


Л. Заде, формулируя это главное свойство нечетких множеств, базировался на трудах предшественников. В начале 1920-х годов польский математик Лукашевич трудился над принципами многозначной математической логики, в которой значениями предикатов могли быть не только «истина» или «ложь». В 1937 году еще один американский ученый М. Блэк впервые применил многозначную логику Лукашевича к спискам как множествам объектов и назвал такие множества неопределенными.
Прежде чем нечеткий подход к моделированию сложных систем получил признание во всем мире, с момента зарождения теории нечетких множеств прошло не одно десятилетие.
Нечеткая логика как научное направление развивалась непросто, не избежала она и обвинений в лженаучности. Даже в 1989 году, когда примеры успешного применения нечеткой логики в обороне, промышленности и бизнесе исчислялись десятками, Национальное научное общество США обсуждало вопрос об исключении материалов по нечетким множествам из институтских учебников.
Первый период развития нечетких систем (конец 60-х – начало 70-х гг.) характеризуется развитием теоретического аппарата нечетких множеств. В 1970 году Беллман совместно с Заде разработали теорию принятия решений в нечетких условиях.
В 70-80 годы (второй период) появляются первые практические результаты в области нечеткого управления сложными техническими системами (парогенератор с нечетким управлением). И. Мамдани в 1975 году спроектировал первый функционирующий на основе алгебры Заде контроллер, управляющий паровой турбиной. Одновременно стало уделяться внимание вопросам создания экспертных систем, построенных на нечеткой логике, разработке нечетких контроллеров. Нечеткие экспертные системы для поддержки принятия решений нашли широкое применение в медицине и экономике.
Наконец, в третьем периоде, который длится с конца 80-х годов и продолжается в настоящее время, появляются пакеты программ для построения нечетких экспертных систем, а области применения нечеткой логики заметно расширяются. Она применяется в автомобильной, аэрокосмической и транспортной промышленности, в области изделий бытовой техники, в сфере финансов, анализа и принятия управленческих решений и многих других. Кроме того, немалую роль в развитии нечеткой логики сыграло доказательство знаменитой теоремы FAT (Fuzzy Approximation Theorem)
Б. Коско, в которой утверждалось, что любую математическую систему можно аппроксимировать системой на основе нечеткой логики.
Одним из самых впечатляющих результатов стало создание управляющего микропроцессора на основе нечеткой логики, способного автоматически решать известную задачу «о собаке, догоняющей кота». В
1990 году Комитет по контролю экспорта США внес нечеткую логику в список критически важных оборонных технологий, не подлежащих экспорту потенциальному противнику.
В бизнесе и финансах нечеткая логика получила признание после того, как в 1988 году экспертная система на основе нечетких правил для прогнозирования финансовых индикаторов единственная предсказала биржевой крах. И количество успешных фаззи-применений в настоящее время исчисляется тысячами.
В Японии это направление переживает настоящий бум. Здесь функционирует специально созданная организация Laboratory for International Fuzzy Engineering Research. Программой этой организации является создание более близких человеку вычислительных устройств.
Информационные системы, базирующиеся на нечетких множествах и нечеткой логике, называют нечеткими системами.
Достоинства нечетких систем:
Ÿ функционирование в условиях неопределенности;
Ÿ оперирование качественными и количественными данными;
Ÿ использование экспертных знаний в управлении;
Ÿ построение моделей приближенных рассуждений человека;
Ÿ устойчивость при действии на систему всевозможных возмущений.
Недостатками нечетких систем являются:
Ÿ отсутствие стандартной методики конструирования нечетких систем;
Ÿ невозможность математического анализа нечетких систем существующими методами;
Ÿ применение нечеткого подхода по сравнению с вероятностным не приводит к повышению точности вычислений.
Теория нечетких множеств
Главное отличие теории нечетких множеств от классической теории четких множеств состоит в том, что если для четких множеств результатом вычисления характеристической функции могут быть только два значения – 0 или 1, то для нечетких множеств это количество бесконечно, но ограничено диапазоном от нуля до единицы.
Нечеткое множество
Пусть U – так называемое универсальное множество, из элементов которого образованы все остальные множества, рассматриваемые в данном классе задач, например множество всех целых чисел, множество всех гладких функций и т. д. Характеристическая функция множества ![]() – это функция
– это функция ![]() , значения которой указывают, является ли
, значения которой указывают, является ли ![]() элементом множества A:
элементом множества A:
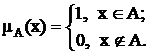
В теории нечетких множеств характеристическая функция называется функцией принадлежности, а ее значение ![]() – степенью принадлежности элемента x нечеткому множеству A.
– степенью принадлежности элемента x нечеткому множеству A.
Более строго: нечетким множеством A называется совокупность пар
![]()
где ![]() – функция принадлежности, то есть
– функция принадлежности, то есть ![]()
Пусть, например, U ={a, b, c, d, e}, 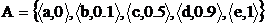 . Тогда элемент a не принадлежит множеству A, элемент b принадлежит ему в малой степени, элемент c более или менее принадлежит, элемент d принадлежит в значительной степени, e является элементом множества A.
. Тогда элемент a не принадлежит множеству A, элемент b принадлежит ему в малой степени, элемент c более или менее принадлежит, элемент d принадлежит в значительной степени, e является элементом множества A.
Пример. Пусть универсум U есть множество действительных чисел. Нечеткое множество A, обозначающее множество чисел, близких к 10, можно задать следующей функцией принадлежности (рис. 19):
![]() ,
,
где ![]()
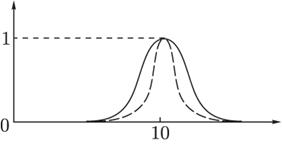
Рис. 19. Функция принадлежности ![]()
Показатель степени m выбирается в зависимости от степени близости к 10. Например, для описания множества чисел, очень близких к 10, можно положить m = 4, для множества чисел, не очень далеких от 10, m = 1.
Носителем нечеткого множества A называется четкое множество ![]() таких точек в U, для которых величина
таких точек в U, для которых величина ![]() положительна, то есть
положительна, то есть ![]()
Ядром нечеткого множества A называется четкое множество ![]() таких точек в U, для которых величина
таких точек в U, для которых величина ![]() = 1.
= 1.
Множеством уровня ![]() (
(![]() -срезом) нечеткого множества A называется четкое подмножество универсального множества U, определяемое по формуле
-срезом) нечеткого множества A называется четкое подмножество универсального множества U, определяемое по формуле 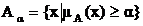 , где
, где ![]()
Функцию принадлежности называют нормальной, если ядро нечеткого множества содержит хотя бы один элемент.
Операции над нечеткими множествами
Для нечетких множеств, как и для обычных, определены основные операции: объединение, пересечение и инверсия/дополнение.
