


Информационно-поисковые системы — ИПС
Поскольку задача исчерпывающего поиска неразрешима, то человечество задумалось над «средствами механизации» поиска, которые позволяли бы решать поисковые задачи в удовлетворительном приближении. Такие «средства механизации» вынуждены работать с тем «материалом», который присутствует в слабо структурированной информации — словами естественного языка. Использование слов в том виде, в котором они присутствуют в документах, неэффективно — ведь в таком случае информационно-поисковая система вынуждена была бы просматривать документы один за другим — почти так же, как это делает человек. Хотя ИПС может просматривать документы очень быстро, но в тех случаях, когда количество документов достигает сотен тысяч (как в юридических ИПС) или миллиардов (как в ИПС Интернета), прямой «механический» просмотр всех документов требует значительного времени. Поэтому ИПС почти никогда не работают непосредственно с исходными документами. Вместо исходных документов ИПС используют их представления — т. н. поисковые образы документов (ПОД). Преобразование документа в его ПОД в различных ИПС происходит по-разному. Ниже при обсуждении различных типов документальных ИС мы рассмотрим процессы формирования ПОД для них.
С другой стороны, и общение пользователя (пытающегося с помощью ИПС удовлетворить свою информационную потребность) с ИПС также не является простым процессом. Обращение к ИПС с запросом на поиск обычно не может быть реализовано с помощью экрана (бланка) запроса, содержащего набор простых локальных критериев. Ведь слов в документах много, и лобовой подход, объявляющий каждое слово объектом такого локального критерия потребовал бы столько полей ввода в экране запроса, сколько присутствует отдельных слов в самом большом документе, хранимом документальной ИС.
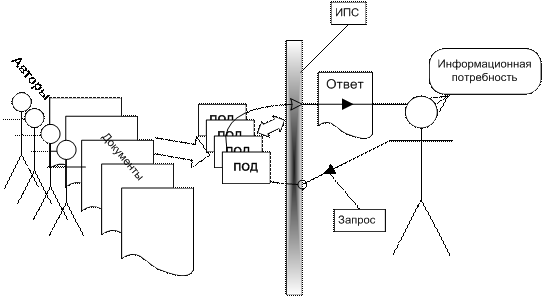 |
Рис. 17. Запрос к ИПС и ответ ИПС
Запрос к ИПС
Зачастую вместо экранов запросов (и/или вместе с экранами запросов) документальные информационные системы используют языки запросов (информационно-поисковые языки, ИПЯ), и для общения с ИПС информационная потребность должна быть выражена средствами, которые эта ИПС «понимает» — должен быть сформулирован запрос на формальном входном языке запросов ИПС.
В ответ на запрос ИПС передает отчет — список найденных документов, так или иначе идентифицирующий эти документы.
Понятие релевантного документа
Запрос редко может точно выразить информационную потребность — ведь информационная потребность невербализуема, а запрос, как правило, требуется писать на формальном языке.
Однако многие ИПС по разным причинам не могут определить, соответствует ли тот или иной документ запросу — ведь они работают не с самими документами, а с их ПОДами. Степень соответствия документа запросу называется релевантностью. Релевантный документ может оказаться непертинентным и наоборот.
Пример
Известна (американская) ИПС, которая на запрос, состоящий из единственного слова “Russia” (Россия), выдает список документов, в первом из которых этого слова нет вообще, но зато есть слово “Gagarin”. Этот документ нерелевантен, но пертинентен для массовой американской аудитории.
В случае, когда ищется информация о шлюпочных якорях (кошках), запрос, состоящий из слова «кошка», почти в любой ИПС даст массу релевантных, но непертинентных документов.
