных;
ü многомерные модели данных;
ü объектно-ориентированные модели данных.
3.1. Системы управления файлами
До появления СУБД все данные, которые содержались в компьютерной системе постоянно, хранились в виде отдельных файлов. Система управления файлами, которая обычно является частью операционной системы компьютера, следила за именами файлов и местами их расположения. В системах управления файлами модели данных в современном понимании этого слова, как правило, не использовались; эти системы ничего не знали о внутреннем содержимом файлов. Для такой системы файл, содержащий документ текстового процессора, ничем не отличается от файла, содержащего данные о начисленной зарплате.
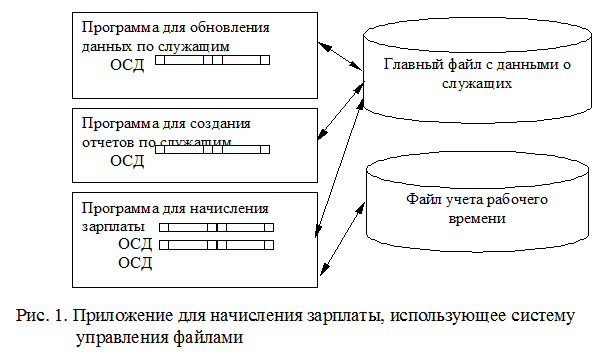
Знание о содержимом файла – какие данные в нём хранятся и какова их структура – было уделом прикладных программ, использующих этот файл, что иллюстрирует рис.1. В приложении для начисления зарплаты каждая из программ, обрабатывающих файл с информацией о служащих, содержит в себе описание структуры данных (ОСД), хранящихся в этом файле. Когда структура данных изменялась – например, в случае добавления нового элемента данных для каждого служащего, – необходимо было модифицировать каждую из программ, обращавшихся к файлу. Со временем количество файлов и программ росло, и на сопровождение существующих приложений приходилось затрачивать всё больше и больше усилий, что замедляло разработку новых приложений.
По своему характеру системы управления файлами напоминали современные диспетчеры файлов, такие как Norton Commander.
Проблемы сопровождения больших систем, основанных на файлах, привели в конце 60-х годов к появлению СУБД. В основе СУБД лежала простая идея: изъять из программ определение структуры содержимого файла и хранить её вместе с данными в базе данных.
3.2. Иерархические СУБД
Одной из наиболее важных сфер применения первых СУБД было планирование производства для компаний, занимающихся выпуском продукции. Например, если автомобильная компания хотела выпустить 10000 машин одной модели и 5000 машин другой модели, ей необходимо было знать, сколько деталей следует заказать у своих поставщиков. Чтобы ответить на этот вопрос, необходимо определить, из каких деталей состоят эти части и т. д. Например, машина состоит из двигателя, корпуса и ходовой части; двигатель состоит из клапанов, цилиндров, свеч и т. д. Работа со списками составных частей была как будто специально предназначена для компьютеров.
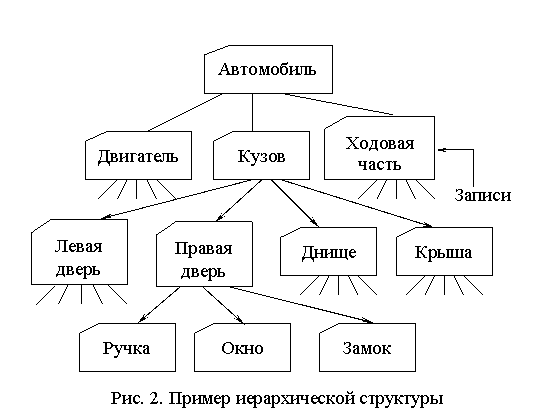
Список составных частей изделия по своей природе является иерархической структурой. Для хранения данных, имеющих такую структуру, была разработана иерархическая модель данных, которую иллюстрирует рис. 2.
В этой модели каждая запись базы данных представляла конкретную деталь. Между записями существовали отношения предок/потомок, связывающие каждую часть с деталями, входящими в неё.
Чтобы получить доступ к данным, содержащимся в базе данных, программа могла:
· найти конкретную деталь (правую дверь) по её номеру;
· перейти "вниз" к первому потомку (ручка двери);
· перейти "вверх" к предку (корпус);
· перейти "в сторону" к другому потомку (правая дверь).
Таким образом, для чтения данных из иерархической базы данных требовалось перемещаться по записям, за один раз переходя на одну запись вверх, вниз или в сторону.
 |
Одной из наиболее популярных иерархических СУБД была Information Management System (IMS) компании IBM, появившаяся в 1968 году. Ниже перечислены преимущества IMS и реализованной в ней иерархической модели.