Для определения пересечения и объединения нечетких множеств наибольшей популярностью пользуются следующие три группы операций:
Максиминные |
|
Алгебраические |
|
Ограниченные |
|
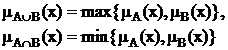
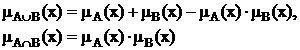
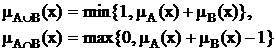
Дополнение нечеткого множества во всех трех случаях определяется одинаково:
![]()
Пример. Пусть A – нечеткое множество «от 5 до 8» и B – нечеткое множество «около 4», заданные своими функциями принадлежности (рис. 20).
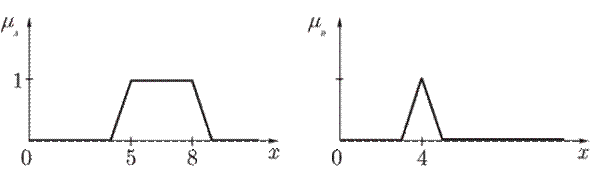
Рис. 20. Функции принадлежности нечетких множеств А и B
Тогда, используя максиминные операции, мы получим следующие множества, изображенные на рис. 21.

Рис. 21. Функции принадлежности нечетких множеств, полученных из А и B
При максиминном и алгебраическом определении операций не будут выполняться законы противоречия и исключения третьего:
![]()
а в случае ограниченных операций не будут выполняться свойства идемпотентности и дистрибутивности:
![]() ,
,
![]()
Можно показать, что при любом построении операций объединения и пересечения в теории нечетких множеств приходится отбрасывать либо законы противоречия и исключения третьего, либо законы идемпотентности и дистрибутивности.
Нечеткая логика
Понятие нечеткой и лингвистической переменных используется при описании объектов и явлений с помощью нечетких множеств.
Нечеткая переменная характеризуется тройкой <a, X, A>, где a – наименование переменной, X – универсальное множество (область определения a), A – нечеткое множество на X, описывающее ограничения (то есть m A(x)) на значения нечеткой переменной a.
Лингвистической переменной называется набор <b, T, X, G, M>, где b – наименование лингвистической переменной, Т – множество ее значений (терм-множество), представляющих собой наименования нечетких переменных, областью определения каждой из которых является множество X (множество T называется базовым терм-множеством лингвистической переменной), G – синтаксическая процедура, позволяющая оперировать элементами терм-множества T, в частности генерировать новые термы (значения), М – семантическая процедура, позволяющая превратить каждое новое значение лингвистической переменной, образуемое процедурой G, в нечеткую переменную, то есть сформировать соответствующее нечеткое множество.
Лингвистическую переменную можно определить как переменную, значениями которой являются не числа, а слова или предложения естественного (или формального) языка. Например, лингвистическая переменная «возраст» может принимать следующие значения: «очень молодой», «молодой», «среднего возраста», «старый», «очень старый» и др. Ясно, что переменная «возраст» будет обычной переменной, если ее значения – точные числа; лингвистической она становится, будучи использованной в нечетких рассуждениях человека.
Каждому значению лингвистической переменной соответствует определенное нечеткое множество со своей функцией принадлежности. Так, лингвистическому значению «молодой» может соответствовать функция принадлежности, изображенная на рис. 22.
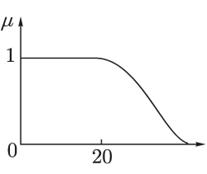
Рис. 22. Функция принадлежности значения «молодой»
лингвистической переменной «возраст»
Пример. Пусть эксперт определяет толщину выпускаемого изделия с помощью понятий «малая толщина», «средняя толщина» и «большая толщина», при этом минимальная толщина равна 10 мм, а максимальная – 80 мм (рис. 23).
Формализация такого описания может быть проведена с помощью следующей лингвистической переменной <b, T, X, G, M>, где
b – толщина изделия;
T – {«малая толщина», «средняя толщина», «большая толщина»};
X = [10, 80];
G – процедура образования новых термов с помощью связок и, или и модификаторов типа очень, не, слегка и др. Например: «малая или средняя толщина» (рис. 24), «очень малая толщина» и др.;
М – процедура задания на X = [10, 80] нечетких подмножеств
А1 = «малая толщина», А2 = «средняя толщина», А3 = «большая толщина», а также нечетких множеств для термов из G(T) в соответствии с правилами трансляции нечетких связок и модификаторов и, или, не, очень, слегка и др.
Наряду с рассмотренными выше базовыми значениями лингвистической переменной «толщина» (Т = {«малая толщина», «средняя толщина», «большая толщина»}) возможны значения, зависящие от области определения Х. В данном случае значения лингвистической переменной «толщина изделия» могут быть определены как «около 20 мм», «около 50 мм», «около 70 мм», то есть в виде нечетких чисел.
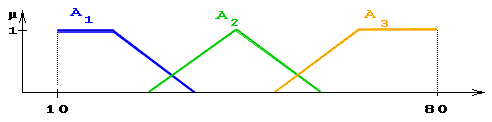
Рис. 23. Функции принадлежности нечетких множеств:
«малая толщина» = А1, «средняя толщина» = А2, «большая толщина» = А3
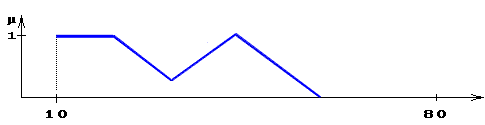
Рис. 24. Функция принадлежности
нечеткого множества «малая или средняя толщина» = А1ÈА1
Нечеткими высказываниями будем называть высказывания следующего вида:
1. Высказывание <b есть b'>, где b – наименование лингвистической переменной, b' – ее значение, которому соответствует нечеткое множество на универсальном множестве Х.
Например, высказывание <давление большое> предполагает, что лингвистической переменной «давление» придается значение «большое», для которого на универсальном множестве Х переменной «давление» определено соответствующее данному значению «большое» нечеткое множество.
2. Высказывание <b есть mb'>, где m – модификатор, которому соответствуют слова «очень», «более или менее», «много больше» и др.
Например: <давление очень большое>, <скорость много больше средней> и др.
3. Составные высказывания, образованные из высказываний видов 1 и 2 и союзов и; или; если… то...; если… то… иначе...
Основным правилом вывода в традиционной логике является правило modus ponens, согласно которому мы судим об истинности высказывания B по истинности высказываний A и ![]()
Например, если A – высказывание <Иван в больнице>, B – высказывание <Иван болен>, то если истинны высказывания <Иван в больнице> и <Если Иван в больнице, то он болен>, то истинно и высказывание <Иван болен>.
