

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНТЕРФЕЙСЫ ДЛЯ ЭВМ НОВЫХ ПОКОЛЕНИЙ
Введение
Одной из основных особенностей пятого и последующих поколении ЭВМ является ориентация на неподготовленного в области программирования пользователя. Превращение ЭВМ в устройство массового использования, в обычный «бытовой прибор» требует наличия специальных средств, облегчающих работу пользователя. По-видимому, те усилия, которые неподготовленные пользователи согласны сделать, когда они подходят к ЭВМ, не должны быть намного больше тех усилий, которые они затрачивают, применяя многофункциональные электронные установки или многопрограммные стиральные агрегаты.
Подобная концепция выдвигает перед создателями новых поколений ЭВМ специфическую проблему – создание интеллектуального интерфейса, способного обеспечить контакт пользователя с ЭВМ в условиях его общей профессиональной неподготовленности. Если раньше между подобным пользователем и ЭВМ находился специалист по программированию, который выполнял роль переводчика между ними, то теперь этот вид интеллектуальной деятельности должен быть автоматизирован и реализован в интеллектуальном интерфейсе.
Каковы же основные функции интеллектуального интерфейса? Перечислим их, а затем рассмотрим пути их реализации.
1. Функция общения. Предполагается, что непрограммирующий пользователь будет общаться с ЭВМ па ограниченном естественном языке. Ограниченность языка состоит в том, что он используется для определенной цели – формулировки задач, которые должна решать ЭВМ. Правда, спектр задач при массовом внедрении ЭВМ в различные виды человеческой деятельности может быть весьма широким. Ведь с помощью ЭВМ уже сейчас решаются не только вычислительные задачи, но и задачи, связанные с проведением логических рассуждений, информационным поиском, делопроизводством и с другими типами человеческой деятельности. Поэтому естественный язык, который допустим на входе интеллектуального интерфейса, не может быть слишком бедным. Его ограниченность проявляется не в объеме словаря, а скорее в организации текстов, вводимых пользователем в ЭВМ. Важно, чтобы вводимый текст был понятен для ЭВМ. Термин «понимание» требует уточнения, что мы и сделаем ниже. А пока его можно воспринимать на уровне интуиции.
При реализации функции общения важную роль играют средства графического отображения информации и возможность замены текстов совокупностью действий («опредмечивание» текста, о чем будет говориться ниже). Поэтому система общения, входящая в интеллектуальный интерфейс, – это не только система, общения на основе текстовых сообщений, но и всевозможные системы ввода-вывода речевых сообщений, средства графического взаимодействия и средства типа курсора.
2. Функция автоматического синтеза программы. Сообщение пользователя должно преобразовываться в рабочую программу, которую ЭВМ может выполнить. Это заставляет иметь в составе интеллектуального интерфейса средства для реализации в ЭВМ процедур, которые обычно выполняет человек-программист. Для того, чтобы это стало возможным, необходимо уметь перевести исходное сообщение пользователя на некоторый точный язык спецификаций, а затем породить из этой записи рабочую программу. Подобное преобразование требует специальных знаний, которые должны иметься в памяти ЭВМ.
___________________________________________________________________________
* Опубликовано в: Электронная вычислительная техника. Сборник статей. Вып.3. –М.: Радио и связь, 1989. –С.4-20
3. Функция обоснования. Пользователь, не разбирающийся или плохо разбирающийся в том, как ЭВМ преобразует его задачу в рабочую программу и какие методы она использует для получения решения, вправе потребовать от ЭВМ обоснования полученного решения. Он может спросить ЭВМ, как она преобразовала его задачу в программу, какой метод использовала для нахождения решения, как это решение было получено и как оно было интерпретировано на выходе. Таким образом, в функцию обоснования входит и функция объяснения, характерная для современных экспертных систем, и функция доверия, цель которой – повысить степень доверия пользователя к ЭВМ.
4. Функция обучения. Когда пользователь впервые подходит к ЭВМ, то он вправе ожидать, что сведения о работе с нею он сможет получить достаточно легко. Для бытовых приборов, с которыми он до этого сталкивался, достаточно прочитать несложную и небольшую инструкцию, чтобы сразу понять, как надо обращаться с этим прибором. ЭВМ, конечно, сложнее всех тех приборов, с которыми человек сталкивался в быту. Инструкция, которая позволила бы пользователю овладеть всеми возможностями ЭВМ, понять основные принципы работы с ней, оказалось бы слишком объемной и неудобной для него. Поэтому ЭВМ новых поколений снабжаются специальными средствами (тьюторами), с помощью которых пользователь постепенно постигает способы работы с ЭВМ и тонкости успешного общения с ней.
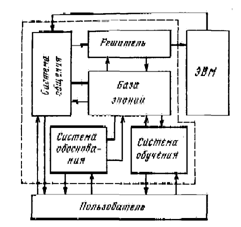
Таким образом, интеллектуальный интерфейс имеет структуру, показанную на рис.1. Центральное место в этой структуре занимает база знаний.
