

Если Вы заметите, что искомое слово должно находиться гораздо дальше открытой страницы, вы пропустите порядочное их количество, прежде чем сделать новую попытку. Это в корне отличается от предыдущих алгоритмов, не делающих разницы между 'много больше' и 'чуть больше'.
Мы приходим к алгоритму, называемому интерполяционным поиском: Если известно, что К лежит между Kl и Ku, то следующую пробу делаем на расстоянии (u-l)(K-Kl)/(Ku-Kl) от l, предполагая, что ключи являются числами, возрастающими приблизительно в арифметической прогрессии.
Интерполяционный поиск работает за log N операций, если данные распределены равномерно. Как правило, он используется лишь на очень больших таблицах, причем делается несколько шагов интерполяционного поиска, а затем на малом подмассиве используется бинарный или последовательный варианты.
Алгоритмы выборки элементов из массивов данных.
Алгоритмы сортировки данных.
Алгоритм сортировки — это алгоритм для упорядочения элементов в списке. В случае, когда элемент списка имеет несколько полей, поле, служащее критерием порядка, называется ключом сортировки. На практике, в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
Критерии Эффективности
Единственного эффективнейшего алгоритма сортировки нет, ввиду множества параметров оценки эффективности:
Время — основной параметр, характеризующий быстродействие алгоритма. Называется также вычислительной сложностью. Для упорядочения важны худшее, среднее и лучшее поведение алгоритма в терминах размера списка (n). Для типичного алгоритма хорошее поведение — это O(n log n) и плохое поведение — это O(n²). Идеальное поведение для упорядочения — O(n). Алгоритмы сортировки, использующие только абстрактную операцию сравнения ключей всегда нуждаются по меньшей мере в O(n log n) сравнениях в среднем;
Память — ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
Устойчивость (stability) — устойчивая сортировка не меняет взаимного расположения равных элементов.
Естественность поведения — эффективность метода при обработке уже упорядоченных, или частично упорядоченных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Необходимо подчеркнуть, что степень роста наихудшего времени выполнения — не единственный или самый важный критерий оценки алгоритмов и программ. Приведем несколько соображений, позволяющих посмотреть на критерий времени выполнения с других точек зрения:
1. Если создаваемая программа будет использована только несколько раз, тогда стоимость написания и отладки программы будет доминировать в общей стоимости программы, т. е. фактическое время выполнения не окажет существенного влияния на общую стоимость. В этом случае следует предпочесть алгоритм, наиболее простой для реализации.
2. Если программа будет работать только с «малыми» входными данными, то степень роста времени выполнения будет иметь меньшее значение, чем константа, присутствующая в формуле времени выполнения. Вместе с тем и понятие «малости» входных данных зависит от точного времени выполнения конкурирующих алгоритмов. Существуют алгоритмы, такие как алгоритм целочисленного умножения, асимптотически самые эффективные, но которые никогда не используют на практике даже для больших задач, так как их константы пропорциональности значительно превосходят подобные константы других, более простых и менее «эффективных» алгоритмов.
3. Эффективные, но сложные алгоритмы могут быть нежелательными, если готовые программы будут поддерживать лица, не участвующие в написании этих программ. Будем надеяться, что принципиальные моменты технологии создания эффективных алгоритмов широко известны, и достаточно сложные алгоритмы свободно применяются на практике. Однако необходимо предусмотреть возможность того, что эффективные, но «хитрые» алгоритмы не будут востребованы из-за их сложности и трудностей, возникающих при попытке в них разобраться.
4. Известно несколько примеров, когда эффективные алгоритмы требуют таких больших объемов машинной памяти (без возможности использования более медленных внешних средств хранения), что этот фактор сводит на нет преимущество «эффективности» алгоритма.
5. В численных алгоритмах точность и устойчивость алгоритмов не менее важны, чем их временная эффективность.
Сортировка выбором
 Идея метода состоит в том, чтобы создавать отсортированную последовательность путем присоединения к ней одного элемента за другим в правильном порядке.
Идея метода состоит в том, чтобы создавать отсортированную последовательность путем присоединения к ней одного элемента за другим в правильном порядке.
Будем строить готовую последовательность, начиная с левого конца массива. Алгоритм состоит из n последовательных шагов, начиная от нулевого и заканчивая (n-1)-м.
На i-м шаге выбираем наименьший из элементов a[i] ... a[n] и меняем его местами с a[i]. Последовательность шагов при n=5 изображена на рисунке ниже.