Во многих привычных рассуждениях, однако, правило modus ponens используется не в точной, а в приближенной форме. Так, обычно мы знаем, что A истинно и что ![]() , где
, где ![]() есть в некотором смысле приближение A. Тогда из
есть в некотором смысле приближение A. Тогда из 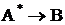 мы можем сделать вывод о том, что B приближенно истинно.
мы можем сделать вывод о том, что B приближенно истинно.
Нечеткая импликация выражается в следующем виде:
![]() и
и ![]()
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме если… то… и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
Ÿ существует хотя бы одно правило для каждого лингвистического терма выходной переменной;
Ÿ для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Для реализации логического вывода необходимо выполнить следующее:
1. Сопоставить факты с каждым из правил и определить степень соответствия, назначив текущую силой правил.
2. Для каждого правила, сила которого больше заданного порога, вычислить достоверность левой части.
3. Для каждого правила с помощью оператора импликации вычислить достоверность правой части.
4. Для многих результатов, полученных по различным правилам, выбрать одно (усредненное).
Пример. Пусть есть некоторая система, например реактор, описываемая тремя параметрами: температура, давление и расход рабочего вещества. Все показатели измеримы, и множество возможных значений известно. Также из опыта работы с системой известны некоторые правила, связывающие значения этих параметров. Предположим, что сломался датчик, измеряющий значение одного из параметров системы, но знать его показания необходимо хотя бы приблизительно. Тогда встает задача об отыскании этого неизвестного значения (пусть это будет давление) при известных показателях двух других параметров (температуры и расхода) и связи этих величин в виде следующих правил:
· если Температура низкая и Расход малый, то Давление низкое;
· если Температура средняя, то Давление среднее;
· если Температура высокая или Расход большой, то Давление высокое.
Температура, Давление и Расход – лингвистические переменные.
Температура. Универсум (множество возможных значений) – отрезок [0, 150]. Начальное множество термов {Высокая, Средняя, Низкая}. Функции принадлежности термов имеют следующий вид (рис. 25):
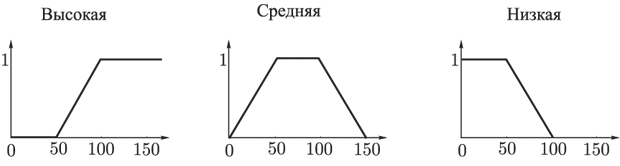
Рис. 25. Функции принадлежности термов
лингвистической переменной Температура
Давление. Универсум – отрезок [0, 100]. Начальное множество термов {Высокое, Среднее, Низкое}. Функции принадлежности термов имеют следующий вид (рис. 26):
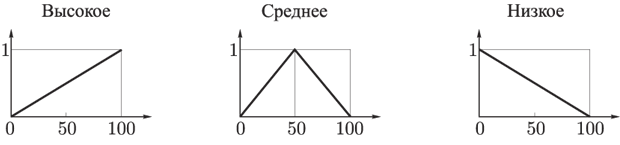
Рис. 26. Функции принадлежности термов лингвистической переменной Давление
Расход. Универсум – отрезок [0, 8]. Начальное множество термов {Большой, Средний, Малый}. Функции принадлежности термов имеют следующий вид (рис. 27):
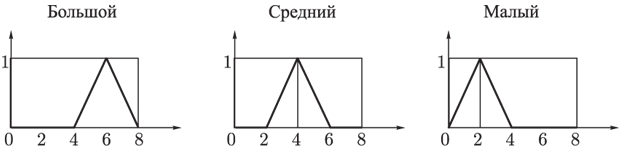
Рис. 27. Функции принадлежности термов лингвистической переменной Расход
Пусть известны значения: Температура – 85 и Расход – 3.5. Произведем расчет значения давления.
Этап фаззификации (переход от заданных четких значений к степеням уверенности). По заданным значениям входных параметров найдем степени уверенности простейших утверждений:
· Температура Высокая – 0.7; · Температура Средняя – 1; · Температура Низкая – 0.3; | · Расход Большой – 0; · Расход Средний – 0.75; · Расход Малый – 0.25. |
Затем вычислим степени уверенности посылок правил:
· Температура Низкая и Расход Малый: min (Темп. Низкая, Расход Малый)= min (0.3; 0.25)=0.25;
· Температура Средняя: 1;
· Температура Высокая или Расход Большой: max (Темп. Высокая, Расход Большой)= max (0.7; 0)=0.7.
Каждое из правил представляет собой нечеткую импликацию. Степень уверенности посылки мы вычислили, а степень уверенности заключения задается функцией принадлежности соответствующего терма. Поэтому, используя один из способов построения нечеткой импликации, мы получим новую нечеткую переменную, соответствующую степени уверенности в значении выходных данных при применении к заданным входным соответствующего правила. Используя определение нечеткой импликации как минимума левой и правой частей (определение Мамдани), имеем (рис. 28):
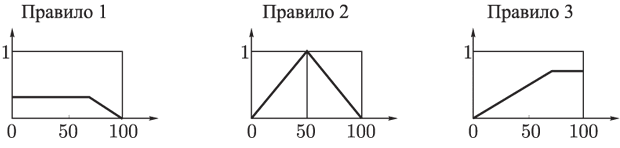 Рис. 28. Результат этапа фаззификации
Рис. 28. Результат этапа фаззификации
Этап аккумуляции (объединение результатов применения всех правил). Один из основных способов аккумуляции – построение максимума полученных функций принадлежности (объединение функций принадлежности, полученных на этапе фаззификации).
Полученную функцию принадлежности уже можно считать результатом. Это новый терм выходной переменной Давление. Его функция принадлежности говорит о степени уверенности в значении давления при заданных значениях входных параметров и использовании правил, определяющих соотношение входных и выходных переменных. Но обычно все-таки необходимо какое-то конкретное числовое значение (рис. 29).
Этап дефаззификации (получение конкретного значения из универса по заданной на нем функции принадлежности). Существует множество методов дефаззификации, но в этом случае достаточно метода первого максимума. Применяя его к полученной функции принадлежности, получаем, что значение давления – 50. Таким образом, если мы знаем, что температура равна 85, а расход рабочего вещества – 3.5, то можем сделать вывод, что давление в реакторе равно примерно 50.