В ЭВМ прежних поколений такого блока не было. Его появление связано с тем, что для выполнения всех перечисленных ранее функций интеллектуального интерфейса необходимы специальные знания. Для системы общения это словари и знания о том, как понимаются тексты, графические изображения и предметные действия, как анализируется речь и как синтезируются ответы пользователю, как соотносятся между собой различные типы информации, используемой для общения. Для решателя это знания о переводе входных сообщений в текст на языке внутренних представлений (языке спецификаций), об извлечении программы из этих текстов, о правилах рассуждений и логического вывода, о методах решения задач в данной проблемной области. Для системы обоснования это знания о том, как отвечать на вопросы пользователя, как обосновывать полученное решение. Наконец, для системы обучения это знания о том, как учить пользователя, как учитывать его реакцию при обучении и его психологические особенности.
Таким образом, интеллектуальный интерфейс, есть, по сути, некоторая логическая машина, сложность которой куда выше сложности обычной вычислительной машины. На рис.1 эта машина выделена штриховой линией. В правой части рис.1 показана классическая ЭВМ, на которой происходит выполнение программы, подготовленной интеллектуальным интерфейсом. При аппаратной реализации обе ЭВМ могут быть реализованы в рамках единой системы. Выбор той или иной архитектуры зависит от конкретных инженерных решений, которые в данной статье не затрагиваются.
Проблема понимания
Основным содержанием функции общения является процедура понимания ЭВМ вводимых в нее текстов, К сожалению, ни в лингвистике, ни в психологии, ни в философии термин «понимание» не получил точной интерпретации.
Поэтому ниже дадим его интерпретацию, удобную для разработчиков интеллектуальных систем. Эта интерпретация является развитием той, которая была опубликована в [1], Введем семь уровней понимания, характерных для интеллектуальных интерфейсов, точно поясняя на каждом уровне его содержание.
|
|
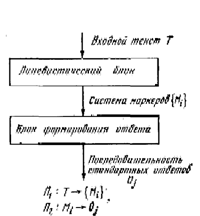
Рис.1. Структура интеллекту-
ального интерфейса
Рис.2. Интерфейс «нулевого» уровня
0. На нулевом уровне понимания система способна отвечать на сообщения пользователя безо всякого анализа их сути. На этом уровне понимание как таковое у системы отсутствует. В общении людей между собой нулевому уровню понимания соответствует так называемый фатическия диалог, когда разговор поддерживается без анализа сути высказываний собеседника за счет чисто внешних форм поддержки диалога. Например, разговаривая с кем-то по телефону, когда содержание самого разговора вас абсолютно не интересует, можно, не слушая того, что говорит собеседник, вставлять периодически ничего не значащие реплики типа: «Очень интересно», «я слушаю» и т. п. Можно «зацеплять?» свои реплики чисто формально за те или иные слова в сообщениях собеседника. Если собеседник сказал о чем-то, что это важно, то можно синтезировать реплику: «Это, действительно, очень важно», даже не давая себе труда понять, о чем идет речь. Интересно, что подобный способ общения внешне опознается далеко не сразу. Первые программы общения для ЭВМ (например, знаменитая программа ЭЛИЗА [2]) неоднократно приводили собеседника в изумление. Казалось, что эти программы ведут с партнерами настоящий интеллектуальный разговор. Тем не менее, организация системы общения с таким уровнем понимания весьма проста. Она показана на рис.2. На вход лингвистического блока поступает входной текст. В этом тексте выделяются заранее заданные маркеры, которыми могут быть конкретные слова или выражения, или стандартные компоненты, в синтаксической структуре предложения. На каждый такой маркер в памяти ЭВМ хранится конструкция ответного сообщения. Оно может быть стандартным или иметь «пустые» места, заполняемые стандартным образом выделенными в тексте маркерами. При вводе в ЭВМ фразы: «Мне нравится хорошая погода», ответная реплика может звучать: «А почему?» И эта же самая реплика будет ответной для введенной в ЭВМ фразы: «Мне не нравится, когда я болею», ибо маркером, вызывающим подобную реплику со стороны ЭВМ, может быть слово «нравится» С функциональной точки зрения нулевой уровень понимания характеризуется двумя процедурами: П1 – выделение маркеров по входном сообщении и П2 – формирование стандартных ответных реплик.
1. На первом уровне понимания система становится способной отвечать на все вопросы, ответы на которые есть во введенном в нее тексте Если система способна давать любые такие ответы, то она «овладела» первым уровнем понимания. Например, если в ЭВМ введен текст: «В аэропорту Внуково в 20 часов приземлился самолет ИЛ-62, прилетевший из Баку. В 21 час пассажиры этого рейса получили свой багаж, а в 22 часа этот же самолет улетел в Баку», то на первом уровне понимания ЭВМ обязана отвечать правильно на вопросы типа: «Откуда прилетел самолет, приземлившийся в 20 часов в аэропорту Внуково?» или «В каком аэропорту приземлился в 20 часов ИЛ-62, прилетевший из Баку?».