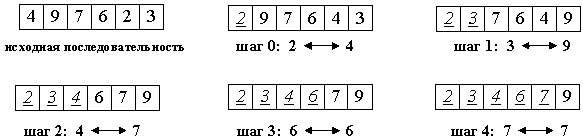
Вне зависимости от номера текущего шага i, последовательность a[0]...a[i] (выделена курсивом) является упорядоченной. Таким образом, на (n-1)-м шаге вся последовательность, кроме a[n] оказывается отсортированной, а a[n] стоит на последнем месте по праву: все меньшие элементы уже ушли влево.
template<class T>
void selectSort(T a[], long size) {
long i, j, k;
T x;
for( i=0; i < size; i++) { // i - номер текущего шага
k=i; x=a[i];
for( j=i+1; j < size; j++) // цикл выбора наименьшего элемента
if ( a[j] < x ) {
k=j; x=a[j]; // k - индекс наименьшего элемента
}
a[k] = a[i]; a[i] = x; // меняем местами наименьший с a[i]
}
}
Для нахождения наименьшего элемента из n+1 рассматримаемых алгоритм совершает n сравнений. С учетом того, что количество рассматриваемых на очередном шаге элементов уменьшается на единицу, общее количество операций:
n + (n-1) + (n-2) + (n-3) + ... + 1 = 1/2 * ( n2+n ) = Theta(n2).
Таким образом, так как число обменов всегда будет меньше числа сравнений, время сортировки растет квадратично относительно количества элементов.
Алгоритм не использует дополнительной памяти: все операции происходят "на месте".
Устойчив ли этот метод? Прежде, чем читать далее, попробуйте получить ответ самостоятельно.
Рассмотрим последовательность из трех элементов, каждый из которых имеет два поля, а сортировка идет по первому из них.

Результат ее сортировки можно увидеть уже после шага 0, так как больше обменов не будет. Порядок ключей 2a, 2b был изменен на 2b, 2a, так что метод неустойчив.
Если входная последовательность почти упорядочена, то сравнений будет столько же, значит алгоритм ведет себя неестественно.
Сортировка пузырьком
![]()
Расположим массив сверху вниз, от нулевого элемента - к последнему.
Идея метода: шаг сортировки состоит в проходе снизу вверх по массиву. По пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то меняем их местами.
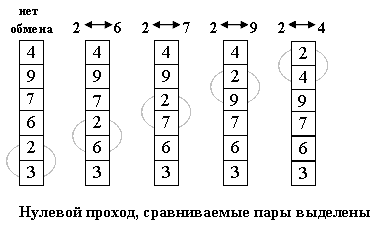
После нулевого прохода по массиву "вверху" оказывается самый "легкий" элемент - отсюда аналогия с пузырьком. Следующий проход делается до второго сверху элемента, таким образом второй по величине элемент поднимается на правильную позицию...
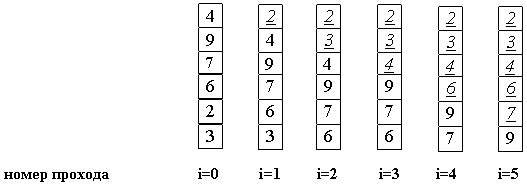
Делаем проходы по все уменьшающейся нижней части массива до тех пор, пока в ней не останется только один элемент. На этом сортировка заканчивается, так как последовательность упорядочена по возрастанию.
template<class T>
void bubbleSort(T a[], long size) {
long i, j;
T x;
for( i=0; i < size; i++) { // i - номер прохода
for( j = size-1; j > i; j-- ) { // внутренний цикл прохода
if ( a[j-1] > a[j] ) {
x=a[j-1]; a[j-1]=a[j]; a[j]=x;
}
}
}
}
Среднее число сравнений и обменов имеют квадратичный порядок роста: Theta(n2), отсюда можно заключить, что алгоритм пузырька очень медленен и малоэффективен.
Тем не менее, у него есть громадный плюс: он прост.
На практике метод пузырька, даже с улучшениями, работает, увы, слишком медленно. А потому - почти не применяется.
Сортировка простыми вставками
Сортировка вставками (англ. insertion sort) — простой алгоритм сортировки. Хотя этот метод сортировки намного менее эффективен, чем более сложные алгоритмы (такие как быстрая сортировка), у него есть ряд преимуществ:
прост в реализации эффективен на небольших наборах данных эффективен на наборах данных, которые уже частично отсортированы это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже отсортированы) может сортировать список по мере его полученияСортировка простыми вставками в чем-то похожа на вышеизложенные методы.