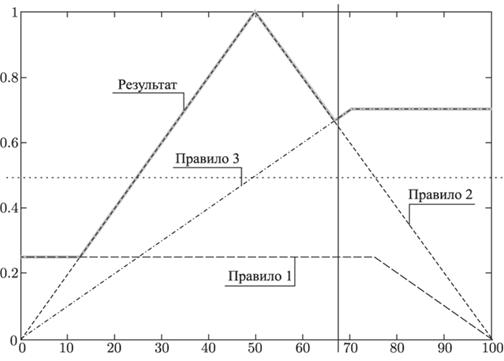
Рис. 29. Результат этапа аккумуляции
Тест по теме «Нечеткие множества и нечеткая логика»
1. Кто заложил основы теории нечетких множеств?
a) И. Мамдани
b) М. Блэк
c) Л. Заде
d) Б. Коско
e) нет правильного ответа
2. Какие значения может принимать функция принадлежности?
a) [0, ∞]
b) [-∞, +∞]
c) [0, 1]
d) нет правильного ответа
3. Множество точек, для которых значение функция принадлежности равно 1, называется:
a) носителем
b) ядром
c) ![]() -срезом
-срезом
d) нет правильного ответа
4. Какая формула определяет объединение нечетких множеств А и В?
a) ![]()
b) ![]()
c) ![]()
d) ![]()
e) нет правильного ответа
5. В случае ограниченных операций не будут выполняться:
a) ![]()
b) ![]()
c) ![]()
d)  нет правильного ответа
нет правильного ответа
6. На рисунке показаны графики функции принадлежности нечетких множеств ![]() – «Высокий рост» и
– «Высокий рост» и ![]() – «Средний рост». Определить степень принадлежности человека ростом 180 см к первому (
– «Средний рост». Определить степень принадлежности человека ростом 180 см к первому (![]() /180) и второму (
/180) и второму (![]() /180) множествам:
/180) множествам:
a) ![]() /180 =
/180 =![]() /180 =min {0.75; 1}
/180 =min {0.75; 1}
b) ![]() /180 =
/180 =![]() /180 =max {0.75; 1}
/180 =max {0.75; 1}
c) ![]() /180 =
/180 =![]() /180 =0.5*(
/180 =0.5*(![]() /180 +
/180 +![]() /180)=0.875
/180)=0.875
d) ![]() /180 =0.75,
/180 =0.75, ![]() /180=1
/180=1
e) нет правильного ответа
7. Пусть ![]() (u),
(u), ![]() (u) – функции принадлежности нечетких множества А и В на универсальном множестве U. Пусть также С – нечеткое множество с функцией принадлежности mС(u), которое является объединением А и В. Определить значение принадлежности uÎU нечеткому множеству С, если mА(u)=0.5 и mВ(u) = 0:
(u) – функции принадлежности нечетких множества А и В на универсальном множестве U. Пусть также С – нечеткое множество с функцией принадлежности mС(u), которое является объединением А и В. Определить значение принадлежности uÎU нечеткому множеству С, если mА(u)=0.5 и mВ(u) = 0:
а) mС(u) = max{mВ(u), mА(u)} = 0.5
b) mС(u) = min{mВ(u), mА(u)} = 0
c) mС(u) = 1 - min{ mВ(u), mА(u)} = 1
d) нет правильного ответа
8. Пусть ![]() (u),
(u), ![]() (u) – функции принадлежности нечетких множества А и В на универсальном множестве U. Пусть также С – нечеткое множество с функцией принадлежности mС(u), которое является пересечение А и В. Определить значение принадлежности uÎU нечеткому множеству С, если mА(u)=0.5 и mВ(u) = 0:
(u) – функции принадлежности нечетких множества А и В на универсальном множестве U. Пусть также С – нечеткое множество с функцией принадлежности mС(u), которое является пересечение А и В. Определить значение принадлежности uÎU нечеткому множеству С, если mА(u)=0.5 и mВ(u) = 0:
a) mС(u) = max{mВ(u), mА(u)} = 0.5
b) mС(u) = min{mВ(u), mА(u)} = 0
c) mС(u) = 1- max{mВ(u), mА(u)} = 0.5
d) mС(u) = 1- min{mВ(u), mА(u)} = 1
e) нет правильного ответа
Литература по теме «Нечеткие множества
и нечеткая логика»
1. Круглов, логика и искусственные нейронные сети /
, , . – М. : ФИЗМАТЛИТ, 2001. – 224 с.
2. Паклин, Н. Нечеткая логика – математические основы [Электронный ресурс] / Н. Паклин. – Режим доступа:
http://www. *****/library/analysis/fuzzylogic/math/
3. Пивкин, множества в системах управления : учеб. пособие [Электронный ресурс] / , , ; под ред. проф. . – Режим доступа: http://www. *****/best/Nechetkie-mnozhestva-v-sistemakh-upravleniya-ref41397.html
4. Прикладные нечеткие системы : пер. с япон. / К. Асаи и др. ; под ред. Т. Тэрано, К. Асаи, М. Сугэно. – М. : Мир, 1993. – 368 с.
5. Штовба, в теорию нечетких множеств и нечеткую логику [Электронный ресурс] / . – Режим доступа: http://matlab. *****/fuzzylogic/book1/index. php
Часть 3. ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
§1. Экспертные системы
На начальных этапах развития искусственный интеллект подвергался жесткой критике, и одним из доводов был тот, что практической пользы от него нет, он занимается игрушками. Экспертные системы одними из первых доказали практическую пользу этого научного направления, принося в начале 80-х годов ХХ века коммерческую прибыль своим создателям.
Термин «системы, основанные на знаниях» (knowledge-based systems) появился в 1976 году одновременно с первыми системами, аккумулирующими опыт и знания экспертов.
Экспертные системы – это прикладные системы искусственного интеллекта, в которых база знаний представляет собой формализованные эмпирические знания высококвалифицированных специалистов (экспертов) в какой-либо узкой предметной области, они аккумулируют эти знания и тиражируют их для консультации менее квалифицированных специалистов.
В 1965 году Э. Фейгенбаум (бывший студент Герберта Саймона),
Б. Бьюкенен (философ по образованию) и Д. Ледерберг (лауреат Нобелевской премии в области генетики) начали работы над первой экспертной системой DENDRAL. В 1969 году В. Мартином и Д. Мозесом была создана математическая экспертная система MACSYMA. Первая экспертная система для медицинской диагностики была создана в 1973 году Э. Шортлиффом и называлась MYCIN, она повлекла за собой разработку первого командного интерпретатора EMYCIN (В. Милле, Шортлифф и Бьюкенен). В 1976 году Дуда и Харт начали работу над экспертной системой PROSPECTOR, предназначенной для разведки полезных ископаемых, в 1984 году система точно предсказала существование месторождения молибдена, оцененного в многомиллионную сумму.
Эти экспертные системы, разработанные в 60-70-х годах стали классическими. По происхождению, предметным областям и по преемственности применяемых идей, методов и инструментальных программных средств их можно разделить на несколько семейств.
1. META-DENDRAL. Система DENDRAL позволяет определить наиболее вероятную структуру химического соединения по экспериментальным данным (масс-спектрографии, данным ядерного магнитного резонанса и др.). Meta-DENDRAL автоматизирует процесс приобретения знаний для DENDRAL. Она генерирует правила построения фрагментов химических структур.