· Простота модели. Принцип построения IMS был легок для понимания. Иерархия базы данных напоминала структуру компании или генеалогическое дерево.
· Использование отношений предок/потомок. СУБД IMS позволяла легко представлять отношения предок/потомок, например: "А является частью В" или "А владеет В".
· Быстродействие. В СУБД IMS отношения предок/потомок были реализованы в виде физических указателей из одной записи на другую, вследствие чего перемещение по базе данных происходило быстро. Поскольку структура данных в этой СУБД отличалась простотой, IMS могла размещать записи предков и потомков на диске рядом друг с другом, что позволяло свести к минимуму количество операций записи-чтения.
СУБД IMS все ещё является одной из наиболее распространённых СУБД для больших ЭВМ компании IBM. Доля мэйнфреймов этой компании, на которых используется данная СУБД, превышает 25%.
3.3.
 |
Сетевые базы данных
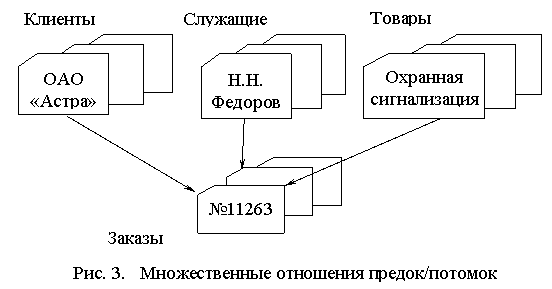
Если структура данных оказывалась сложнее, чем обычная иерархия, простота структуры иерархической базы данных становилась её недостатком. Например, в базе данных для хранения заказов один заказ мог участвовать в трёх различных отношениях предок/потомок, связывающих заказ с клиентом, разместившим его, со служащим, принявшим его, и с заказанным товаром, что иллюстрирует рис. 3. Такие структуры данных не соответствовали строгой иерархии IMS.
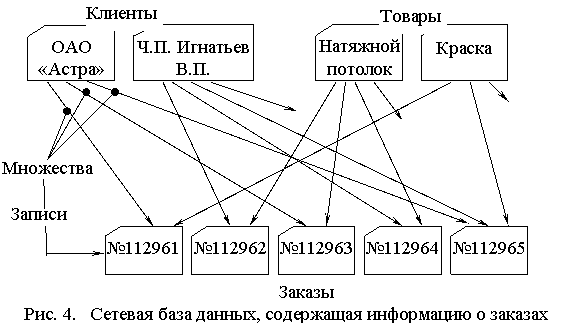 |
В связи с этим для таких приложений, как обработка заказов, была разработана новая сетевая модель данных. Она являлась улучшенной иерархической моделью, в которой одна запись могла участвовать в нескольких отношениях предок/потомок, как показано на рис. 4. В сетевой модели такие отношения назывались множествами. В 1971 году на конференции по языкам систем данных был опубликован официальный стандарт сетевых баз данных, который известен как модель CODASYL. Компания IBM не стала разрабатывать собственную сетевую СУБД и вместо этого продолжала наращивать возможность IMS. Но в 70-х годах независимые производители программного обеспечения реализовали сетевую модель в таких продуктах, как IDMS компании Cullinet, Total компании Cincom и СУБД Adabas, которые приобрели большую популярность.
Сетевые базы данных обладали рядом преимуществ:
ü Гибкость. Множественные отношения предок/потомок позволяли сетевой базе данных хранить данные, структура которых была сложнее простой иерархии.
ü Стандартизация. Появление стандарта CODASYL популярность сетевой модели, а такие поставщики мини-компьютеров, как Digital Equipment Corporation и Data General, реализовали сетевые СУБД.
ü Быстродействие. Вопреки своей большой сложности, сетевые базы данных достигали быстродействия, сравнимого с быстродействием иерархических баз данных. Множества были представлены указателями на физические записи данных, и в некоторых системах администратор мог задать кластеризацию данных на основе множества отношений.
Конечно, у сетевых баз данных были недостатки. Как и иерархические базы данных, сетевые базе данных были очень жесткими. Наборы отношений и структуру записей приходилось задавать наперёд. Изменение структуры базы данных обычно означало перестройку всей базы данных.
Как иерархическая, так и сетевая база данных были инструментами программистов. Чтобы получить ответ на вопрос типа "Какой товар наиболее часто заказывает компания , программисту приходилось писать программу для навигации по базе данных. Реализация пользовательских запросов часто затягивалась на недели и месяцы, и к моменту появления программы информация, которую она предоставляла, часто оказывалась бесполезной.
