



Нужны ли семантические сети для
обработки естественного языка?
Дмитрий Алексеевич Усталов (*****@***uran. ru) – младший научный сотрудник, Институт математики и механики им. Уральского отделения Российской академии наук, Россия, Екатеринбург
Аннотация. Семантические сети представляют знания об окружающем мире и широко используются для решения задач обработки естественного языка. При этом многие важные задачи сегодня успешно решаются без использования семантических сетей благодаря машинному обучению. Неужели сотни и тысячи человеко-часов были потрачены зря? Данная статья, посвящённая этому вопросу, представляет обзор исследований и содержит ответ на вопрос.
Ключевые слова: семантическая сеть, инженерия знаний, тезаурус, машинное обучение, обзор.
Do We Need Semantic Networks for
Natural Language Processing?
Dmitry Alekseevich Ustalov (*****@***uran. ru) – Junior Fellow, Krasovskii Institute of Mathematics and Mechanics, Russia, Yekaterinburg
Abstract. Semantic networks that represent common sense knowledge are widely used for addressing natural language processing problems. However, many of these problems are nowadays successfully solved without the of semantic networks thanks to machine learning. Had hundreds and thousands of man-hours been wasted? This paper, devoted to this question, presents a survey that hopefully answers it.
Keywords: semantic network, knowledge engineering, thesaurus, machine learning, survey.
Обработка естественного языка — общее направление искусственного интеллекта и математической лингвистики, изучающее проблемы компьютерного анализа и синтеза естественных языков. Методы обработки естественного языка лежат в основе технологий распознавания речи, информационного поиска, средств проверки правописания, систем общения, и др. Ранее, на страницах «Открытых систем» уже затрагивались задачи обработки естественного языка [1] и проблемы построения эффективных систем решения таких задач [2]. Основные трудности в обработке естественного языка вызваны проблемой многозначности языка, выражающейся на всех стадиях его обработки: от фонетического до семантического уровня с точки зрения лингвистической теории «Смысл ⇔ Текст» [3]. Например, смысл предложения «Он видел их семью своими глазами.» зависит от того, является ли слово «семью» именем существительным («семья») или числительным («семь»). Таким образом, методы обработки естественного языка направлены на разрешение многозначности в различных её проявлениях.
Ранние системы обработки естественного языка, возникшие в конце 40-х гг. XX века, были ориентированы на решение задачи машинного перевода и использовали большое количество правил, составленных людьми вручную. Успешная демонстрация автоматического перевода шестидесяти предложений из научных статей по органической химии с русского языка на английский, проведённая компанией IBM в рамках Джорджтаунского эксперимента в 1954 г. [4], привела к существенному росту внимания к обработке естественного языка и увеличению объёма финансирования исследований и разработок в этой области. Организаторы эксперимента заявляли о решении проблемы машинного перевода в течение 3–5 лет, но проблема оказалась гораздо сложнее.
В конце 60-х годов XX века развитие компьютерной лингвистики серьёзно замедлилось из-за пессимистичного отчёта Наблюдательного комитета по автоматической обработке языка (англ. Automatic Language Processing Advisory Committee, сокр. ALPAC) в 1966 г. В отчёте заявлялось о недостаточной результативности исследований прошедших десяти лет, что привело к резкому снижению финансирования научно-исследовательских работ и стало одной из причин наступления т. н. «зимы искусственного интеллекта» [4]. Несмотря на возникший кризис завышенных ожиданий, исследования продолжались. В основе методов обработки естественного языка стали использоваться статистические модели, построенные при помощи машинного обучения на основе больших коллекций документов — корпусов текста. Статистический подход хорошо зарекомендовал себя. Большинство современных подходов к решению задач обработки естественного языка основаны на нём. Основатель распознавания речи, Фредерик Йелинек, в шутку заявлял: «Каждый раз, когда лингвист покидает коллектив, качество распознавания речи растёт.» (англ. Every time I fire a linguist, the performance of the speech recognizer goes up.)