2. MYCIN-EMYCIN-TEIREIAS-PUFF-NEOMYCIN. Это семейство медицинских ЭС и сервисных программных средств для их построения.
3. PROSPECTOR-KAS. Система PROSPECTOR предназначена для поиска (предсказания) месторождений на основе геологических анализов. KAS – система приобретения знаний для PROSPECTOR.
4. CASNET-EXPERT. Система CASNET – медицинская ЭС для диагностики выдачи рекомендаций по лечению глазных заболеваний. На ее основе разработан язык инженерии знаний EXPERT, с помощью которого создан ряд других медицинских диагностических систем.
5. HEARSAY-HEARSAY-2-HEARSAY-3-AGE. Первые две системы этого ряда являются развитием интеллектуальной системы распознавания слитной человеческой речи, слова которой берутся из заданного словаря. Эти системы отличаются оригинальной структурой, основанной на использовании доски объявлений – глобальной базы данных, содержащей текущие результаты работы системы. В дальнейшем на основе этих систем были созданы инструментальные системы HEARSAY-3 и AGE (Attempt to Generalize – попытка общения) для построения экспертных систем.
6. Системы AM (Artifical Mathematician – искусственный математик) и EURISCO были разработаны в Станфордском университете доктором Дугласом Ленатом для исследовательских и учебных целей. В систему AM первоначально было заложено около 100 правил вывода и более
200 эвристических алгоритмов обучения, позволяющих строить произвольные математические теории и представления. EURISCO – это развитие системы AM, с ее помощью в военно-стратегической игре, проводимой ВМФ США, была разработана стратегия, содержащая ряд оригинальных тактических ходов.
Кроме разработки самих экспертных систем исследователи занялись созданием инструментального средства для экспертных систем: в 1983 году компания IntelliCorp создала KEE, а в 1985 году агентство NASA выпустило первую версию CLIPS.
Экспертные системы быстро завоевали позиции на информационном рынке и получили широкое распространение. Уже в 1987 году опрос пользователей, проведенный журналом Intelligent Technologies (США), показал, что примерно:
Ÿ 25% пользователей используют ЭС;
Ÿ 25% собираются приобрести ЭС в ближайшие 2-3 года;
Ÿ 50% предпочитают провести исследование об эффективности их использования.
В России в исследования и разработку ЭС большой вклад внесли работы (основателя Российской ассоциации искусственного интеллекта и его первого президента), , и многих других.
Экспертные системы 60-90-х годов являются первым поколением экспертных систем, для них характерно:
1) знаниями системы являются только знания эксперта, накопление знаний не предусматривается;
2) методы представления знаний позволяют описывать лишь статические предметные области;
3) модели представления знаний ориентированы на простые предметные области.
Развиваясь, экспертные системы вышли за эти рамки. Принципы представления знаний в экспертных системах второго поколения изменились:
1) используются не поверхностные знания, а более глубинные;
2) для представления знаний привлекаются средства и методы других направлений искусственного интеллекта, например нейронных сетей;
3) системы имеют динамические базы знаний.
Появление Интернета не могло не повлиять на развитие экспертных систем. Возможность получать знания через сеть и извлекать знания из сети не могла не быть использована разработчиками. Поэтому сейчас развиваются распределенные и web-ориентированные экспертные системы.
Сейчас количество экспертных систем исчисляется тысячами и десятками тысяч. В развитых зарубежных странах сотни фирм занимаются их разработкой и внедрением в различные сферы жизни.
В качестве современных ЭС можно назвать быстродействующую систему OMEGAMON (фирма Candle, с 2004 года – IBM) для отслеживания состояния корпоративной информационной сети и G2 (фирма Gensym) – коммерческую экспертную систему для работы с динамическими объектами.
Экспертные системы используют в тех случаях, когда недостаточно экспертов, в опасных (вредных) для них условиях, в процессе обучения. Экспертные системы решают задачи, для которых отсутствуют четкие алгоритмы решения.
Модель экспертных систем
Экспертные системы работают в диалоговом режиме (отвечают на поставленные пользователем вопросы), при этом они должны уметь объяснять, откуда получено то или иное решение. Любая экспертная система содержит как минимум пять компонентов или подсистем (рис. 30).


Рис. 30. Базовая структура экспертной системы
Пользователь экспертной системы – специалист предметной области, для которого предназначена система. Обычно его квалификация недостаточно высока, и поэтому он нуждается в помощи и информационной поддержке своей деятельности.
Инженер по знаниям – специалист в области искусственного интеллекта, работающий с экспертами и формирующий базу знаний. Синонимы: когнитолог, инженер-интерпретатор, аналитик.
Интерфейс пользователя – комплекс программ, реализующих диалог пользователя с ЭС как на стадии ввода информации, так и при получении результатов.
База знаний – ядро экспертной системы, совокупность знаний предметной области, записанная на машинный носитель в форме, понятной эксперту и пользователю (обычно на некотором языке, приближенном к естественному).
Решатель – программа, моделирующая ход рассуждений эксперта на основании знаний, имеющихся в базе знаний. Синонимы: дедуктивная машина, машина вывода, блок логического вывода.
Подсистема объяснений – программа, позволяющая пользователю получить ответы на вопросы: «Как была получена та или иная рекомендация?» и «Почему система приняла такое решение?» Ответ на вопрос «как» – это трассировка всего процесса получения решения с указанием использованных фрагментов базы знаний, то есть всех шагов цепи умозаключений. Ответ на вопрос «почему» – ссылка на умозаключение, непосредственно предшествовавшее полученному решению, то есть отход на один шаг назад. Развитые подсистемы объяснений поддерживают и другие типы вопросов.
Интеллектуальный редактор базы знаний – программа, представляющая инженеру по знаниям возможность создавать базу знаний в диалоговом режиме. Включает в себя систему вложенных меню, шаблонов языка представления знаний, подсказок и других сервисных средств, облегчающих работу с базой.
Описанная структура является базовой и может расширяться (рис. 31).
Обозначенные штриховой линией подсистемы моделирования внешнего мира, интерфейс с внешним миром, система датчиков необходимы для экспертных систем реального времени для получения данных и их интерпретации. Экспертные системы могут накапливать опыт в виде прецедентов (уже разрешенных ситуаций), которые сохраняются в базе знаний и используются в дальнейшем.