Полнота и точность информационного поиска
Введем некоторые формальные определения. Пусть
Δ — множество документов, ПОДы которых представлены в документальной ИС;
π — общее количество пертинентных документов в Δ; обычно π много меньше, чем D — общее количество документов, ПОДы которых представлены в документальной ИС;
F — количество найденных по определенному запросу документов;
P — количество найденных пертинентных документов, P<F; P≤π;
Полнота (recall) задается отношением
![]()
Точность (precision) информационного поиска задается отношением
![]()
Шум (noise) — это величина, дополнительная к точности:
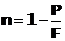
Для широкого класса ИПС и запросов к ним имеет место (полученное по результатам многочисленных экспериментов) соотношение дополнительности:
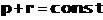
Таким образом, если по каким-то причинам требуется произвести более или менее исчерпывающий поиск (обеспечить его высокую полноту), то придется мириться с высоким шумом (низкой точностью поиска).
Сказанное можно проиллюстрировать двумя модельными ситуациями поиска. В первой ситуации найден один-единственный пертинентный документ. В этом случае точность p=1, а шум n=0. Но и полнота r, видимо, близка к нулю, поскольку многие из присутствующих в ИС пертинентных документов не найдены. В качестве другой модельной ситуации будем рассматривать все множество Δ как результат поиска. Тогда, напротив, шум, как правило, велик (в этом случае точность p=π/D почти равна 0), а полнота равна 1.
Реальные ситуации документального поиска располагаются между приведенными модельными ситуациями, давая или высокий шум, или высокую полноту поиска.
Координация терминов
Почти очевидно, что слова в документах, создаваемых людьми, встречаются вовсе не в случайном порядке, и этот факт, видимо, можно использовать при разработке информационно-поисковых систем. Слова (строго говоря, лексические единицы) текста документа образуют друг с другом устойчивые сочетания, имеющие определенное смысловое содержание. Такие сочетания лексических единиц называют терминами. Термин обычно означает некоторое понятие. Одно и то же понятие может быть обозначено различными терминами («компьютер» ~ «электронная вычислительная машина»); в таком случае говорят о синонимии терминов.
Пространственные (текстуальные) связи лексических единиц, образующие термин, называются отношением координации. Термины, в свою очередь, также могут находиться друг с другом в отношениях координации, образуя новые термины, обозначающие более общие понятия.
В процессе информационного поиска человек явно или неявно осуществляет координацию лексических единиц и терминов оцениваемых документов. Поэтому уже в начале XX века возникла идея использовать предварительную (до поиска) координацию терминов (тогда бумажных) документов, осуществляемую обученными специалистами. Результаты такой координации — поисковые образы документов, состоящие только из терминов. В результате в библиотеках возникли сначала предметные, а затем и систематические каталоги. Аналоги этих типов каталогов встречаются в Интернете и других документальных информационных системах. Такого рода документальные информационно-поисковые системы называются ИПС с предкоординацией терминов (или просто ИПС с предкоординацией — ИПС с предкоординированными ИПЯ — предкоординированные ИПС).
Можно, однако, возложить всю работу по координации на того, кто ищет, предоставив ей/ему возможность непосредственно работать с лексическими единицами текста документов. Такой подход к осуществлению информационного поиска называется посткоординацией терминов. В бумажную эру это было непросто, и далее алфавитных авторских каталогов (в которых присутствовали только лексические единицы одного-единственного типа — фамилии авторов документов) дело заходило редко. Однако с появлением компьютеров создание посткоординированных ИПС стало реальностью. Такие ИПС широко используются, например, для реализации юридических документальных информационных систем и для поиска во Всемирной паутине.
Рассмотрению особенностей пред - и посткоординированных ИПС посвящены следующие лекции.
Лекция 8. Предкоординированные ИПС
Предметные ИПС
Предметная ИПС устроена наиболее просто. На основе анализа взаимной встречаемости терминов формируется список «предметов», о которых говорится в документах. Предмет, как правило, является достаточно абстрактным понятием. Предметом может быть что-нибудь вещественное, например, «яблоко» (на самом деле, абстрактное яблоко, представляющее собой — как термин — некоторое множество некоторых аспектов реальных яблок), но может быть и нечто невещественное, например, «индийская музыка». С названием предмета связываются списки соответствующих документов.