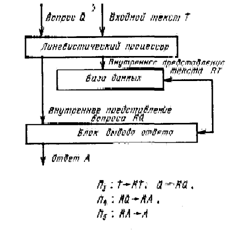
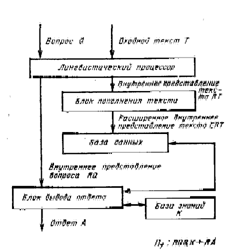
Для того чтобы в системе общения была реализована возможность подобной работы с текстом, необходима структура, показанная на рис.3. На этом рисунке приведены лингвистический процессор, блок вывода ответа и база данных. В базу данных вводится входной текст, преобразованный в лингвистическом процессоре в некоторое внутреннее представление. Это внутреннее представление может быть любым, но важно, чтобы в лингвистическом процессоре были реализованы процедуры, позволяющие выявить глубинную синтаксическую структуру вводимых в ЭВМ предложений, а также структуру межфразовых связей в тексте [3, 4]. На современном уровне наших знаний об анализе предложений н текста эти процедуры достаточно хорошо известны и реализованы в ряде практически действующих систем [б]. Знание глубинной синтаксической структуры позволяет блоку вывода ответа соотнести внутреннее представление вопроса RQ с внутренним представлением текста RТ и найти то предложение, в котором содержится ответ на введенный вопрос, либо убедиться, что такого предложения нет. Во втором случае пользователь получает отказ, а в первом случае за счет трансформации найденного предложения (или без нее) формируется ответ, нужный пользователю. Три процедуры, характерные для первого уровня понимания текста, – это процедура П3, реализуемая в лингвистическом процессоре и осуществляющая перевод текста и вопросов во внутренние представления, передаваемый в базу данных и блок формирования ответа; процедура П4, характеризующая поиск того фрагмента текста, который соответствует вопросу, и процедура П5, которая переводит внутреннее представление ответа во внешнее представление. Две последние процедуры характеризуют работу блока вывода ответа.
|
|
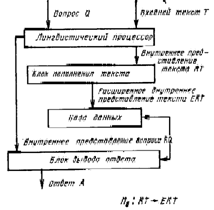
Рис.3. Интерфейс «первого» уровня Рис. 4. Интерфейс «второго» уровня
2. На втором уровне понимания используется структура, показанная не рис.4. Новым в этой структуре является блок пополнения текста. В его функции входит автоматическое пополнение текста за счет хранящихся в памяти ЭВМ процедур пополнения. Примерами подобных процедур могут служить правила вывода псевдофизических логик [б], к которым относятся логики времени, пространства, причинно-следственных связей и т. п. Если в память ЭВМ введен тот же текст, который мы использовали для иллюстрации функционирования системы с первым уровнем понимания, то на втором уровне система может отвечать на вопросы типа; «Получили ли пассажиры багаж, когда в 22 часа самолет ИЛ-62, прилетевший из Баку, улетел обратно?». Для формирования ответа на такой вопрос необходимо, используя правила логики времени, спроецировать события, упомянутые в исходном тексте, на порядковую (в данном случае, метрическую) школу времени и тем самым упорядочить их, а используя правила логики пространства, отождествить «обратно» с «Баку»,
3. Третий уровень понимания реализуется структурой системы, похожей на структуру, показанную на рис. 4. Отличие состоит в процедурах, реализуемых блоком вывода ответа. Формируя ответы, этот блок использует теперь не только информацию, хранящуюся в базе данных, куда введено расширенное внутреннее представление исходного текста, но и некоторую дополнительную информацию, хранящуюся в базе знаний (рис.5). Эта априорно хранимая в памяти системы дополнительная информация есть знание системы о типовых сценариях ситуаций и процессов, характерных для той предметной области, с которой работает система.
Используя все тот же иллюстративный пример, введем в базу знаний типовой сценарий процесса прилета пассажирского самолета и процесса его отлета. Сценарий прилета такого самолета может выглядеть, например, так, как это показано на рис.6. Вершины сценарий соответствуют определенным событиям, а дуги характеризуют последовательность событий во времени, задавая на них частичный порядок. Наличие сценария позволяет пользователю получить, например, ответ на вопрос: «Когда пассажиры покинули самолет?». Об этом факте в исходном тексте нет никакой информации. И система, уровень понимания которой ниже третьего, оказывается не в состоянии понять подобный вопрос. В системе с третьим уровнем понимания блок вывода ответа по внутреннему представлению вопроса RQ производит поиск нужного для формирования ответа фрагмента текста. При ненахождении такого фрагмента блок вывода ответа обращается к содержимому базы знаний. Если там ответ также не найден, то пользователю выдается отказ, а если нужная информация имеется, то с помощью процедур, хранимых в блоке вывода ответа, эта информация извлекается из сценария и участвует в формировании ответа.
В нашем примере обнаруживается, что событие «Выход пассажиров» (в описании этого событии, хранящемся также в базе знаний, имеется информация о перефразах, характерных для данного события, так что «покинули самолет» будет отождествлено с «выходом пассажиров из самолета») расположено по времени между событиями «Посадка» и «Получение багажа». Используя правила псевдофизической логики, система расширила исходный текст. Поэтому здесь возможно формирований ответа: «Пассажиры покинули самолет между 20 и 21 часами».