Широкое распространение доступа в Интернет и взрывной рост популярности Всемирной паутины в 90-е гг. привели к необходимости каталогизации и систематизации информации, представленной на просторах Сети. Это привело к появлению специальных систем обработки естественного языка — поисковых машин, например, Google (1998 г.) и «Яндекс» (2000 г.). Поисковые машины осуществляют обработку и индексирование опубликованных в Интернете документов с целью предоставления наиболее релевантных некоторому запросу, сформулированного пользователем на естественном языке. Возник рынок контекстной рекламы, состоящей в показе тематических объявлений на страницах результатов поиска. Это повысило требования к качеству поиска и способности поисковой машины учесть информационную потребность пользователя. Несмотря на то, что качество поиска зависит не только от анализа текстов, но и от моделей поведения пользователя и структуры Всемирной паутины, инвестиции в область обработки естественного языка значительно увеличились.
Несмотря на высокую популярность статистических методов обработки естественного языка, существуют задачи, для решения которых требуются знания об окружающем мире [5]: информационный поиск, оценка семантической близости слов, разрешение лексической многозначности, и т. д. Для этого были созданы специальные языковые ресурсы — семантические сети, такие как РуТез~[5] и WordNet [6] для русского и английского языка, соответственно.
Семантические сети
В литературе слова «семантическая сеть» и «онтология» встречаются в достаточно близких контекстах, связанных с областью инженерии знаний или различными разделами искусственного интеллекта как научной дисциплины [7]. Несмотря на близость контекстов, эти слова обозначают два никак не связанных понятия: одно из слов характеризует способ представления знаний, а другое — способ хранения знаний. В частности, онтология задаёт предмет описания, в то время как семантическая сеть определяет способ его представления в виде графа. Основное внимание в данной статье посвящено семантическим сетям определения как способу представления знаний [7] и тезаурусам как к способу хранения знаний [5].
Среди известных работ по построению онтологий уровня стоит отметить онтологию Cyc [8], включающую в том числе онтологии нескольких предметных областей, онтологию SUMO [9], составленную из общих понятий, и др. Одной из первых работ, в которых фигурирует понятие, близкое к семантической сети, является работа и о семантической памяти (англ. semantic memory) [10]. Замечено, что люди воспринимают окружающий мир как иерархию понятий, связанных отношениями общего и частного. Например, если человек знает, что канарейка — это птица, то он сможет предположить, что у неё есть крылья. На заре инженерии знаний и обработки естественного языка под семантической сетью понимался размеченный ориентированный граф, вершины которого соответствуют некоторым сущностям (понятиям, событиям, характеристикам или значениям), а рёбра выражают отношения между этими сущностями [11]. Определения других авторов хорошо согласуются с этим определением [12]; некоторые авторы уточняют термин до семантических сетей определений [7]. В качестве рабочего определения в данной работе будет использовано следующее определение:
Семантическая сеть — это ориентированный граф, вершины которого — понятия, а рёбра — отношения между ними.
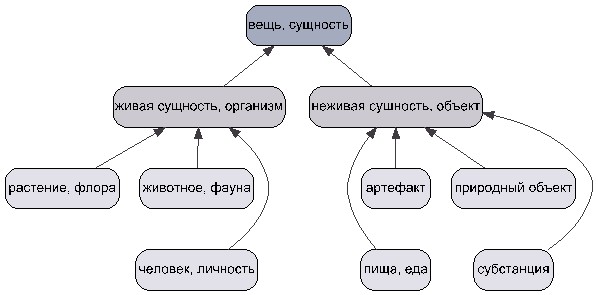
Рис. 1. Фрагмент верхнего уровня лексической онтологии WordNet
В области обработки естественного языка слово «понятие» также называют словом «синсет» (от англ. set of synonyms — «множество синонимов», сокр. synset) [6]. Как видно, семантические сети не накладывают ограничений на структуру знаний или конкретную предметную область до тех пор, пока эти знания возможно представить в виде ориентированного графа. Семантические сети являются одной из форм представления знаний. Существуют и другие формы представления знаний, такие как продукционные правила, фреймы и формальные логические модели [12]. Их рассмотрение выходит за рамки данной статьи. В задачах обработки естественного языка особенно популярна семантическая сеть WordNet [6], построенная на основе формализации человеческого восприятия окружающего мира. На рис. 1 представлен фрагмент верхнего уровня семантической сети WordNet [6]: понятия (синсеты) представлены в виде вершин, направленные рёбра показывают отношение от частного к общему (англ. is-a).