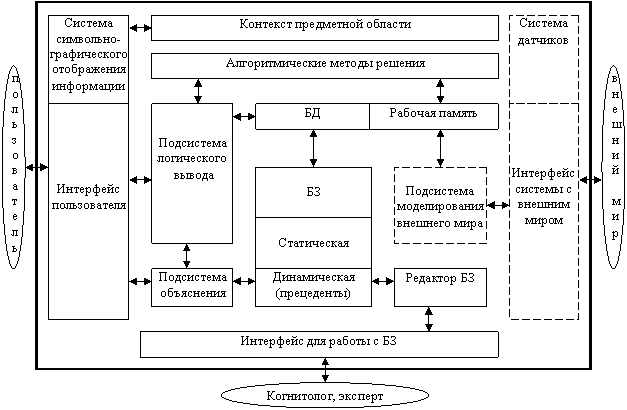

Рис. 31. Структура экспертной системы
Блок алгоритмических методов решения включает в себя все вычислительные операции и алгоритмы, реализуемые методами традиционного программирования, интегрированные в экспертную систему. Объединение в рамках экспертной системы методов традиционного программирования и искусственного интеллекта позволяет значительно повысить эффективность и качество принимаемых решений.
Специфика предметной области, для которой строится система, отображается и описывается не только в базе знаний, но и в подсистеме «Контекст предметной области», которая позволяет более наглядно представить входную и выходную информацию в принятом для конкретной предметной области виде.
Современные информационные системы часто используют архитектуру «клиент-сервер», позволяющую строить распределенные и сетевые приложения. При клиент-серверной архитектуре экспертной системы на стороне клиента находятся интерфейсы пользователя, эксперта, внешней среды и система датчиков. Остальные блоки располагаются на серверной стороне.
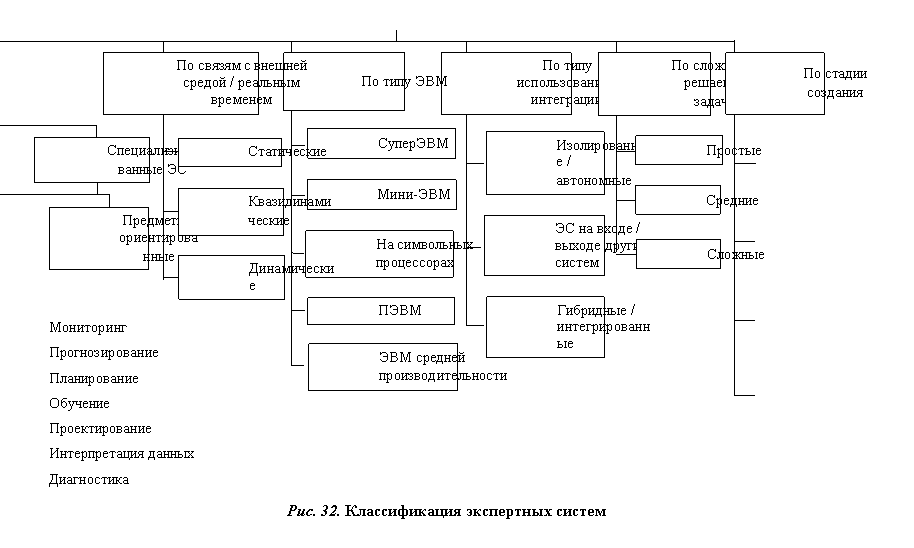
Классификация экспертных систем и оболочек экспертных систем
Существующее множество экспертных систем делится на несколько классов (рис. 32) по различным критериям.
По назначению выделяют системы общего назначения, которые претендуют на универсальность в решении задач (CASNET), и специализированные, решающие конкретную задачу (1-st Clas, Элис) или ориентированные на определенную предметную область (MYCIN, MACSYMA, МОДИС, ДИАГЕН, INTERNIST-I).
По критерию взаимодействия с внешней средой различают статические системы, в которых есть только интерфейс пользователя, а механизм взаимодействия с внешним миром, например через датчики, отсутствует, и динамические, которые с помощью встроенных интерфейсов получают информацию с внешних датчиков или других устройств. Квазидинамические экспертные системы получают информацию об изменении ситуации во внешней среде через заданный промежуток времени (больше нескольких секунд).
Экспертные системы разрабатываются для различных ЭВМ и различаются по аппаратно-программной платформе. Они разрабатываются и эксплуатируются на персональных (PROSPECTOR), символьных (Picon), мини - (СПЭИС) и суперкомпьютерах (ЭКСПЕРТИЗА).
По степени интеграции экспертные системы могут быть автономными программными комплексами (ДАМП), которые работают самостоятельно, или частью более общей системы (интегрированные системы), а также звеном в цепочке программ, обрабатывающих информацию с общей целью, например управления предприятием.
В зависимости от размера базы знаний выделяют простые экспертные системы – до 1000 простых правил (GUIDON, Плотина), средние – от 1000 до 10000 структурированных правил (XCON, GOSSEYN, ДИАГЕН) и сложные – более 10000 структурированных правил.
Экспертные системы различаются по стадии существования, то есть по степени завершенности системы. Первая стадия существования экспертной системы – это исследовательский образец. Он разрабатывается 3-6 месяцев с минимальной базой знаний (SYSTEM-D, SYN). Вторая – демонстрационный образец – разрабатывается 6-12 месяцев (THYROID MODEL); третья – промышленный образец – разрабатывается 1-1,5 года с полной базой знаний (PUFF, FOSSIL) и последняя – коммерческий образец – разрабатывается 1,5-3 года с полной базой знаний (KNEECAP, MACSYMA).
![]()
|
|
|
|
|
|
|
|

Средства разработки экспертных систем
Существующие средства разработки экспертных систем можно разделить на 3 класса (рис. 33). Традиционные языки программирования (C++, Java, Delphi) позволяют построить экспертные системы «с нуля» для конкретной задачи или предметной области, обеспечив хорошие показатели качества и необходимую функциональность системы, но на разработку требуются значительные временные и финансовые ресурсы. Так создают экспертные системы любой стадии существования, в особенности коммерческие системы, продажа которых возместит затраты.
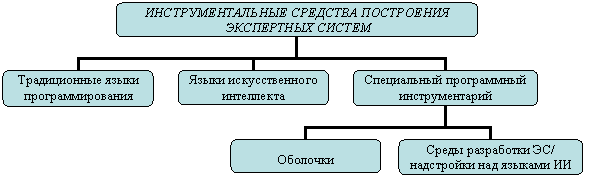

Рис. 33. Классификация инструментальных средств разработки ЭС
Языки искусственного интеллекта (LISP, PROLOG, Рефал) были разработаны специально для представления знаний. Построение с их помощью экспертных систем позволяет более легко оперировать экспертными знаниями, но ограничивает способ их представления структурой языка. С помощью языков искусственного интеллекта создаются исследовательские и демонстрационные образцы.