Это особенно удобно, если полный перечень предметов невелик — предметная ИПС представляет собой «полки», на которых лежат ссылки на ресурсы, относящиеся к названию полки («предмету»):
Предметная ИПС
---
|
|------- Абажуры
|
|------- Бублики
|
|------- Индийская музыка
|
|------- Куклы
|
|------- Музыка
|
|------- Программирование на языке Perl
|
|------- Яблоки
|
|------- Яблони
Такие «полки» с названиями предметов называются предметными рубриками, а сам перечень предметных рубрик — рубрикатором. Предметная рубрика предкоординированной ИПС, кроме названия предмета, может содержать перечни координированных лексических единиц и терминов, отражающих содержание понятия, описываемого этой рубрикой.
Предметные каталоги появились в библиотеках в начале XX века и продолжают развиваться. В настоящее время предметные каталоги крупных библиотек (например, Российской национальной библиотеки в Санкт-Петербурге) насчитывают 20—30 и более тысяч предметных рубрик. Прямой ручной переборный поиск в таких списках рубрик невозможен, поэтому все мало-мальски значительные по размерам предметные ИПС оснащаются дополнительным поисковым аппаратом (например, посткоординированной ИПС, в которой документами являются названия предметных рубрик, а в бумажных каталогах библиотек — хотя бы так называемым алфавитным ключом, указывающим, в каком ящике искать рубрики, названия которых начинаются на определенную букву).
При создании предметной ИПС всегда встают два основных вопроса:
- Какие же термины следует считать «предметами»? (Следует ли, например, считать яблоко предметом?) Каков объем понятия, относящегося к «предмету»? (Что есть яблоко?)
В библиотеках для решения этих вопросов создаются специальные группы сотрудников, называемые «комиссией по предметизации». Фактически эти группы являются авторами предметных ИПС. Кроме описания решений, принятых по приведенным выше вопросам, комиссия по предметизации разрабатывает инструкции, пользуясь которыми другие сотрудники библиотеки (работники отдела предметизации, предметизаторы) и осуществляют предметизацию — приписывание документам предметных рубрик.
В результате функционирование предметной ИПС можно представить схемой (Рис. 18).
Рис. 18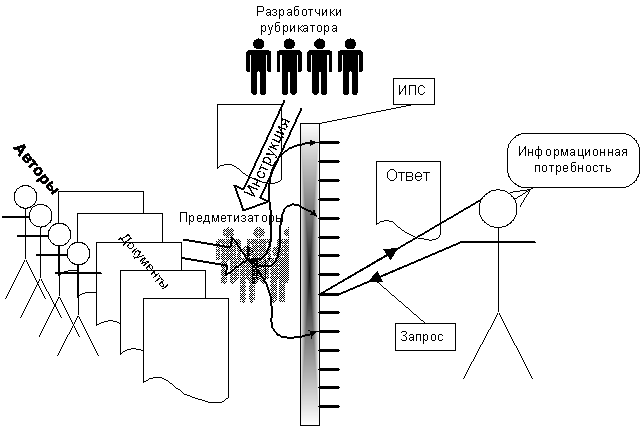
. Схема функционирования предметной ИПС
Обратим внимание на то, что на этой схеме присутствуют, кроме авторов документов и пользователя ИПС, еще две группы людей: разработчики рубрикатора и предметизаторы. Культуры, в которые погружены эти группы людей, зачастую отличаются друг от друга и от культур авторов и пользователей ИПС.
Работа предметизатора также включает оценку (к какой предметной рубрике отнести документ — в соответствии с содержание его текста). Если предметизаторы (принадлежа к другим культурам, нежели культура разработчиков рубрикатора) не следуют строго инструкции по предметизации, то документы оказываются приписанными к иным, чем предполагалось, рубрикам.
Если пользователь не понимает, как устроена культура разработчиков рубрикатора, он не в состоянии обратиться к той предметной рубрике, которая должна содержать документы, пертинентные его информационной потребности. Ниже (при рассмотрении классификационных ИПС) мы увидим подобные примеры. Вековая история использования предметных каталогов в библиотеках позволила выработать два приема, позволяющие в этом случае смягчить проблему межкультурной коммуникации. Эти приемы называются отсылкой и ссылкой.