Основной сложностью при построении семантических сетей является большой объём работы, который необходимо выполнить для получения ресурса. Работа по созданию тезаурусов при помощи традиционного экспертного лексикографического подхода длится годы, прежде чем ресурс может применяться на практике [13]. Применение автоматизированных подходов снижает длительность процесса, но повышает требования к контролю качества [14].
Другой сложностью является необходимость формирования и следовании определённой концепции ресурса [15], отвечающую на вопросы об актуальности представленной лексики и наличия неологизмов и устаревших слов, подходах к выявлению синонимии и иных семантических отношений, степени внимания к уровням онтологии, наличия определений понятий и примеров их употребления, формате словарных статей, а также других особенностях целевого языка и используемых допущениях о его строении.
Достаточно важной проблемой является фактическая доступность ресурсов и особенности их лицензирования. С одной стороны, не все существующие ресурсы доступны для скачивания или использования. Например, создатели тезауруса RussNet [16] на сегодняшний день опубликовали только часть существующих данных. С другой стороны, существуют высококачественные ресурсы, распространяющиеся на условиях открытой лицензии, такие как РуТез [5] и BabelNet [14], но эта лицензия ограничивает их коммерческое применение. Другие ресурсы, такие как Russian WordNet [17], по всей видимости, утрачены безвозвратно. Это существенно затрудняет повторное использование данных для создания производных ресурсов.
Помимо задачи построения семантической сети с прикладной точки зрения необходима возможность оценки качества полученных данных, что также не является тривиальной задачей. Существует три различных подхода к оценке языковых ресурсов: сопоставление с «золотым стандартом», например, WordNet [6], привлечение эксперта или коллектива экспертов для оценки, или проведение «дорожки» (англ. shared task) по соревновательному сравнению ресурсов, например, RUSSE для русского языка [18].
Не критической, но достаточно ощутимой технической проблемой является отсутствие общепринятого стандарта электронного представления лексико-семантических ресурсов. Несмотря на существование стандартов Lexical Markup Framework [19] (LMF) и lemon [20], большое количество семантических сетей представляется в собственных форматах, несовместимых друг с другом.
Семантика и машинное обучение
Исторически, семантические сети нашли своё применение при решении различных задач компьютерной лингвистики, в том числе в задачах снятия многозначности, расширения поисковых запросов, формирование базы знаний в системах общения, рубрикации текстов, и других задачах [5].
В последние годы особенно заметна тенденция по разработке методов обучения без учителя для автоматического формирования понятий и связей между ними, см. обзоры [5][21][22]. Это вызвано двумя причинами: 1) популярностью и полнотой неструктурированных ресурсов, таких как Википедия и Викисловарь, построенных при помощи краудсорсинга, 2) существенным снижением стоимости высокопроизводительных вычислительных ресурсов, что позволяет разрабатывать методы машинного обучения с использованием больших объемов данных.
Семантические сети используются для определения наличия семантических отношений в паре слов: являются ли слова синонимами или же одно слово является частной формой другого слова? Решение подобной задачи сегодня достигается при помощи методов машинного обучения без учителя путём автоматического построения онтологии (англ. ontology learning, taxonomy induction). Примерами таких методов являются OntoGain [23], OntoLearn [24], TAXI [25], и др. Среди ранних подходов следует упомянуть шаблоны Хёрст (англ. Hearst patterns) формата «X является видом Y», до сих пор широко используемые в задачах приобретения знаний [26].