На третьем уровне понимания сохраняются процедуры П3, П5 и П6. Процедура П4, которая ранее реализовалась в блоке вывода ответа, усложняется и заменяется на процедуру П7, учитывающую необходимость работы с базой знаний.
|
|
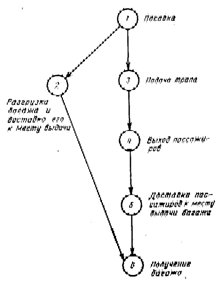
Рис.5. Интерфейс «третьего» уровня Рис. 6. Пример сценария
Сценарии могут иметь самую разную форму. Дуги, входящие в них, могут интерпретироваться не только как маркеры временных упорядочений, но и как причинно-следственные связи. Конечно, могут браться и связи, характеризующие такие отношения, как «род–вид», «часть–целое», аргумент–функция» и т. п. [6]. В искусственном интеллекте сценариям отводится центральная роль в процессах понимания текстов на естественном языке [7, 8],
4. Для четвертого уровня понимания общая структура системы остается такой же, как и на рис.5. Меняется только процедура, реализуемая блоком вывода ответа. Эта процедура обогащается за счет введения в нее эффективных средств дедуктивного вывода. В базе знаний, кроме сценариев хранится и иная информация, отражающая свойства отдельных объектов, фактов и явлений, характерных для предметной области, с которой работает система, а также совокупность различных закономерностей, характерных для процессов, протекающих в ней. Вся эта информация априорно закладывается в виде некоторых внутренних формализованных представлений в базу знаний. Специалисты, которые этим занимаются, в последнее время все чаще называются инженерами знаний или инженерами по знаниям.
Сейчас используется несколько форм представления знаний в базах знаний [9]. Наиболее популярны продукционные системы и фреймы. Продукционные системы особенно удобны для дедуктивного вывода, так как каждая продукция по сути представляет собой некоторое правило вывода вместе с условиями его применения, Общий вид продукции:
S; Р; Ecли Н, то L, W.
Здесь «Ecли Н, то L» определяет собственно продукцию, или, как часто говорят, ядро продукции. Ее интерпретация может быть различной. В логических системах вывода эта интерпретация такова: «Если Н является выведенным, то выводимо L»- Элемент продукции Р описывает условия применимости ядра. Это, как правило, совокупность некоторых предикатов, которые должны быть истинными для возможности применения правила, описываемого ядром продукции. Проблемная область естественным образом разбивается на отдельные сферы, внутри каждой из которых существуют свои продукции. Например, проблемная область, относящаяся к функционированию аэропорта, в качестве такой сферы может содержать сведения об обслуживании пассажиров, об обслуживании самолетов, об аэродромной службе и т. п. Поэтому при поиске в базе знаний нужных продукций, чтобы не затрачивать на этот поиск лишнего времени, желательно воспользоваться естественной структуризацией проблемной области. Элемент S представляет собой имя некоторой определенной сферы проблемной области. Наконец, W описывает последействие применения продукций, те изменения, которые необходимо внести в базу знаний после реализации продукции.
Организовывать дедуктивный вывод на продукциях достаточно естественно и просто. Шаги вывода могут идти от исходных данных к целям, выраженным в правых частях ядер некоторых продукций, или от целей к наличным исходным данным. Эти два метода соответствуют методам прямой и обратной волны [10] (второй метод реализуется, например, средствами языка Пролог). Именно поэтому продукционные представления столь широко распространены в экспертных системах [11, 12].
Фреймовые представления – это записи вида:
(Имя фрейма <Имя слота 1; Значение слота 1> <Имя слота 2; Значение слота 2>:...; <Имя слота N; Значение слота N». В качестве значений слота могут выступать имена других фреймов, что обеспечивает рекурсивное вложение фреймов; имена других фреймов с указанием имени связывающего их отношения, что обеспечивает организацию семантической сети из фреймов; константные (терминальные) значения; имена присоединенных процедур, специальные метки и сообщения и т. п.
Таким образом, фреймовые представления намного богаче продукционных. Но за это богатство приходится платить менее эффективными процедурами вывода, хотя в последнее время эта неэффективность начинает преодолеваться [9, 13]. Все большее число интеллектуальных систем использует фреймовые представления [14].
Между этими двумя основными формами представления знаний существует немало переходных смешанных форм, которые многим исследователям кажутся наиболее удобными [11, 14, 15].
Если вернуться к нашему иллюстративному примеру, то четвертый уровень понимания может, например, обеспечить ответ на вопрос: «Когда доставляют пассажиров к месту выдачи багажа?». Ответ на него требует не только обращения к сценарию, показанному на рис. 6, как на третьем уровне понимания, но и вывода по этому сценарию (в данном случае методом обратной волны). В результате этого вывода возникает ответ: «Пассажиров доставляют к месту выдачи багажа после посадки самолета, подачи к нему трапа и выхода пассажиров».
На четвертом уровне понимания процедура П7 усложняется, так как в ней появляются средства дедуктивного вывода. Эта новая процедура может быть обозначена как П8.
5. На пятом уровне понимания процедура П8 еще более расширяется. К дедуктивному выводу добавляются средства правдоподобного вывода. Среди них вывод по нечетким схемам, вероятностный вывод, вывод по аналогии и вывод по ассоциации. Эти «экзотические» схемы вывода в последнее время активно изучаются в работах по ИИ [16-19]. Сейчас уже можно говорить о том, что подобные методы, моделирующие особенности человеческих рассуждений и, прежде всего, рассуждений специалистов в данной проблемной области [20], начинают внедряться в практику построения интеллектуальных систем.