Аналогичным образом делаются проходы по части массива, и аналогичным же образом в его начале "вырастает" отсортированная последовательность...
Однако в сортировке пузырьком или выбором можно было четко заявить, что на i-м шаге элементы a[0]...a[i] стоят на правильных местах и никуда более не переместятся. Здесь же подобное утверждение будет более слабым: последовательность a[0]...a[i] упорядочена. При этом по ходу алгоритма в нее будут вставляться (см. название метода) все новые элементы.
Будем разбирать алгоритм, рассматривая его действия на i-м шаге. Как говорилось выше, последовательность к этому моменту разделена на две части: готовую a[0]...a[i] и неупорядоченную a[i+1]...a[n].
На следующем, (i+1)-м каждом шаге алгоритма берем a[i+1] и вставляем на нужное место в готовую часть массива.
Поиск подходящего места для очередного элемента входной последовательности осуществляется путем последовательных сравнений с элементом, стоящим перед ним.
В зависимости от результата сравнения элемент либо остается на текущем месте(вставка завершена), либо они меняются местами и процесс повторяется.
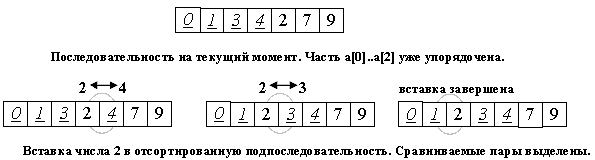
Таким образом, в процессе вставки мы "просеиваем" элемент x к началу массива, останавливаясь в случае, когда
Hайден элемент, меньший x или Достигнуто начало последовательности.template<class T>
void insertSort(T a[], long size) {
T x;
long i, j;
for ( i=0; i < size; i++) { // цикл проходов, i - номер прохода
x = a[i];
// поиск места элемента в готовой последовательности
for ( j=i-1; j>=0 && a[j] > x; j--)
a[j+1] = a[j]; // сдвигаем элемент направо, пока не дошли
// место найдено, вставить элемент
a[j+1] = x;
}
}
Аналогично сортировке выбором, среднее, а также худшее число сравнений и пересылок оцениваются как Theta(n2), дополнительная память при этом не используется.
Хорошим показателем сортировки является весьма естественное поведение: почти отсортированный массив будет досортирован очень быстро. Это, вкупе с устойчивостью алгоритма, делает метод хорошим выбором в соответствующих ситуациях.
Алгоритм можно слегка улучшить. Заметим, что на каждом шаге внутреннего цикла проверяются 2 условия. Можно объединить из в одно, поставив в начало массива специальный сторожевой элемент. Он должен быть заведомо меньше всех остальных элементов массива.
![]()
Тогда при j=0 будет заведомо верно a[0] <= x. Цикл остановится на нулевом элементе, что и было целью условия j>=0.
Таким образом, сортировка будет происходить правильным образом, а во внутреннем цикле станет на одно сравнение меньше. С учетом того, что оно производилось Theta(n2) раз, это - реальное преимущество. Однако, отсортированный массив будет не полон, так как из него исчезло первое число. Для окончания сортировки это число следует вернуть назад, а затем вставить в отсортированную последовательность a[1]...a[n].
![]()
// сортировка вставками со сторожевым элементом
template<class T>
inline void insertSortGuarded(T a[], long size) {
T x;
long i, j;
T backup = a[0]; // сохранить старый первый элемент
setMin(a[0]); // заменить на минимальный
// отсортировать массив
for ( i=1; i < size; i++) {
x = a[i];
for ( j=i-1; a[j] > x; j--)
a[j+1] = a[j];
a[j+1] = x;
}
// вставить backup на правильное место
for ( j=1; j<size && a[j] < backup; j++)
a[j-1] = a[j];
// вставка элемента
a[j-1] = backup;
}
Функция setmin(T& x) должна быть создана пользователем. Она заменяет x на элемент, заведомо меньший(меньший или равный, если говорить точнее) всех элементов массива.
Сортировка Шелла.
Сортировка Шелла является довольно интересной модификацией алгоритма сортировки простыми вставками.
Рассмотрим следующий алгоритм сортировки массива a[0].. a[15].
![]()
1. Вначале сортируем простыми вставками каждые 8 групп из 2-х элементов (a[0], a[8[), (a[1], a[9]), ... , (a[7], a[15]).