Отсылка
Если комиссия по предметизации полагает, что в культурах пользователей существуют синонимичные названия предметов («компьютер» ~ «электронная вычислительная машина»), то в рубрикатор вносятся оба этих названия, однако все документы, релевантные данному предмету, приписываются только к одной из рубрик. Вторая остается пустой, в нее помещается текст «См. (смотри) <имя наполненной рубрики>» — отсылка.
Ссылка
Зачастую, однако, в рубрикаторе присутствуют близкие по значению или как-то иначе связанные предметные рубрики. В этом случае используется ссылка — «См. также <имя наполненной рубрики>»
WebRing — предметная ИПС Интернета
 |
В середине 90-х годов XX века Web-мастера, занимающиеся, как они считали, одним предметом, начали ставить на своих сайтах ссылки на сайты коллег, создавая кольцевые ссылочные структуры (Рис. 19).
Рис. 19. Веб-кольцо — кольцевая ссылочная структура
В июне 1995 г. появился сайт WebRing [http://www. webring. org], объединивший несколько колец. В настоящее время на этом сайте "присутствуют" более 50 тыс. колец, которые в общей сложности включают более 900 000 сайтов, т. е. средний размер кольца — около 18 сайтов. Есть, однако, и кольца-гиганты, содержащие тысячи сайтов. Участники таких колец используют не только двусторонние ссылки (как показано на рисунке), но и ссылки «через сайт» и случайные ссылки, генерируемые программным образом.
Понятно, что найти нужный предмет интереса при большом количестве предметов непросто. WebRing обзавелся собственными вспомогательными ИПС — классификационной и словарной, помогающими найти название предмета.
Поскольку предметные рубрики WebRing не были разработаны какой-либо организацией, а процесс предметизации в WebRing стихиен, то межкультурные проблемы сказались на этой ИПС самым существенным образом. Существует множества непересекающихся веб-колец с идентичной тематикой — их авторы по каким-то причинам не желают взаимодействовать друг с другом. Некоторые тематики (например, классическая музыка) представлена на WebRing весьма ограниченно, а многие другие (зачастую, маргинальные, например, рокеры) — очень широко. Это явление связано с уровнем активности соответствующей культурной группы. И, конечно, основной язык представленных на WebRing сайтов — английский.
В силу сказанного, WebRing обладает ограниченной ценностью как поисковая ИПС Всемирной паутины.
Классификационные ИПС
В классификационных ИПС используется иерархическая (древовидная) организация информации, которая называется КЛАССИФИКАТОРОМ. При такой организации ИПС есть не очень много (обычно менее двух десятков) "больших полок", каждая из которых разделена на несколько меньших, каждая из которых, в свою очередь, вновь разделена на еще более мелкие...
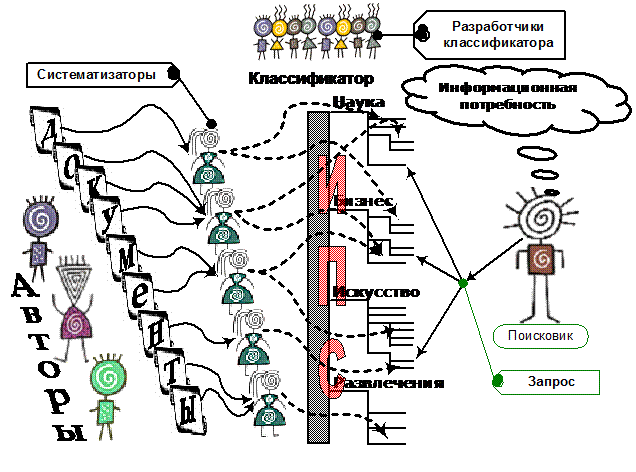
Рис. 1 Классификационная ИПС — продукт взаимодействия многих культур
Разделы классификатора называются РУБРИКАМИ. Библиотечный аналог классификационной ИПС — систематический каталог. Классификатор разрабатывается и совершенствуется коллективом авторов. Затем его использует другой коллектив специалистов, называемых СИСТЕМАТИЗАТОРАМИ. Систематизаторы, зная классификатор, читают документы и приписывают им классификационные индексы, указывающие, каким разделам классификатора (рубрикам) эти документы соответствуют.