Для иллюстрации правдоподобного вывода используем все тот же иллюстративный пример. Пусть текст его введен в базу данных, а в базе знаний хранится сценарий, показанный на рис.6, Однако пользователь интересуется проблемой, близкой к той, которая обсуждается во введенном тексте, а не самим этим текстом. Он задает вопрос: «Улетел ли самолет, прибывший из Еревана в 12 часов?». Система, не находя информации в сноси памяти по этому поводу, вольна ответить пользователю отказом. Но на пятом уровне понимания она может обратиться к механизмам правдоподобных рассуждений. Если считать, что общие закономерности прилета и отлета самолетов существуют, то она может воспользоваться текстом в базе данных для рассуждений по аналогии. Общая схема таких рассуждений приведена на рис.7. На этой схеме G1 и G2 означают некоторые гомоморфизмы. Предполагая, что гомоморфизм G3 есть G1, можно «вычислить» вид утверждения F4. Для нашего иллюстративного примера F4 (технику вывода мы опускаем) будет звучать примерно так: «Самолет, прибывший из Еревана в 12 часов, улетел обратно приблизительно в 14 часов»,
Процедура, реализуемая на пятом уровне понимания в блоке вывода ответа, содержит в качестве своей составляющей П8 и новую составляющую П9 – совокупность разнообразных процедур правдоподобного вывода.
6. На шестом уровне понимания схема несколько видоизменяется. Она показана на рис. 8. В нее добавляется блок пополнения базы знаний. До сих пор считалось, что заполнение базы знаний происходит до начала работы системы. В течение ее функционирования содержимое базы знаний самой системой изменено быть не может. Всякое изменение этого содержимого связано с деятельностью инженера знаний.
На шестом уровне понимания это условие снимается. Здесь база знаний становится открытой. Система становится способной пополнять ее, извлекая новые закономерности и знания из наблюдений за содержимым базы данных и обработки этих наблюдений. Другими словами, система становится способной к индуктивному выводу, Сейчас разработаны мощные практические процедуры индуктивного вывода [21-23], которые с успехом могут быть использованы при пополнении базы знаний новыми закономерностями. Так, наблюдая во вводимых о базу данных текстах разницу между временем посадки самолета и временем получения багажа, система индуктивного вывода сможет установить закономерность, согласно которой эта разница в большинстве случаев (понятие «большинство» в системе индуктивного вывода формализуется) составляет около 1 часа. В результате система становится способной ответить на вопрос, ответ на который ранее в базе данных и базе знаний отсутствовал: «Какое время проходит между посадкой самолета и получением багажа?» На подобный вопрос система может дать ответ типа «В большинстве случаев между этими событиями проходит один час». Процедура индуктивного пополнения базы знаний на рис. 8 обозначена как П10.
Система общения
Мы свели уровни понимания к виду реакции системы общения на вопросно-ответное отношение. Другими словами, предполагалось, что именно режим взаимодействия «вопрос - ответ» является основным для системы общения. На самом деле в зависимости от характера использования ЭВМ в системе общения интеллектуального интерфейса могут реализоваться и другие отношения, отличные от вопросно-ответного. Если, например, ЭВМ работает по типу интеллектуальной информационно-справочной системы (ИИПС), то возникает поисковое отношение «запрос-информация», которое по ряду признаков отличается от вопросно-ответного отношения, характерного для коммуникации [24]. Если же ЭВМ используется лишь для выполнения программ, имена которых сообщает ей пользователь, то реализуется отношение «запрос-действие», получившее наибольшее развитие в робототехнических системах.
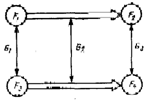
Рис.7. Схема рассуждений по аналогии
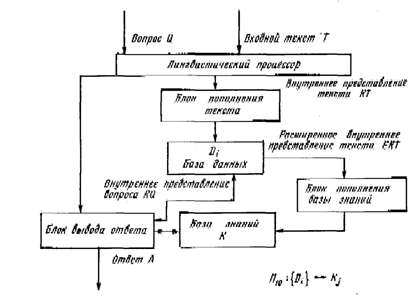
Рис.8. Интерфейс шестого уровня
При описании уровней понимания мы не затронули одну важную проблему, без решения которой трудно надеяться на создание по-настоящему интеллектуальных понимающих систем. Это проблема «денотативной эквивалентности». В текстах многие слова и словосочетания подразумевают один и тот же предмет реального или представляемого мира (денотат), И возникает проблема. как узнать, что , автор романа «Анна Каренина» и великий русский писатель, умерший на станции Астапово в 1910 году, это одно и то же лицо. В самом тексте такой информации нет. Формальным путем установить, кто скрывается под теми или иными «масками» в тексте, чрезвычайно трудно [25, 26], но эта задача, безусловно, может быть решена [2?] Поэтому так интересны и важны исследования, в которых анализировалось бы строение текста как некоторого единого целого, исследовались бы законы его порождения и построения [28-31]. В этой «горячей точке» сейчас сосредоточены усилия специалистов по интеллектуальным интерфейсам и лингвистов.