Появление в 2013 г. эффективных методов построения векторных представлений слов (англ. word embeddings) в пространстве низкой размерности [27][28] существенно изменило позицию семантических сетей при решении практических задач. Например, оказалось, что при использовании достаточно крупного корпуса текстов из нескольких десятков миллиардов слов, такие векторные представления показывают лучший результат в задаче определения семантической близости слов [18]. Важно отметить, что исследования последних лет показывают перспективность использования векторных представлений слов в задачах расширения онтологий и обнаружения семантических отношений путём как линейного преобразования векторных представлений гипонимов [29], так и классификации синтаксических отношений [30], однако эти результаты пока не интегрированы в существующие методы.
Задача анализа тональности, т. е. эмоциональной окраски текстов, также успешно решается при помощи машинного обучения, в частности при помощи свёрточных нейронных сетей [31] без использования дополнительных семантических ресурсов. Помимо надежд на машинное обучения, исследователи выражают большой оптимизм относительно применения краудсорсинга для решения этих проблем, возникающих при построении, разметке, расширении и использовании лексических ресурсов [32]. Например, большими перспективами обладает Викисловарь — достаточно качественный ресурс, пригодный для решения прикладных задач обработки естественного языка [13]. Известны работы по выявлению значений слов путём сочетания автоматических методов и краудсорсинга на основе выполнения большого количества микрозадач, такие как Turk Bootstrap Word Sense Inventory [33].
Что теперь?
Несмотря на успехи машинного обучения, высококачественные семантические сети являются по-прежнему критически важным языковым ресурсом, необходимым для решения задач, где требуется высокое качество данных, пусть даже достигаемое за счёт снижения их полноты.
Основная задача, в которой семантические сети до сих пор имеют неоспоримые преимущества — разрешение лексической многозначности (англ. word sense disambiguation), состоящая в определении конкретного значения каждого употреблённого слова в заданном тексте. В этом случае семантические сети, такие как WordNet [6] и BabelNet [14], используются в качестве инвентаря значений слов (англ. sense inventory) [34].
Другой задачей, где семантические сети критически важны, является задача оценки методов и систем автоматической обработки естественного языка и различных языковых ресурсов. В этом случае семантические сети используются в качестве «золотого стандарта» — общепринятого эталона, с которым выполняется сопоставление нового метода или ресурса по некоторой заданной системе измерений.
Ещё одной задачей, где нельзя обойтись без высококачественной семантической сети, является создание производных лексико-семантических ресурсов, таких как BabelNet. В этом случае семантическая сеть WordNet, построенная коллективом лексикографов-экспертов, используется в качестве базового (англ. pivot) ресурса для связывания с другими ресурсами.
Кроме того, интересным применением семантических сетей является объектный или семантический поиск, когда на странице результатов поиска представляются фактографическая информация об организации, событии или личности, которой был посвящён поисковый запрос, см. Google Knowledge Graph [35].
Применением семантических сетей, не имеющим непосредственного отношения к задачам обработки естественного языка, является разметка объектов на фотографиях и других изображениях. В проекте ImageNet [36] объекты на изображениях выделены граничной рамкой, каждая из которых ссылается на соответствующее понятие в онтологии WordNet [6]. Семантические сети с устоявшейся системой идентификаторов удобно использовать для связывания данных между собой.
[ВРЕЗКА]
Нужны ли семантические сети для обработки естественного языка?
Да, нужны для решения задач, в которых нельзя использовать машинное обучение: оценка методов обработки естественного языка, выделение инвентаря значений слов, связывание языковых ресурсов, семантический поиск.
[]
Таким образом, ответ на вопрос, сформулированный в заголовке данной статьи, положительный.
Благодарности
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 16-37-00354 мол_а и при финансовой поддержке РГНФ в рамках научного проекта № 16-04-12019 «Интеграция тезаурусов RussNet и YARN».
Литература
[1] Д. Ильвовский, Е. Черняк. Системы автоматической обработки текстов // Открытые системы. СУБД. — 2014. — № 1. — С. 51–53. URL: https://www. osp. ru/os/2014/01/13039687/ (дата обращения: 27.04.2017).
[2] К. Селезнев, А. Владимиров. Лингвистика и обработка текстов // Открытые системы. СУБД. — 2013. — № 4. — С. 46–49. URL: https://www. osp. ru/os/2013/04/13035562/ (дата обращения: 27.04.2017).