3.4. Реляционная модель данных
Недостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 году и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы.
К сожалению, практическое определение понятия «реляционная база данных» оказалось гораздо более расплывчатым, чем точное математическое определение, данное этому термину Коддом в 1970 году. В первых реляционных СУБД не были реализованы некоторые из ключевых частей модели Кодда, и этот пробел был восполнен только впоследствии. По мере роста популярности реляционной концепции реляционными стали называться многие базы данных, которые на деле таковыми не являлись.
В ответ на неправильное использование термина "реляционный" Кодд в 1985 году написал статью, где сформулировал 12 правил, которым должна удовлетворять любая база данных, претендующая на звание реляционной. С тех пор двенадцать правил Кодда считаются определением реляционной СУБД. Однако можно сформулировать и более простое определение:
Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами.
Приведенное определение не оставляет места встроенным указателям, имеющимся в иерархических и сетевых СУБД. Несмотря на это, реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах.
3.4.1. Таблицы
В реляционной базе данных информация организована в виде таблиц, разделённых на строки и столбцы, на пересечении которых содержатся значения данных. У каждой таблицы имеется уникальное имя, описывающее её содержимое. Более наглядно структуру таблицы иллюстрирует рис 6., на котором изображена таблица OFFICES. Каждая горизонтальная строка этой таблицы представляет отдельную физическую сущность – один офис. Пять строк таблицы вместе представляют все пять офисов компании. Все данные, содержащиеся в конкретной строке таблицы, относятся к офису, который описывается этой строкой.
 |
Каждый вертикальный столбец таблицы «Офисы» представляет один элемент данных для каждого из офисов. Например, в столбце «Город» содержатся названия городов, в которых расположены офисы. В столбце «Продажи» содержатся объёмы продаж, обеспечиваемые офисами.
На пересечении каждой строки с каждым столбцом таблицы содержится в точности одно значение данных. Например, в строке, представляющей ярославский офис, в столбце «Город» содержится значение «Ярославль». В столбце «Продажи» той же строки содержится значение 4,692,000.00, которое является объёмом продаж ярославского офиса с начала года.
Все значения, содержащиеся в одном и том же столбце, являются данными одного типа. Например, в столбце «Город» содержатся только слова, в столбце «Продажи» содержатся денежные суммы, а в столбце «Рук.» содержатся целые числа, представляющие идентификаторы служащих. Множество значений, которые могут содержаться в столбце, называется доменом этого столбца. Доменом столбца «Город» является множество названий городов. Доменом столбца «Продажи» является любая денежная сумма.
У каждого столбца в таблице есть своё имя, которое обычно служит заголовком столбца. Все столбцы в одной таблице должны иметь уникальные имена, однако разрешается присваивать одинаковые имена столбцам, расположенным в различных таблицах. На практике такие имена столбцов, как ИМЯ, АДРЕС, СТОИМОСТЬ, ПРОДАЖИ часто встречаются в различных таблицах одной базы данных.
Столбцы таблицы упорядочены слева направо, и их порядок определяется при создании таблицы. В любой таблице всегда есть как минимум один столбец. В стандарте ANSI/ISO не указывается максимально допустимое число столбцов в таблице, однако почти во всех коммерческих СУБД этот предел существует и обычно составляет примерно 255 столбцов.
В отличие от столбцов, строки таблицы не имеют определённого порядка. Это значит, что если последовательно выполнить два одинаковых запроса для отображения содержимого таблицы, нет гарантии, что оба раза строки будут перечислены в одном и том же порядке.
В таблице может содержаться любое количество строк. Вполне допустимо существование таблицы с нулевым количеством строк. Такая таблица называется пустой. Пустая таблица сохраняет структуру, определённую её столбцами, просто в ней не содержится данные. Стандарт ANSI/ISO не накладывает ограничений на количество строк в таблице, и во многих СУБД размер таблиц ограничен лишь свободным дисковым пространством компьютера. В других СУБД имеется максимальный предел, однако он весьма высок – около двух миллиардов строк, а иногда и больше.
3.4.2. Первичные ключи
Поскольку строки в реляционной таблице не упорядочены, нельзя выбрать строку по ее номеру в таблице. В таблице нет «первой», «последней» или «тринадцатой» строки. Тогда каким же образом можно указать в таблице конкретную строку, например строку для офиса, расположенного в Череповце?