Классический пример классификационной ИПС — Yahoo (www. ). Едва появившись, быстро завоевала признание качественной проработкой классификатора. Сейчас в Yahoo работают более 100 систематизаторов.
Классификационные ИПС обладают рядом специфических недостатков. Уже разработка классификатора связана с оценкой относительной важности различных областей человеческой деятельности. Например, сравнивая классификаторы многих ИПС Интернета (таких, как Yahoo, Lycos, Look Smart), замечаем, что во многих из них нет раздела "Наука". Любая оценка является социальным действием; она связана с обществом, культурой, социальной группой, к которым принадлежит человек, выносящий оценку. Поэтому уже классификаторы, созданные разными коллективами в разных странах, могут иметь весьма различную степень полезности при поиске информации — все зависит от того, кто и что ищет. Но в создании классификационных ИПС участвуют еще и коллективы систематизаторов, также выносящих свои оценки о соответствии документов разделам классификатора.
Взаимодействие культур при поиске в классификационной ИПС
Таким образом, при поиске информации с помощью классификационных ИПС возникает необходимость взаимодействия с другими культурами — культурами авторов, создателей классификаторов и систематизаторов.
Это непростая задача. Существует профессия, решающая эту задачу — переводчики. Хороший переводчик переводит не только слова, но и то, что называется "культурные реалии". В случае информационного поиска соответствующий профессионал называется "ИНФОРМАЦИОННЫЙ БРОКЕР". Он владеет когнитологическими методиками, знает, как устроены классификаторы и как их интерпретируют систематизаторы. Эти знания позволяют информационному брокеру в беседе с вами изучить вашу информационную потребность и превратить ее в запрос. В библиотеках такие "информационные брокеры" работают в информационных и библиографических отделах. Информационные брокеры Интернет у нас в стране уже встречаются, хотя пока еще редко.
Библиографы, понимая, что читатели не всегда глубоко изучают классификации, положенные в основу систематических каталогов, выработали два приема, облегчающие жизнь читателям. Эти приемы носят название "ОТСЫЛКА" и "ССЫЛКА", и оба они применяются создателями классификационных ИПС Интернета.
Эти приемы используются в ситуации, когда документ может быть отнесен к одному из нескольких разделов классификатора, а лицо, осуществляющее поиск (поисковик), может не знать, к какому именно разделу.
Ссылка и отсылка
Отсылка используется тогда, когда создатели классификатора и систематизаторы в состоянии принять четкое решение об отнесении документа к одному из разделов классификатора, а поисковик с определенной вероятностью в поисках этого документа придет в другой раздел. Тогда в этом другом разделе помещается отсылка ("См.") в тот раздел классификатора, в котором действительно размещена информация о документах данного типа.
Например, информация о картах стран может быть размещена в разделах "Наука · География · Страна", "Экономика · География · Страна" или "Справочники · Карты · Страна". Принимается решение, что карты стран помещаются во второй раздел: "Экономика · География · Страна"; тогда в остальные два раздела помещаются отсылки в него. Этот прием активно используется в ИПС Yahoo (отсылка обозначается в ней знаком @).
Ссылка ("См. также") используется в менее однозначной ситуации, когда даже создатели классификатора и систематизаторы не в состоянии принять четкого решения об отнесении документов к определенному разделу классификатора. В ИПС Интернет ссылка принимает разнообразные формы ("Relevant servers", "Похожие документы" и т. п.).