[3] . Опыт теории лингвистических моделей «Смысл ⇔ Текст». М.: Яз. рус. культуры, 1999. 368 стр.
[4] J. Hutchins. ALPAC: The (In)Famous Report // Readings in machine translation. — 2003. — Т 14. — С. 131–135.
[5] . Тезаурусы в задачах информационного поиска. М.: Изд-во МГУ, 2011. 512 стр.
[6] C. Fellbaum. WordNet: An Electronic Database. MIT Press, 1998. 449 стр.
[7] S. C. Shapiro. Encyclopedia of Artificial Intelligence, 2nd edition. New York, NY, USA: John Wiley & Sons, Inc., 1992. 1779 стр.
[8] D. B. Lenat, R. V. Guha. Building Large Knowledge-Based Systems: Representation and Inference in the Cyc Project. Boston, MA, USA: Addison-Wesley Longman Publishing Co., Inc., 1990. 391 стр.
[9] Niles I., Pease A. Towards a Standard Upper Ontology // Proceedings of the International Conference on Formal Ontology in Information Systems - Volume 2001. — С. 2–9. — ACM, 2001. DOI: 10.1145/505168.505170.
[10] A. M. Collins, M. R. Quillian. Retrieval time from semantic memory // Journal of Verbal Learning and Verbal Behavior. — 1969. — Т. 13, № 2. — С. 240–247. DOI: 10.1016/S0022-5371(69)80069-1.
[11] Roussopoulos N., Mylopoulos J. Using Semantic Networks for Data Base Management // Proceedings of the 1st International Conference on Very Large Data Bases. — С. 144–172. — ACM, 1975. DOI: 10.1145/1282480.1282490.
[12] , . Базы знаний интеллектуальных систем. СПб: Питер, 2000. 384 стр.
[13] и др. Современное состояние электронных тезаурусов русского языка: качество, полнота и доступность // Программная инженерия. — 2015. — № 6. — С. 34–40.
[14] R. Navigli, S. P. Ponzetto. BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network // Artificial Intelligence. — 2012. — Т. 193. — С. 217–250. DOI: 10.1016/j. artint.2012.07.001.
[15] Braslavski P. et al. YARN: Spinning-in-Progress // Proceedings of the 8th Global WordNet Conference. — С. 58–65. — Global WordNet Association, 2016.
[16] , , Синопальникова тезаурус русского языка типа WordNet // Труды Международного семинара Диалог'2003 по компьютерной лингвистике и её приложениям. — С. 43–50. — Наука, 2003. URL: http://www. dialog-21.ru/media/2606/azarova. pdf (дата обращения: 27.04.2017).
[17] Balkova V., Sukhonogov A., Yablonsky S. Russian WordNet. From UML-notation to Internet/Intranet Database Implementation // Proceedings of the Second International WordNet Conference—GWC 2004. — С. 31–38. — Masaryk University Brno, 2004.
[18] Panchenko A. et al. RUSSE: The First Workshop on Russian Semantic Similarity // Computational Linguistics and Intellectual Technologies: papers from the Annual conference “Dialogue”: Volume 2 of 2. Papers from special sessions. — С. 89–105. — РГГУ, 2015. URL: http://www. dialog-21.ru/digests/dialog2015/materials/pdf/PanchenkoAetal. pdf (дата обращения: 21.04.2017).
[19] G. Francopoulo. LMF: Lexical Markup Framework. London, UK: Wiley-ISTE, 2013. 288 стр.
[20] McCrae J., Spohr D., Cimiano P. Linking Lexical Resources and Ontologies on the Semantic Web with Lemon // The Semantic Web: Research and Applications: 8th Extended Semantic Web Conference, ESWC 2011, Heraklion, Crete, Greece, May 29-June 2, 2011, Proceedings, Part I. — С. 245–259. — Springer Berlin Heidelberg, 2011. DOI: 10.1007/978-3-642-21034-1_17.