В правильно построенной реляционной базе данных в каждой таблице есть один или несколько столбцов, значения в которых во всех строках разные. Этот столбец (столбцы) называется первичным ключом таблицы. Давайте вновь посмотрим на базу данных, показанную на рис. 6. На первый взгляд, первичным ключом таблицы «Офисы» могут служить и столбец «Офис», и столбец «Город». Однако в случае, если компания будет расширяться и откроет в каком-либо городе второй офис, столбец «Город» больше не сможет выполнять роль первичного ключа. На практике в качестве первичных ключей таблиц обычно следует выбирать идентификаторы, такие как идентификатор офиса («Офис» в таблице «Офисы»).
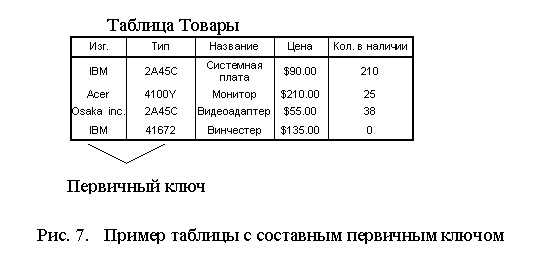 |
Таблица «Товары», фрагмент которой показан на рис. 7, является примером таблицы, в которой первичный ключ представляет собой комбинацию столбцов. Такой первичный ключ называется составным. Столбец «Изг.» содержит идентификаторы производителей всех товаров, перечисленных в таблице, а столбец «Тип» содержит номера, присвоенные товарам производителями. Может показаться, что столбец «Тип» мог бы и один выполнять роль первичного ключа, однако ничто не мешает двум различным производителям присвоить своим изделиям одинаковые номера. Таким образом, в качестве первичного ключа таблицы «Товары» необходимо использовать комбинацию столбцов «Изг.» и «Тип». Для каждого из товаров, содержащихся в таблице, комбинация значений в этих столбцах будет уникальной.
Первичный ключ для каждой строки таблицы является уникальным, поэтому в таблице с первичным ключом нет двух совершенно одинаковых строк. Таблица, в которой все строки отличаются друг от друга, в математических терминах называется отношением. Именно этому термину реляционные базы данных и обязаны своим названием, поскольку в их основе лежат отношения (таблицы с отличающимися друг от друга строками).
Хотя первичные ключи являются важной частью реляционной модели данных, в первых реляционных СУБД (System/R, DB2, Oracle и других) не была обеспечена явным образом их поддержка. Как правило, проектировщики базы данных сами следили за тем, чтобы у всех таблиц были первичные ключи, однако в самих СУБД не было возможности определить для таблицы первичный ключ. И только в СУБД DB2 Version 2, появившейся в апреле 1988 года, компания IBM реализовала поддержку первичных ключей. После этого подобная поддержка была добавлена в стандарт ANSI/ISO.
3.4.3. Отношения предок/потомок
Одним из отличий реляционной модели от первых моделей представления данных было то, что в ней отсутствовали явные указатели, используемые для реализации отношений предок/потомок в иерархической модели данных. Однако вполне очевидно, что отношения предок/потомок существуют и в реляционных базах данных. Например, в приведенной выше базе данных каждый из служащих закреплен за конкретным офисом, поэтому ясно, что между строками таблицы «Подразделения» и таблицы «Сотрудники» существует отношение. Не приводит ли отсутствие явных указателей в реляционной модели к потере информации?
Как следует из рис.8, ответ на этот вопрос должен быть отрицательным. На рисунке изображено несколько строк из таблиц «Подразделения» и «Сотрудники». Обратим внимание на то, что в столбце «Подразделение» таблицы «Сотрудники» содержится идентификатор офиса, в котором работает служащий. Доменом этого столбца (множеством значений, которые могут в нем храниться) является множество идентификаторов офисов, содержащихся в столбце «Код» таблицы «Подразделения». То, в каком офисе работает инженер Шустров, можно узнать, определив значение столбца «Подразделение» в строке таблицы «Сотрудники» для Шустрова (число 2) и затем отыскав в таблице «Подразделения» строку с таким же значением в столбце «Код» (это для службы внутреннего аудита качества). Таким же образом, чтобы найти всех работников службы внутреннего аудита качества, следует запомнить значение столбца «Код» для нее (число 2), а потом просмотреть таблицу «Сотрудники» и найти все строки, в столбце «Подразделение» в которых содержится число 2 (это строки для и ).
Отношение предок/потомок, существующее между офисами и работающими в них людьми, в реляционной модели не потеряно; просто оно реализовано в виде одинаковых значений данных, хранящихся в двух таблицах, а не в виде явного указателя. Все отношения, существующие между таблицами реляционной базы данных, реализуются в таком виде.