Другая проблема, связанная с общением, это необходимость в некотором сценарии самого общения. Проблема общения имеет как бы две стороны: лингвистическую, о которой мы уже достаточно подробно говорили, но не сказали еще нескольких важных вещей, и психологическую. С точки зрения лингвистики весь «разговор» пользователя с ЭВМ представляет собой некоторый специально организованный текст, стержнем которого является система целей, которую ставит перед собой пользователь, участвуя в коммуникации с ЭВМ. Эта целевая структура должна учитываться ЭВМ при организации сценария общения [27]. В противном случае пользователь не достигнет тех целей, которые его интересуют. Модели такой организации диалога сейчас стремительно развиваются в рамках нового научного направления, стоящего на границе лингвистики и психологии,– теории речевых актов. В эту теорию оказываются включеннымй и многие вопросы психологического характера. Первые исследования по психологии общения с ЭВМ [32, 33] выявили немало интересных для практики положений. Включение в общение и процесс решения задач средств машинной графики вносит в эти модели имитацию механизмов, соответствующих не символьному аналитическому мышлению, а образному, ранее практически не использовавшемуся при имитации решения творческих задач на ЭВМ [34, 35].
Можно предполагать, что намечающийся в системах общения симбиоз речевого ввода-вывода, графики и непосредственного моторного воздействия на изображение на экране с помощью «мышки» в корне изменят саму тактику общения. Особенно большие надежды специалисты возлагают на машинную графику в соединении с моторным каналом ввода-вывода. При моделировании таких систем, как конторские системы делопроизводства, на экране дисплея появляется изображение папки с делами, а ее открывание и перелистывание осуществляется с помощью движения руки, похожего на естественное движение при выполнении подобной операции. «Выдирание» документа из папки сопровождается звуком, имитирующим это действие, когда оно происходит в действительности. Ясно, что общение с такой системой максимально приближено к той реальной деятельности, которую выполняет делопроизводитель. И переучиваться ему, преодолевать психологический барьер между привычной деятельностью и работой с ЭВМ просто не приходится.
Во всяком случае, предполагается, что в ближайшие годы основная тяжесть общения с ЭВМ перейдет от систем текстового ввода-вывода к системам, комбинирующим зрительный канал ввода с моторным каналом вывода. Эффективность системы общения при этом, по мнению большинства специалистов, должна резко возрасти.
База знаний
Положение в области баз знаний таково, что следует говорить о наступлении периода создания промышленных образцов подобных систем. Эти системы реализуются либо чисто программно, либо программно-аппаратными средствами, получившими название машин баз знаний. В стандартный набор процедур, образующих базу знаний, входят процедуры ввода и кодировки информации, процедуры проверки введенной информации на непротиворечивость с ранее записанной информацией, процедуры корректировки знаний, процедуры пополнения знаний, подобные тем, которые мы упоминали в связи с описанием уровней понимания, процедуры реализации вопросно-ответного отношения. В ближайшем будущем к этим процедурам будут добавлены средства для диалогового взаимодействия инженера по знаниям с экспертом – специалистом в некоторой проблемной области, с помощью которых станет возможным «добывать знания» у эксперта. Способы реализации перечисленных процедур описаны в [36-39].
Представление знаний требует разработки специальных языковых средств, ориентированных на описание знаний и манипулирование ими. Обычные языки программирования, ориентированные на запись и реализацию процедур, плохо подходят для баз знаний. Первые попытки строить языки, специально предназначенные для баз знаний (ФРЛ, КРЛ, ОПС-5 и др.) выявили ряд трудностей, которые стоят на пути созданий эффективных средств для работы со знаниями. Так одной из причин неудач первого этапа японского проекта ЭВМ пятого поколения была плохая совместимость языков представления знаний в базах знаний с языками логического программирования, используемыми в решателях.
В настоящее время можно считать, что спор о достоинствах и недостатках языков декларативного и процедурного типов, основанных на фреймах н продукциях, разрешился полюбовно. Стало ясно, что хорошие языки представления знаний и манипулирования ими должны иметь достаточно богатые возможности как для декларативных описаний, так и дли описания процедур. Примером такого смешанного языка может служить фреймовый язык, у которого в качестве значений слотов могут выступать отдельные продукции или имена присоединенных процедур. Именно по этому пути идут сейчас все разработчики ЭВМ новых поколении.
Решатель
Основная задача решателя — это преобразование исходного описания задачи или задания на выполнение некоторой программы в рабочую программу для ЭВМ. Математически эта задача сводится к переводу исходного описания в некоторое промежуточное формализованное описание (описание на языке спецификаций, в качестве которого чаще всего выступает исчисление предикатов первого порядка или некоторое подмножество формул, допустимых в подобном исчислении). Подобная формализация рассматривается как теорема. Доказательство теоремы можно найти в рамках формальной системы, все компоненты которой хранятся в базе знаний. Средства вывода входят в решатель. Построенный вывод (при положительном результате доказательства) позволяет извлечь из него рабочую программу, нужную пользователю.
Работы по реализации подобных процедур были начаты в СССР довольно давно, раньше, чем в зарубежных странах. Первые системы такого типа ПРИЗ и СПОРА еще не были достаточно эффективными, но заложили основу теории и практики построения подобных систем [40]. В последнее время было показано, что в качестве языка, на котором функционирует решатель, можно использовать языки логического программирования, в частности язык ПРОЛОГ. Переход к языкам такого типа резко повышает эффективность процедур автоматического синтеза программ в решателях [41]. Можно предполагать, 'что подобный подход даст возможность строить вполне приемлемые с практической точки зрения решатели в ЭВМ новых поколений.