2. Потом сортируем каждую из четырех групп по 4 элемента (a[0], a[4], a[8], a[12]), ..., (a[3], a[7], a[11], a[15]).
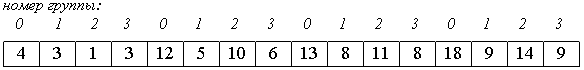
В нулевой группе будут элементы 4, 12, 13, 18, в первой - 3, 5, 8, 9 и т. п.
3. Далее сортируем 2 группы по 8 элементов, начиная с (a[0], a[2], a[4], a[6], a[8], a[10], a[12], a[14]).

4. В конце сортируем вставками все 16 элементов.
![]()
Очевидно, лишь последняя сортировка необходима, чтобы расположить все элементы по своим местам. Так зачем нужны остальные?
Hа самом деле они продвигают элементы максимально близко к соответствующим позициям, так что в последней стадии число перемещений будет весьма невелико. Последовательность и так почти отсортирована. Ускорение подтверждено многочисленными исследованиями и на практике оказывается довольно существенным.
Единственной характеристикой сортировки Шелла является приращение - расстояние между сортируемыми элементами, в зависимости от прохода. В конце приращение всегда равно единице - метод завершается обычной сортировкой вставками, но именно последовательность приращений определяет рост эффективности.
Использованный в примере набор ..., 8, 4, 2, 1 - неплохой выбор, особенно, когда количество элементов - степень двойки. Однако гораздо лучший вариант предложил Р. Седжвик. Его последовательность имеет вид
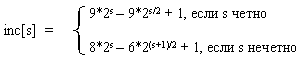
При использовании таких приращений среднее количество операций: O(n7/6), в худшем случае - порядка O(n4/3).
Обратим внимание на то, что последовательность вычисляется в порядке, противоположном используемому: inc[0] = 1, inc[1] = 5, ... Формула дает сначала меньшие числа, затем все большие и большие, в то время как расстояние между сортируемыми элементами, наоборот, должно уменьшаться. Поэтому массив приращений inc вычисляется перед запуском собственно сортировки до максимального расстояния между элементами, которое будет первым шагом в сортировке Шелла. Потом его значения используются в обратном порядке.
При использовании формулы Седжвика следует остановиться на значении inc[s-1], если 3*inc[s] > size.
int increment(long inc[], long size) {
int p1, p2, p3, s;
p1 = p2 = p3 = 1;
s = -1;
do {
if (++s % 2) {
inc[s] = 8*p1 - 6*p2 + 1;
} else {
inc[s] = 9*p1 - 9*p3 + 1;
p2 *= 2;
p3 *= 2;
}
p1 *= 2;
} while(3*inc[s] < size);
return s > 0 ? --s : 0;
}
template<class T>
void shellSort(T a[], long size) {
long inc, i, j, seq[40];
int s;
// вычисление последовательности приращений
s = increment(seq, size);
while (s >= 0) {
// сортировка вставками с инкрементами inc[]
inc = seq[s--];
for (i = inc; i < size; i++) {
T temp = a[i];
for (j = i-inc; (j >= 0) && (a[j] > temp); j -= inc)
a[j+inc] = a[j];
a[j+inc] = temp;
}
}
}
Часто вместо вычисления последовательности во время каждого запуска процедуры, ее значения рассчитывают заранее и записывают в таблицу, которой пользуются, выбирая начальное приращение по тому же правилу: начинаем с inc[s-1], если 3*inc[s] > size.
Сортировка быстрая
Алгоритм
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы:
- Выбираем в массиве некоторый элемент, который будем называть опорным элементом. Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы, меньшие или равные опорному элементу, оказались слева от него, а все элементы, большие опорного — справа от него. Рекурсивно упорядочиваем подсписки, лежащие слева и справа от опорного элемента.
"Быстрая сортировка", хоть и была разработана более 40 лет назад, является наиболее широко применяемым и одним их самых эффективных алгоритмов.
Метод основан на подходе "разделяй-и-властвуй". Общая схема такова:
из массива выбирается некоторый опорный элемент a[i], запускается процедура разделения массива, которая перемещает все ключи, меньшие, либо равные a[i], влево от него, а все ключи, большие, либо равные a[i] - вправо, теперь массив состоит из двух подмножеств, причем левое меньше, либо равно правого,В конце получится полностью отсортированная последовательность.
На входе массив a[0]...a[N] и опорный элемент p, по которому будет производиться разделение.