Следующий класс средств построения экспертных систем – специальный программный инструментарий – ориентирован только на создание интеллектуальных информационных систем и делится на два подкласса: оболочки и среды разработки интеллектуальных систем.
Среды разработки являются программными комплексами, позволяющими строить системы из отдельных готовых блоков. На их основе создаются демонстрационные и промышленные образцы экспертных систем.
Оболочка экспертных систем – инструментальное средство для проектирования и создания экспертных систем. В состав оболочки входят средства проектирования базы знаний с различными формами представления знаний и выбора режима работы решателя задач. Для конкретной предметной области инженер по знаниям определяет нужное представление знаний и стратегии решения задач, а затем, вводя их в оболочку, создает конкретную экспертную систему.
Применение оболочки позволяет достаточно быстро и с минимальными затратами создать исследовательскую, демонстрационную или промышленную экспертную систему. Оболочки можно классифицировать следующим образом (рис. 34). По степени отработанности выделяют экспериментальную (GPSI), исследовательскую (Expert) и коммерческую (EXSYS) оболочки.
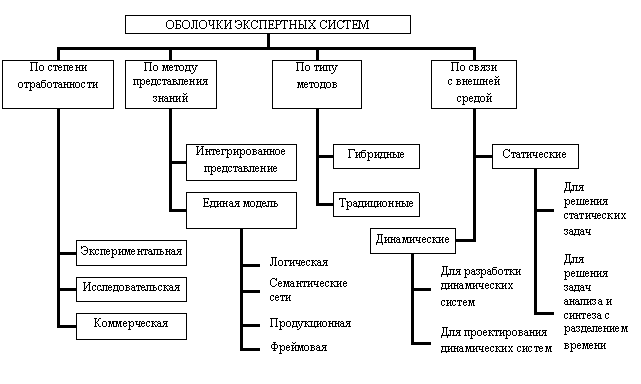

Рис. 34. Классификация оболочек экспертных систем
Знания в базе могут быть представлены одним способом (EMYCIN, CLIPS) – семантической сетью, продукциями, фреймами и т. д. или же несколькими (MINEVRA, EsWin) для создания более полной, гибкой и наглядной модели предметной области.
Используемые в оболочке методы могут быть традиционными (CubiCalc, NEXPERT, Алеф) – алгоритмы, деревья вывода и т. д. и гибридными (FuzzyCLIPS, MultiNeuron), где совместно с традиционными используются нейронные сети, нечеткая логика и т. д.
Существуют статические оболочки, предназначенные для решения статических задач (1-st Clas, Элис). Они характеризуются использованием поверхностной технологии, общих правил и поиска решения от цели к данным, применяются для решения задач анализа.
Статические оболочки, предназначенные для решения задач анализа и синтеза с разделением времени (KAPPA, Clips), используют глубинный и структурный подходы, осуществляют поиск решений от цели к данным и от данных к цели.
Оболочки для проектирования динамических систем (Framework, NExpert) применяют поверхностный подход, принимают решения на основе правил общего вида.
Оболочки для разработки динамических систем (G2, Rethink, RkWorks) имеют подсистему моделирования, планировщика решений, используют смешанную технологию, правила общего и частного вида, решение задачи анализа и синтеза в реальном времени.
EMYCIN – первая оболочка, основанная на MYCIN. Принципы, разработанные для PROSPECTOR, были использованы при создании таких систем, как KAS, SAGE, SAVOIR.
Изменение принципов построения ведет к развитию инструментария. Поэтому оболочки прошли тот же эволюционный путь, что и ЭС. Современные оболочки предлагают следующие возможности (в каждой конкретной оболочке представлены частично):
- гибридное представление знаний (EsWin);
- выбор из нескольких стратегий вывода (G2, CLIPS );
- подключение библиотек и других систем (ACTIVATION FRAMEWORK);
- архитектура на основе «доски объявлений» (HEARSAY-III);
- архитектура «клиент-сервер» (JESS);
- интеграция в Интернет / Интранет (Egg2Lite, Exsys Corvid);
- графический интерфейс (WindExS, WxCLIPS);
- подсистема моделирования (G2);
- модульное построение системы (ReThink, G2);
- визуализация структуры БЗ (W. E.S. T.) и т. д.
Тест по теме «Экспертные системы»
1. Как называлась первая экспертная система?
a) MACSYMA
b) EMYCIN
c) PROSPECTOR
d) нет правильного ответа
2. Какую задачу решала экспертная система PROSPECTOR?
a) определение наиболее вероятной структуры химического соединения
b) поиск месторождений на основе геологических анализов
c) диагностика глазных заболеваний
d) распознавание слитной человеческой речи
e) нет правильного ответа
3. Какие подсистемы являются для экспертной системы обязательными?
a) база знаний
b) интерфейс системы с внешним миром
c) алгоритмические методы решений
d) интерфейс когнитолога
e) контекст предметной области
4. Какая экспертная система имеет базу знаний размером от 1000 до 10000 структурированных правил?
a) простая
b) средняя
c) сложная
5. Какая экспертная система разрабатывается 1-1,5 года?
a) исследовательский образец
b) демонстрационная
c) коммерческая
d) нет правильного ответа
6. Для решения каких задач предназначены статические оболочки экспертных систем?
a) для управления и диагностики в режиме реального времени
b) для решения статических задач
c) для решения задач анализа и синтеза с разделением времени
d) для разработки динамических систем
e) нет правильного ответа
7. Гибридная экспертная система подразумевает:
a) использование нескольких средств разработки
b) использование различных подходов к программированию
c) использование нескольких методов представления знаний
d) нет правильного ответа
8. Кто создает базу знаний экспертной системы?
a) программист
b) пользователь
c) когнитолог
d) эксперт
Литература по теме «Экспертные системы»
1. Гаврилова, знаний интеллектуальных систем / , . – СПб. : Питер, 2001. – 384 с.
2. Джарратано, Д. Экспертные системы: принципы разработки и программирование : пер. с англ. / Д. Джарратано, Г. Райлт. – 4-е изд. – М. : . Д. Вильямс», 2007. – 1152 с.
3. Кобринский, анализ медицинских экспертных систем / // Новости искусственного интеллекта. – 2005. – № 2. – С. 6 – 18.
4. Попов, системы реального времени / // Открытые системы. – 1995. – № 2(10). – Режим доступа: http://www. masters. donntu. /2007/kita/kostanda/library/Open_Systems_Magazine. htm
5. Рот, М. Интеллектуальный автомат: компьютер в качестве эксперта /
М. Рот. – М. : Энергоатомиздат, 1991. – 80 с.
6. Частиков, экспертных систем. Среда CLIPS /
, , . – СПб. : БХВ-Петербург, 2003. – 608 с.