Система обоснования
Эта система должна обеспечить пользователя развернутыми ответами на его вопросы следующих типов: «Что есть Х?», «Как получен Y, «Почему получен Y, а не X?», «Зачем получен Y?», «Как устроен Z?». Вопросы первого типа требуют от системы выдачи всей информации об интересующем пользователя предмете. Они предполагают обращение к базе данных или базе знаний. Часто эту подсистему называют системой доверия. Она как бы демонстрирует пользователю свою эрудицию, широту своих знаний.
Вопросы второго типа касаются самой процедуры получения некоторого результата. В существующих сейчас системах [42, 43] ответы на подобные вопросы являются прерогативой подсистемы объяснения. Эти ответы формируются решателем, в котором сохраняется «трек» его деятельности по синтезу программы и ее реализации. Как правило, полный трек пользователя не интересует, в нем слишком много избыточной и несущественной информации. Поэтому обычно заранее строятся «заготовки» объяснений для тех мест, которые имеют принципиальное значение. Чаще всего это места разветвлений процесса», а также всевозможные условия на выбор того или иного метода решения задач. Эти заготовки наполняются решателем конкретным содержанием при решении конкретной задачи.
Вопросы третьего типа более сложны. Система должна не просто выдать трек решения или последовательность означенных заготовок, но и обосновать невозможность получения альтернативного решения, о котором спрашивает пользователь. Для того чтобы ответить на подобный вопрос, системе иногда надо провести опровергающий вывод по методу обратной волны, т. е., допустив истинность альтернативного решения, показать, что для него нет подходящих исходных, данных. В других случаях система должна проверить условия выбора при тех альтернативных переходах, при которых вместо пути, ведущего к решению Y, возникает возможность движения по пути, ведущему к решению X, и выдать пользователю обоснование сделанного выбора.
Вопросы первых трех типов используются в существующих сейчас экспертных системах, входят в число вопросов, на которые может отвечать их система объяснения. Два оставшихся типа вопросов пока не получили хороших средств для своей реализации. Вопрос «Зачем получен Y?» характерен, скорее всего, для интеллектуальных роботов, а не для интеллектуальных интерфейсов, так как это вопрос о причинах. В интеллектуальных же интерфейсах причины порождаются самим пользователем. Вопросы последнего типа нужны, как правило, не пользователю-непрофессионалу, а специалисту, который хочет разобраться в том, как функционирует система, какая форма представления знаний в ней используется, какие принципы используются при выводе решений и т. д.
Система обучения
В системах обучения (тьюторах) современных интеллектуальных систем используются старый идеи программированного обучения, ориентированного на адаптацию к ученику [44, 45]. В систему априорно закладывается сценарий обучения, пути в котором соответствуют разной скорости обучения. В программах обучения используется подсказка, пояснение, фиксация ошибок, повторение непонятного места «другими словами» и многие другие приемы, характерные для методики обучения человека.
Заключение
Как следует из всего сказанного, интеллектуальные интерфейсы позволяют решать главную проблему – обеспечивать практически мгновенный выход неподготовленного пользователя на режим решения интересующих его задач.
Интеллектуальные интерфейсы могут обладать различной мощностью. По-видимому, при их развитом промышленном производстве в продаже будет находиться спектр таких устройств – от самых простых до тех, которые реализуют все описанные выше функции. Ведущие специалисты по интеллектуальным системам считают, что, корее всего, интеллектуальные интерфейсы будут набираться из стандартных блоков, образующих целые семейства (ряды). Предполагается, что в качестве стандартных блоков будут выступать именно те блоки, которые показаны на рис.1.
По многим прогнозам, системы, подобные интеллектуальным интерфейсам, описанным в этой статье, получат массовое распространение, начиная с середины 90-х годов.
Литература
1. Роspelov D. Мodels of Human Communication: Dialogue with Computer// International Journal of General Systems. – 1986. – Vol.12, №4. – P.333-338.
2. Weizenbaum J. ELIZA – A Computer Program for the Study of Natural Language Communications Between Man and Machine// CACM. – 1974. – Vоl.9, №1. – Р. З8-49.
3. Лингвистическое обеспечение информационных систем. – М.: ИНИОН АН СССР, 1987.
4. Севбо связного текста и автоматизация реферирования. – М.: Наука, 1987.
5. , Поспелов эволюционируют диалоговые системы// Механизмы вывода и обработки знаний в системах понимания текста. Ученые записки ТарГУ. Вып. 621.– Тарту: ТарГУ, 1983. – С.86-100.
6. Поспелов управление. Теория и практика. – М.: Наука, 1986.
7. Обработка концептуальной информации: Пер. с англ.– М.: Энергия, 1980.
8. Schank R. Reminding and Memory Organization: an Introduction to MOP’s// Strategies
for Natural Language Processing/ W. G.Lehnert, M. H.Ringle. – Hillsdale NJ: Lawrence Erlbaum, 1982. – P.455-494.