Классификационных ИПС в Интернет много. Большие классификационные ИПС (американская Yahoo, европейская EuroSeeek, российские ***** и *****) используют вспомогательные словарные ИПС по собственным рубрикам (аналоги библиотечных алфавитных указателей). Другие классификационные ИПС просто существуют совместно с ИПС словарного типа (Excite, Lycos, *****, AltaVista).
Лекция 9. Словарные ИПС
Введение
Культурные проблемы, связанные с использованием классификационных ИПС, привели к созданию ИПС словарного типа, с обобщенным англоязычным названием search engines. Основная идея словарной ИПС — создать словарь из слов, встречающихся в документах Интернета, в котором при каждом слове будет храниться список документов, из которых взято данное слово. Если поиск слов в таком словаре выполняется быстро, то можно отказаться от услуг разработчиков классификаторов и от услуг систематизаторов, оставаясь один на один с авторами документов.
К счастью, несмотря на обилие слов (и словоформ) в естественных языках, большинство из них употребляются нечасто, что было замечено ученым лингвистом Ципфом еще в конце 40-х годов нашего века. К тому же наиболее употребительные слова — это союзы, предлоги и артикли, т. е. слова, совершенно бесполезные при поиске информации. В результате словарь одной из самых крупных словарных ИПС Интернета — AltaVista — имеет объем всего лишь несколько Гбайт.
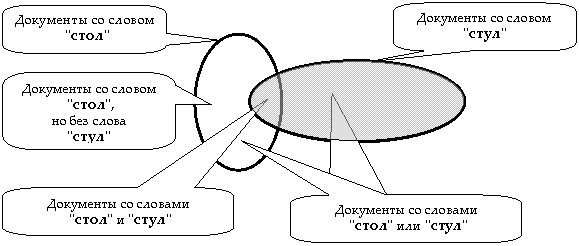
Поскольку слова в словаре упорядочены, поиск нужного слова может выполняться достаточно быстро — без последовательного просмотра. А наличие списков документов, в которых встречается искомое слово, позволяет ИПС выполнять операции с этими списками — их слияние, пересечение или вычитание (для наглядности списки документов изображены в виде овалов):
Рис. 2 Логические операции с множествами документов,
выполняемые словарными ИПС
Логические операторы
Вместо того, чтобы говорить "Список документов содержащих слово 'стол' или документов, содержащих слово 'стул'", употребляются сокращенные выражения, приведенные на предыдущем рисунке. Дальнейшее сокращение эти выражения находят в языке запросов словарных ИПС: вместо "Найти список документов содержащих слово 'стол' или документов, содержащих слово 'стул'", большинству словарных ИПС достаточно написать что-то вроде
стол ИЛИ стул
Союз ИЛИ в запросе к словарной ИПС выступает в роли ЛОГИЧЕСКОГО ОПЕРАТОРА, связывающего множества искомых документов. Словарные ИПС используют три логических оператора: ИЛИ, И и И-НЕ ("но без"); как правило, эти операторы обозначаются одним из следующих способов:
Оператор | Полное | Сокращенное | Обозначение при простом поиске |
ИЛИ | OR | | | пробел |
И | AND | & | + (знак "плюс") |
И-НЕ | AND NOT | ! или &! или!& | - (знак минус) |
Эти операторы имеют приоритет (прежде всего выполняется И-НЕ, затем — И, и лишь потом — ИЛИ), поэтому для составления сложных запросов могут использоваться скобки (исключение составляют лишь ИПС и Google, которые вместо скобок применяют другие обозначения). Как правило, словарные ИПС Интернета предоставляют пользователям два интерфейса — режим "сложного запроса" ("advanced search"), в котором доступны все логические операторы, и режим простого поиска, в котором, как правило, невозможно использование скобок, и, следовательно, можно использовать не все сочетания операторов.
Правое усечение
Давайте рассмотрим гипотетический пример поиска информации о столах. С учетом падежей слова "стол" и наших знаний о логических операторах, запрос к словарной ИПС мог бы выглядеть так:
стол ИЛИ стола ИЛИ столу ИЛИ столе ИЛИ столом
Хорошо, что это только одно слово, но писать такое уже довольно тоскливо.