[21] Navigli R. A Quick Tour of Word Sense Disambiguation, Induction and Related Approaches // Proceedings of the 38th International Conference on Current Trends in Theory and Practice of Computer Science. — С. 115–129. — Springer-Verlag, 2012. DOI: 10.1007/978-3-642-27660-6_10.
[22] O. Medelyan et al. Automatic construction of lexicons, taxonomies, ontologies, and other knowledge structures // Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery. — 2013. — Т. 3, № 4. — С. 257–279. DOI: 10.1002/widm.1097.
[24] P. Velardi, S. Faralli, R. Navigli. OntoLearn Reloaded: A Graph-Based Algorithm for Taxonomy Induction // Computational Linguistics. — Т. 39, № 3. — С. 665–707. DOI: 10.1162/COLI_a_00146.
[23] Drymonas E., Zervanou K., Petrakis E. G. M. Unsupervised Ontology Acquisition from Plain Texts: The OntoGain System // Proceedings of the Natural Language Processing and Information Systems, and 15th International Conference on Applications of Natural Language to Information Systems. — С. 277–287. — Springer-Verlag, 2010. DOI: 10.1007/978-3-642-13881-2_29.
[25] Panchenko A. et al. TAXI at SemEval-2016 Task 13: a Taxonomy Induction Method based on Lexico-Syntactic Patterns, Substrings and Focused Crawling // Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016). — С. 1320–1327. — Association for Computational Linguistics, 2016. URL: https://aclweb. org/anthology/S16-1206 (дата обращения: 27.04.2017).
[26] Hearst M. A. Automatic Acquisition of Hyponyms from Large Text Corpora // Proceedings of the 14th Conference on Computational Linguistics - Volume 2. — С. 539–545. — Association for Computational Linguistics, 1992. DOI: 10.3115/992133.992154.
[27] Mikolov T. et al. Distributed Representations of Words and Phrases and their Compositionality // Advances in Neural Information Processing Systems 26. — С. 3111–3119. — Curran Associates, Inc., 2013. URL: https://papers. nips. cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality (дата обращения: 28.04.2017).
[28] Pennington J., Socher R., Manning C. D. GloVe: Global Vectors for Word Representation // Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. — С. 1532–1543. — Association for Computational Linguistics, 2014. URL: https://aclweb. org/anthology/D14-1162 (дата обращения: 27.04.2017).
[29] Fu R. et al. Learning Semantic Hierarchies via Word Embeddings // Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). — С. 1199–1209. — Association for Computational Linguistics, 2014. URL: https://aclweb. org/anthology/P/P14/P14-1113.pdf (дата обращения: 28.04.2017).
[30] Shwartz V., Goldberg Y., Dagan I. Improving Hypernymy Detection with an Integrated Path-based and Distributional Method // Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). — С. 2389–2398. — Association for Computational Linguistics, 2016. URL: https://aclweb. org/anthology/P/P16/P16-1226.pdf (дата обращения: 25.04.2017).
[31] dos Santos C., Gatti M. Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts // Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers. — С. 69–78. — Association for Computational Linguistics, 2014. URL: https://aclweb. org/anthology/C/C14/C14-1008.pdf (дата обращения: 28.04.2017).
[32] I. Gurevych, J. Kim. The People’s Web Meets NLP. Springer Berlin Heidelberg, 2013. 378 стр.
[33] C. Biemann. Creating a system for lexical substitutions from scratch using crowdsourcing // Language Resources and Evaluation. — Т. 47, № 1. — С. 97–122. DOI: 10.1007/s10579-012-9180-5.
[34] K. Allan. Concise Encyclopedia of Semantics. Oxford, UK: Elsevier Science, 2009. 1104 стр.
[35] A. Singhal. Introducing the Knowledge Graph: things, not strings. — 2012. URL: https://googleblog. blogspot. ru/2012/05/introducing-knowledge-graph-things-not. html (дата обращения: 24.04.2017).
[36] Deng J. et al. ImageNet: A Large-Scale Hierarchical Image Database // Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. — С. 248–255. — IEEE, 2009. DOI: 10.1109/CVPR.2009.5206848.
https://www.osp.ru/os/about/