9. Искусственный интеллект: Пер. с англ. – М: Мир, 1980.
10. Поспелов -лингвистические модели в системах управления. – М.: Энергоатомиздат, 1981.
11. Микулич создания экспертных систем// Теория и модели знаний. Ученые записки Тартуского госуниверситета. Вып. 714. – Тарту: ТарГУ, 1985. – С.87-115.
12. Принципы искусственного интеллекта: Пер. с англ. – М.: радио и связь, 1985.
13. Вагин дедукция на семантических сетях// Изв. АН СССР: Техническая
кибернетика. – 1986. – № 5. – С.51-61.
14. , Осипов Байсл дли представления знаний// Изв. АН СССР: Техническая кибернетика. – 1986. – № 5. – С.29-42.
15. Лозовский и дефиниторная семантика системы представления знаний// Кибернетика. – 1979. – № 2. – С.98-101.
16. Пойа Дж. Математика и правдоподобные рассуждении. – М.: ИЛ, 1957.
17. , Поспелов решений при нечетких основаниях. Правила вывода// Изв. АН СССР: Техническая кибернетика. – 1978.— №2. – С.5-11.
18. Чесноков в детерминационном анализе// Изв. АН СССР: Техническая кибернетика. – 1984. –'№5. – С. 55-8З.
19. Ефимов исчисление//Изв. АН СССР: Техническая кибернетика. – 1986. – №5. – С. 62-81.
20. О «человеческих» рассуждениях в интеллектуальных системах// Логика рассуждений и ее моделирование. – М.: Научный совет по комплексной проблеме «Кибернетика» ан СССР, 1983. – С. 5-37.
21. Гавранек Т. Автоматическое образование гипотез: математические основы общей теории: Пер. с англ. – М.: Наука, 1984.
22. О машинно-ориентированной формализации правдоподобных рассуждений в стиле Ф. Бэкона - // Семиотика и информатика. Вып.20. – М.: ВИНИТИ, 1983. – С. 35-101.
23. , , Финн средства экспертных систем типа ДСМ // Семиотика и информатика. Вып.28. – М.: ВИНИТИ, 1986. – С. 65-101.
24. , , и др. Некоторые проблемы фактографического поиска// Вопросы информационной теории и практики. – 1983. –№ 49. – С 5-33.
25. Падучева связи и глубинная структура текста// Проблемы грамматического моделирования. – М.: ВИНИТИ, 1973. – С. 96-107.
26. , Блехман определенности и сверхфразовые синтаксические связи в тексте// Научно-техническая информация. Сер. 2. – 1981. – №9. – С.22-26.
27. Моделирование языковой деятельности в интеллектуальных системах/ Под ред. , . – М.: Наука, 1987.
28. Ыйм X. Эпизоды в структуре дискурса// Представление знаний и моделирование процессов понимания. – Новосибирск: ВЦ СО АН СССР, 1980. – С.79-86.
29. Вейценбаум Дж. Понимание связного текста вычислительной машиной// Распознавание образов: Исследование живых и автоматических распознающих систем. – М.: Мир, 1970. –С.214-245.
30. Попов с ЭВМ на естественном языке. – М.: Наука, 1982.
31. Гаазе-, , Семенова структур волшебных сказок. – М.: Научный Совет по комплексной проблеме «Кибернетика» АН СССР, 1980.
32. Тихомиров мышления. – М.: МГУ, 1984.
33. Горелов с компьютером. Психолингвистический аспект проблемы. – М.: Наука, 1987.
34. Зенкин ЭВМ на этапе построения научных теорий. Некоторые подходы и результаты // Автоматизация научных исследований. – М.: МГУ, 1984. – С.63-72.
35. , Горский видеоданных: состояние и тенденции развития// Прикладная информатика. – М.: Финансы и статистика, 1987. – С. 24-52.
36. Представление знаний в человеко-машинных и робототехнических системах. исследования в области представления знаний. – М.: ВИНИТИ, 1984.
37. , Сильдмяэ структуры в представлении знаний в диалоговых системах // Изв. АН СССР: Техническая кибернетика. – 1980. –№5. – С.83-89.
38. Клещев знаний. Методологические формализмы, организация вычислений и программная поддержка// Прикладная информатика. – 1983. – Вып.1. – С. 49-94.
39. Вейшелл знаний и обработка естественных языков // ТИИЭР. – 1986. – Т. 74, № 7. – С.11-30.
40. Система программирования МИКРОПРИЗ// Под ред. , , Э. X. Тыугу. – Таллин: ИК АН ЭССР, 1987.
41. Ломп синтез программ с помощью системы ПРОЛОГ// Изв. АН ЭССР. Сер: Физика и математика. – 1985. – № 34. – С.125-132.
42. Молокова индивидуального объяснения в экспертных системах// Изв. АН СССР: Техническая кибернетика. 1985. – №5. – С. 103-114.
43. , Стефанюк системы – состояние и перспектива// Изв. АН СССР: Техническая кибернетика. – 1984. – № 5. – С. 153-167.
44. Человеко-машинные обучающие системы // под ред. . – М.: Научный Совет по комплексной проблеме «Кибернетика» АН СССР, 1979.
45. Бабиков -машинные обучающие системы. – М.: ИПУ, 1985.