Западные ИПС, ориентированные на английский язык, предлагают простое решение: вместо слова можно написать его начало, заменив изменяемую часть звездочкой:
стол*
Формально говоря, звездочка заменяет любое количество символов, поэтому говорят, что она обозначает правое усечение. Называть обозначение "стол*" язык не поворачивается, поэтому для таких частей логических выражений запросов используется название ТЕРМИН.
Запрос
стол*
отыщет и документы со словами "столовая", "столешница", "столоначальник" и даже "столб". Такое явление — искусственная синонимия — может сильно мешать при поиске, однако его проявление зачастую невозможно предусмотреть заранее.
От чего пытались убежать, переходя от использования классификационных к применению словарных ИПС — от изучения других культур — к тому вернулись с другой стороны: язык, на котором написаны искомые документы (а, следовательно, и культуру авторов этих документов) все равно приходится изучать.
Для устранения искусственной синонимии необходимо читать найденные документы, которые образуют информационный шум, определять в них те термины, которые являются порожденными нами искусственными синонимами, и устранять их, модифицируя запрос:
стол* И-НЕ (столова* ИЛИ столеш* ИЛИ столон* ИЛИ столб* ...)
Заметим, что в новом запросе нельзя написать "столов*" вместо "столова*" — пропадет родительный падеж множественного числа слова "стол"; точно также нельзя написать "столе*" вместо "столеш*" — пропадет предложный падеж слова "стол". Таким образом, язык искомых документов необходимо знать не просто хорошо ;-)
Две российские ИПС (Апорт и Яндекс) "знают" русскую грамматику (точнее, морфологию русского языка) и в словаре хранят только так называемую "нормальную форму" слова (для существительного — именительный падеж единственного числа). Эти системы допускают написание запроса на естественном языке, нормализуя термины запроса, тем самым существенно упрощая поиск в русском Интернете.
Слова далекие и близкие
Описанные возможности словарных ИПС, хотя и достаточно мощные, зачастую оказываются совершенно недостаточными для поиска даже очень простой информации. Попробуем решить следующую задачу: отыскать сведения о продаже металлических стульев:
металлическ* И стул*
Но этому запросу отвечает прейскурант торговой фирмы, продающей плетеный (вторая строка прейскуранта) и (178 строка прейскуранта). Оператор отыскивает документы, в которых искомые слова встречаются в любом месте!
Для устранения этого недостатка некоторые ИПС хранят не просто список документов, в которых встречается слово, но и номер этого слова в конкретном документе. Это позволяет в языке запросов такой ИПС использовать оператор РЯДОМ, что решает поставленную задачу:
металлическ* РЯДОМ стул*
Многие ИПС не позволяют написать такой запрос — они не разрешают использовать термины с правым усечением совместно с оператором РЯДОМ, (только слова), но это ограничение постепенно снимается, — следите за информацией на конкретных ИПС.
Оператор РЯДОМ в различных ИПС обозначается по-разному (он имеется в AltaVista, Lycos, Апорт и Яндекс и во всех этих ИПС используются разные обозначения). Более того, в разных ИПС он может иметь и несколько различный смысл. Так, AltaVista считает, что РЯДОМ — это не более чем через 10 слов в любом порядке, в то время как другие ИПС позволяют указывать требуемое расстояние между словами (ровно столько-то или не более чем столько-то). Lycos позволяет указывать расстояние и требуемый порядок слов. Апорт позволяет указывать расстояние между словами в словах; Яндекс — в словах и абзацах (с возможностью указать порядок следования слов).
Ранжирование результатов поиска
Словарные ИПС способны выдавать списки документов, содержащие миллионы ссылок. Даже просто просмотреть такие списки совершенно невозможно. Было бы удобно иметь возможность задать формальные критерии (хотя бы относительной) важности (с точки зрения пертинентности) документов с тем, чтобы наиболее важные документы попадали бы в начало списка.