Введем два указателя: i и j. В начале алгоритма они указывают, соответственно, на левый и правый конец последовательности. Будем двигать указатель i с шагом в 1 элемент по направлению к концу массива, пока не будет найден элемент a[i] >= p. Затем аналогичным образом начнем двигать указатель j от конца массива к началу, пока не будет найден a[j] <= p. Далее, если i <= j, меняем a[i] и a[j] местами и продолжаем двигать i, j по тем же правилам... Повторяем шаг 3, пока i <= j.Рассмотрим работу процедуры для массива a[0]...a[6] и опорного элемента p = a[3].
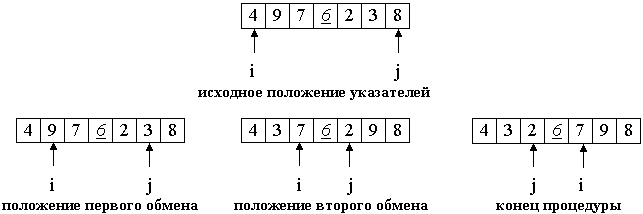
Теперь массив разделен на две части: все элементы левой меньше либо равны p, все элементы правой - больше, либо равны p. Разделение завершено.
Общий алгоритм 

Псевдокод.
quickSort ( массив a, верхняя граница N ) {
Выбрать опорный элемент p - середину массива
Разделить массив по этому элементу
Если подмассив слева от p содержит более одного элемента,
вызвать quickSort для него.
Если подмассив справа от p содержит более одного элемента,
вызвать quickSort для него.
}
Реализация на Си.
template<class T>
void quickSortR(T* a, long N) {
// На входе - массив a[], a[N] - его последний элемент.
long i = 0, j = N; // поставить указатели на исходные места
T temp, p;
p = a[ N>>1 ]; // центральный элемент
// процедура разделения
do {
while ( a[i] < p ) i++;
while ( a[j] > p ) j--;
if (i <= j) {
temp = a[i]; a[i] = a[j]; a[j] = temp;
i++; j--;
}
} while ( i<=j );
// рекурсивные вызовы, если есть, что сортировать
if ( j > 0 ) quickSortR(a, j);
if ( N > i ) quickSortR(a+i, N-i);
}
Каждое разделение требует, очевидно, Theta(n) операций. Количество шагов деления(глубина рекурсии) составляет приблизительно log n, если массив делится на более-менее равные части. Таким образом, общее быстродействие: O(n log n), что и имеет место на практике.
Однако, возможен случай таких входных данных, на которых алгоритм будет работать за O(n2) операций. Такое происходит, если каждый раз в качестве центрального элемента выбирается максимум или минимум входной последовательности. Если данные взяты случайно, вероятность этого равна 2/n. И эта вероятность должна реализовываться на каждом шаге... Вообще говоря, малореальная ситуация.
Метод неустойчив. Поведение довольно естественно, если учесть, что при частичной упорядоченности повышаются шансы разделения массива на более равные части.
Сортировка использует дополнительную память, так как приблизительная глубина рекурсии составляет O(log n), а данные о рекурсивных подвызовах каждый раз добавляются в стек.
if ( j > CUTOFF ) quickSortR(a, j);
Сортировка поразрядная
Пусть имеем максимум по k байт в каждом ключе (хотя за элемент сортировки вполне можно принять и что-либо другое, например слово - двойной байт, или буквы, если сортируются строки). k должно быть известно заранее, до сортировки.
Разрядность данных (количество возможных значений элементов) - m - также должна быть известна заранее и постоянна. Если мы сортируем слова, то элемент сортировки - буква, m = 33. Если в самом длинном слове 10 букв, k = 10. Обычно мы будем сортировать данные по ключам из k байт, m=256.
Пусть у нас есть массив source из n элементов по одному байту в каждом.
Для примера можете выписать на листочек массив source = <7, 9, 8, 5, 4, 7, 7>, и проделать с ним все операции, имея в виду m=9.
Составим таблицу распределения. В ней будет m (256) значений и заполняться она будет так:for i := 0 to Pred(255) Do distr[i]:=0;
for i := 0 to Pred(n) Do distr[source[i]] := distr[[i]] + 1;
Для нашего примера будем иметь distr = <0, 0, 0, 0, 1, 1, 0, 3, 1, 1>, то есть i-ый элемент distr[] - количество ключей со значением i.