 Внешние ключи
Внешние ключи
Столбец одной таблицы, значения в котором совпадают со значениями столбца, являющегося первичным ключом другой таблицы, называется внешним ключом. На рис.8 столбец «Подразделение» представляет собой внешний ключ для таблицы «Подразделения». Значения, содержащиеся в этом столбце, представляют собой идентификаторы офисов. Эти значения соответствуют значениям в столбце «Код», который является первичным ключом таблицы «Подразделения». Совокупно первичный и внешний ключи создают между таблицами, в которых они содержатся, такое же отношение предок/потомок, как и в иерархической базе данных.
Внешний ключ, как и первичный ключ, тоже может представлять собой комбинацию столбцов. На практике внешний ключ всегда будет составным (состоящим из нескольких столбцов), если он ссылается на составной первичный ключ в другой таблице. Очевидно, что количество столбцов и их типы данных в первичном и внешнем ключах совпадают.
Если таблица связана с несколькими другими таблицами, она может иметь несколько внешних ключей. Отношения предок/потомок, созданные с помощью нескольких внешних, это те же самые отношения, что и в сетевой базе данных, представленной на рис.4. Как показывает пример, реляционная модель данных обладает всеми возможностями сетевой модели по части выражения сложных отношений.
Внешние ключи являются неотъемлемой частью реляционной модели, поскольку реализуют отношения между таблицами базы данных. К несчастью, как и в случае с первичными ключами, поддержка внешних ключей отсутствовала в первых реляционных СУБД. Она была введена в системе DB2 Version 2 и теперь имеется во всех коммерческих СУБД.
3.4.4. Двенадцать правил Кодда
В статье, опубликованной в журнале "Computer World", Тэд Кодд сформулировал двенадцать правил, которым должна соответствовать настоящая реляционная база данных. Двенадцать правил Кодда приведены в табл.1. Они являются полуофициальным определением понятия реляционная база данных. Перечисленные правила основаны на теоретической работе Кодда, посвященной реляционной модели данных.
Таблица 1. Двенадцать правил Кодда, которым должна соответствовать реляционная СУБД. |
1. Правило информации. Вся информация в базе данных должна быть предоставлена исключительно на логическом уровне и только одним способом - в виде значений, содержащихся в таблицах. |
2. Правило гарантированного доступа. Логический доступ ко всем и каждому элементу данных (атомарному значению) в реляционной базе данных должен обеспечиваться путём использования комбинации имени таблицы, первичного ключа и имени столбца. |
3. Правило поддержки недействительных значений. В настоящей реляционной базе данных должна быть реализована поддержка недействительных значений, которые отличаются от строки символов нулевой длинны, строки пробельных символов, и от нуля или любого другого числа и используются для представления отсутствующих данных независимо от типа этих данных. |
4. Правило динамического каталога, основанного на реляционной модели. Описание базы данных на логическом уровне должно быть представлено в том же виде, что и основные данные, чтобы пользователи, обладающие соответствующими правами, могли работать с ним с помощью того же реляционного языка, который они применяют для работы с основными данными. |
5. Правило исчерпывающего подъязыка данных. Реляционная система может поддерживать различные языки и режимы взаимодействия с пользователем (например, режим вопросов и ответов). Однако должен существовать по крайней мере один язык, операторы которого можно представить в виде строк символов в соответствии с некоторым четко определенным синтаксисом и который в полной мере поддерживает следующие элементы: — определение данных; |
6. Правило обновления представлений. Все представления, которые теоретически можно обновить, должны быть доступны для обновления. |
7. Правило добавления, обновления и удаления. Возможность работать с отношением как с одним операндом должна существовать не только при чтении данных, но и при добавлении, обновлении и удалении данных. |
8. Правило независимости физических данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при любых изменениях способов хранения данных или методов доступа к ним. |
9. Правило независимости логических данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при внесении в базовые таблицы любых изменений, которые теоретически позволяют сохранить нетронутыми содержащиеся в этих таблицах данные. |
10. Правило независимости условий целостности. Должна существовать возможность определять условия целостности, специфические для конкретной реляционной базы данных, на подъязыке реляционной базы данных и хранить их в каталоге, а не в прикладной программе. |
11. Правило независимости распространения. Реляционная СУБД не должна зависеть от потребностей конкретного клиента. |
12. Правило единственности. Если в реляционной системе есть низкоуровневой язык (обрабатывающий одну запись за один раз), то должна отсутствовать возможность использования его для того, чтобы обойти правила и условия целостности, выраженные на реляционном языке высокого уровня (обрабатывающем несколько записей за один раз). |
Правило 1 напоминает неформальное определение реляционной базы данных, приведенное ранее.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