Многие ИПС предоставляют такую возможность ранжирования результатов поиска. Методы ранжирования в разных ИПС различны. Так, AltaVista позволяет (в режиме сложного поиска) указать перечень терминов, которые повышают ранг найденного документа (т. е. перемещают его в начало списка), что для AltaVista особенно актуально, так как эта ИПС показывает только первые 200 найденных документов. Яндекс позволяет указать вес каждого из терминов, участвующих в запросе, что позволяет весьма точно настраивать порядок следования найденных документов.
Лекция 10. Стратегия поиска: использование нескольких источников
Дать общий рецепт эффективной стратегии поиска информации в Интернете, пожалуй, невозможно. Есть лишь некоторые принципы, позволяющие тратить меньше времени. Попробую их изложить.
Начну с примера. Если вам необходимо узнать, где растет древовидная черника, то вряд ли вы пойдете в алфавитный каталог библиотеки. Может быть, вы найдете нужную литературу с помощью систематического каталога. С несколько большей вероятностью — с помощью предметного. Но, скорее всего, ни один из библиотечных каталогов вам не поможет. Зайдите, однако, в информационно-библиографический отдел крупной библиотеки, и дежурный библиограф достанет библиографический указатель по кустарничкам или какую-то похожую книжицу, из которой вы и найдете ответ на свой вопрос.
Подобную стратегию можно с успехом применять и в Интернет. В ИПС общего назначения можно утонуть в тысячах ссылок, выданных вам на простой запрос.
Целью использования универсальной ИПС общего назначения
может быть поиск специализированной ИПС,
посвященной тематике вашего поиска.
Такая ИПС может быть распознана по наличию слов "информация (information)", "указатель (directory)" и т. п. в найденных в универсальной ИПС документах. Но часто специализированная ИПС может скрываться на сервере общественной, профессиональной или специализированной организации, издательства.
Пример из жизни
Иногда приходится разыскивать несколько информационных систем со все более узкой тематикой.
Однажды ко мне обратились с просьбой срочно найти информацию о продаже судов-сухогрузов (по-английски — bulker). Запрос в AltaVista (простой поиск)
+bulker* +sale*
дал нулевой результат; запрос
+ship* +sale*
дал тысячи ссылок на страницы, посвященные продажам катеров и яхт (впрочем, попалась и одна баржа).
Внимательное изучение нескольких первых страниц списка результатов поиска показало, что в найденных текстах часто присутствует слово "marine (морской)". И тут я вспомнил, что есть в английском языке слово "maritime", означающее "все морское". Запрос
+maritime +information*
уже среди первых десяти ссылок содержал ссылку на расположенную на www. GeoCities.com информационную систему по морской тематике. Но и в ней информации о продаже сухогрузов не было. Зато была информация об отправке сухогрузов из портов мира, включающая сведения о владельцах судов. Многие из фирм — владельцев судов имели в своем названии слова "ship brokers (торговцы судами)". Этого английского выражения я не знал. Однако запрос в AltaVista
+ship* +broker*
дал мне огромный список страниц, среди которых была одна с уже знакомым адресом — www. GeoCities.com. Оказывается, существует специализированная ИПС по торговцам судами!
Второй найденный с помощью такой ИПС торговец содержал Web-сервер, на котором нашелся подходящий сухогруз.
Еще два элемента стратегии
Приведенный пример иллюстрирует еще один элемент стратегии: читайте найденные документы в поисках наиболее точных терминов и связей между терминами. Возможно, вы мыслите совершенно не в тех терминах, которые используют авторы искомых документов (вспомним о культурных различиях!).
Третий элемент стратегии: используйте несколько ИПС. Если вы регулярно занимаетесь поиском информации по какой-то тематике, отметьте те ИПС. которые для вас наиболее эффективны.
[1] Для доработки и/или исправления ошибок в ИС зачастую необходимо иметь информацию о языке программирования, на котором разработан компонент информационной системы.
[2] Так поступают потому, что средства разработки, как правило, не бывают доступны в процессе эксплуатации информационной системы.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