Заполним таблицу индексов:index: array[0] of integer;
index[0]:=0;
for i := 1 to Pred(255) Do index[i]=index[i-1]+distr[i-1];
В index[ i ] мы поместили информацию о будущем количестве символов в отсортированном массиве до символа с ключом i.
Hапример, index[8] = 5 : имеем <4, 5, 7, 7, 7, 8>.
А теперь заполняем новосозданный массив sorted размера n:for i := 0 to Pred(n) Do Begin
sorted[ index[ source[i] ] ]:=source[i];
{
попутно изменяем index уже вставленных символов, чтобы
одинаковые ключи шли один за другим:
}
index[ source[i] ] := index[ source[i] ] +1;
End;
Итак, мы научились за O(n) сортировать байты. А от байтов до строк и чисел - 1 шаг. Пусть у нас в каждом числе - k байт.
Будем действовать в десятичной системе и сортировать обычные числа ( m = 10 ).
сначала они в сортируем по младшему на один беспорядке: разряду: выше: и еще раз:
Hу вот мы и отсортировали за O(k*n) шагов. Если количество возможных различных ключей ненамного превышает общее их число, то 'поразрядная сортировка' оказывается гораздо быстрее даже 'быстрой сортировки'!
Пример:
Const
n = 8;
Type
arrType = Array[0 .. Pred(n)] Of Byte;
Const
m = 256;
a: arrType =
(44, 55, 12, 42, 94, 18, 6, 67);
Procedure RadixSort(Var source, sorted: arrType);
Type
indexType = Array[0 .. Pred(m)] Of Byte;
Var
distr, index: indexType;
i: integer;
begin
fillchar(distr, sizeof(distr), 0);
for i := 0 to Pred(n) do
inc(distr[source[i]]);
index[0] := 0;
for i := 1 to Pred(m) do
index[i] := index[Pred(i)] + distr[Pred(i)];
for i := 0 to Pred(n) do
begin
sorted[ index[source[i]] ] := source[i];
index[source[i]] := index[source[i]]+1;
end;
end;
var
b: arrType;
begin
RadixSort(a, b);
end.
Сортировка подсчетом
Пусть у нас есть массив source из n десятичных цифр ( m = 10 ).
Например, source[7] = { 7, 9, 8, 5, 4, 7, 7 }, n=7. Здесь положим const k=1.
a. проинициализовать count[] нулями,
b. пройти по source от начала до конца, для каждого числа увеличивая элемент count с соответствующим номером.
c. for( i=0; i<n; i++) count [ source[i] ]++
В нашем примере count[] = { 0, 0, 0, 0, 1, 1, 0, 3, 1, 1 }
Присвоить count[i] значение, равное сумме всех элементов до данного:count[i] = count[0]+count[1]+...count[i-1].
В нашем примере count[] = { 0, 0, 0, 0, 1, 2, 2, 2, 5, 6 }
Эта сумма является количеством чисел исходного массива, меньших i. Произвести окончательную расстановку.
Для каждого числа source[i] мы знаем, сколько чисел меньше него - это значение хранится в count[ source[i] ]. Таким образом, нам известно окончательное место числа в упорядоченном массиве: если есть K чисел меньше данного, то оно должно стоять на на позиции K+1.
Осуществляем проход по массиву source слева направо, одновременно заполняя выходной массив dest:
for ( i=0; i<n; i++ ) {
c = source[i];
dest[ count[c] ] = c;
count[c]++; // для повторяющихся чисел
}
Таким образом, число c=source[i] ставится на место count[c]. На этот случай, если числа повторяются в массиве, предусмотрен оператор count[c]++, который увеличивает значение позиции для следующего числа c, если таковое будет.
Циклы занимают (n + m) времени. Столько же требуется памяти.
Итак, мы научились за (n + m) сортировать цифры. А от цифр до строк и чисел - 1 шаг. Пусть у нас в каждом ключе k цифр ( m =Аналогично случаю со списками отсортируем их в несколько проходов от младшего разряда к старшему.

Общее количество операций, таким образом, ( k(n+m) ), при используемой дополнительно памяти (n+m). Эта схема допускает небольшую оптимизацию. Заметим, что сортировка по каждому байту состоит из 2 проходов по всему массиву: на первом шаге и на четвертом. Однако, можно создать сразу все массивы count[] (по одному на каждую позицию) за один проход. Неважно, как расположены числа - счетчики не меняются, поэтому это изменение корректно.
Таким образом, первый шаг будет выполняться один раз за всю сортировку, а значит, общее количество проходов изменится с 2k на k+1.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