7. Элти, Дж. Экспертные системы: концепции и примеры / Дж. Элти,
М. Кумбс ; пер. с англ. и предисл. . – М. : Финансы и статистика, 1987. – 191 с.
§2. Системы поддержки принятия решений
Системы поддержки принятия решений – это программные средства и информационно-аналитические технологии, предназначенные специально для оказания помощи в решении задач поиска, анализа и выбора лучших из возможных вариантов. При этом лицо, принимающее решение, должно обеспечиваться не только информационной, но в первую очередь технологической поддержкой процедуры, вплоть до выбора лучшего решения.
Понятие о поддержке в принятии решений сформулировали П. Кин и Ч. Стэйбел. Ранние определения систем поддержки принятия решений (в начале 70-х годов прошлого века) отражали следующие три свойства систем:
Ÿ возможность оперировать с неструктурированными или слабоструктурированными задачами, в отличие от задач, с которыми имеет дело исследование операций;
Ÿ интерактивные автоматизированные (то есть реализованные на базе компьютера) системы;
Ÿ разделение данных и моделей.
В современном представлении идеальная система поддержки принятия решений:
Ÿ оперирует со слабоструктурированными решениями;
Ÿ предназначена для лица, принимающего решения, различного уровня;
Ÿ может быть адаптирована для группового и индивидуального использования;
Ÿ поддерживает как взаимозависимые, так и последовательные решения;
Ÿ поддерживает 3 фазы процесса решения: интеллектуальную часть, проектирование и выбор;
Ÿ поддерживает разнообразные стили и методы решения, что может быть полезно при решении задачи группой лиц, принимающих решения;
Ÿ является гибкой и адаптируется к изменениям как организации, так и ее окружения;
Ÿ проста в использовании и модификации;
Ÿ улучшает эффективность процесса принятия решений;
Ÿ позволяет человеку управлять процессом принятия решений с помощью компьютера, а не наоборот;
Ÿ поддерживает эволюционное использование и легко адаптируется к изменяющимся требованиям;
Ÿ может быть легко построена, если возможно сформулировать логику конструкции системы поддержки принятия решений;
Ÿ поддерживает моделирование;
Ÿ позволяет использовать знания.
До середины 60-х годов ХХ века создание больших информационных систем было чрезвычайно дорогостоящим, поэтому первые информационные системы менеджмента (Management Information Systems) были созданы в эти годы лишь в достаточно больших компаниях. Они предназначались для подготовки периодических структурированных отчетов для менеджеров. Но информационные системы способны на большее. В конце 60-х годов появляется новый тип информационных систем – модель-ориентированные системы поддержки принятия решений (Decision Support Systems) или системы управленческих решений (Management Decision Systems).
70-е годы ХХ века стали периодом возникновения ранних систем поддержки принятия решений и теоретических изысканий. К 1975 году Дж. Д. Литтл разработал систему Brandaid (Поддержка бренда), которая предназначалась для поддержки принятия решений в производстве, продвижении, ценообразовании и рекламе. Также Литтл в своей более ранней статье сформулировал критерии по формированию моделей и систем для поддержки принятия решений для менеджмента: надежность, легкость контроля, простота и полнота набора необходимых деталей.
В начале 80-х годов исследователи из академических институтов создали новую категорию программного обеспечения для поддержки группового принятия решений. Самыми ранними вариантами таких систем были Mindsight компании Execucom Systems, GroupSystems, созданные в Аризонском университете, и система SAMM, созданная исследователями Университета Миннесоты. В 1984 году в Университете Аризоны была завершена разработка системы PLEXSYS и сформирована служба компьютеризованной поддержки групповых решений.
Новые технологии стали использовать совместно с системами поддержки принятия решений. Примерно с 1990-го года Б. Инмон и Р. Кимбел начали продвигать системы поддержки принятия решений, построенные с помощью технологий реляционных баз данных. Активно разрабатывались системы поддержки принятия решений, основанные на архитектуре «клиент-сервер», до этого в основном использовались большие компьютеры (mainframe). Системы поддержки принятия решений стали интегрироваться в долговременные хранилища. Системы поддержки принятия решений, использующие возможности Интернета, стали реальностью около 1995 года.
Структура систем поддержки принятия решений
Структура системы поддержки принятия решений зависит от решаемой задачи, предметной области, аппаратно-программной платформы и конкретной реализации. В самом общем виде систему поддержки принятия решения можно представить в виде двух подсистем: системы поддержки генерации решений и системы поддержки выбора решений (рис. 35).
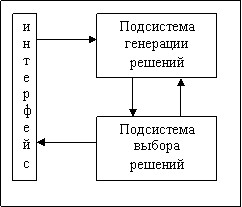

Рис. 35. Обобщенная структура системы поддержки принятия решений
Системы поддержки генерации решений можно разделить на эвристические и оптимизационные. Эвристические технологии стимулируют и дисциплинируют мышление (например, структурный и морфологический анализ), помогают находить варианты решений на базе известных правил, принципов и аналогов. Однако при формировании вариантов решений уникальных задач (например, при стратегическом планировании) их применимость часто ограничивают вспомогательными функциями. Оптимизационные системы поддержки принятия решений основаны на методах оптимального структурного синтеза и параметрической оптимизации.
Системы поддержки выбора решений предназначены для выбора эффективных вариантов решения, сгенерированных любым из вышеперечисленных методов либо поступивших извне (например, заявок на финансирование инвестиционных проектов). Эти системы базируются на методах многокритериального анализа и экспертных оценок.
Другой вариант обобщенной архитектуры системы поддержки принятия решений состоит из пяти частей (рис. 36): источники данных (часто используется база данных), система управления данными (если источников несколько, подсистема объединяет, проверяет и синхронизирует их), модели управления (включают в себя модели решаемой задачи и внешнего мира), машина вывода (позволяет с помощью имеющихся данных и моделей получить и обосновать решение) и интерфейс пользователя.
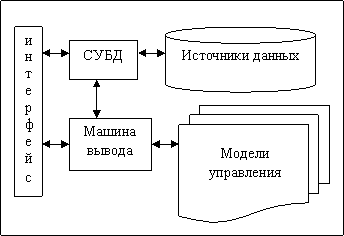
Рис. 36. Компоненты системы поддержки принятия решений
Систему поддержки принятия решений можно представить в виде процессов (рис. 37).
Система проводит сбор запрашиваемых у пользователя или внешних датчиков данных и вложенных в нее при создании данных и знаний. После этого определяет состояние, в котором находится система и решаемая задача, критерии и цели (может запрашивать и уточнять у пользователя). На основе полученных данных, которые содержатся в памяти, и имеющейся модели системы или задачи с учетом сформированных критериев и целей генерируется множество решений, которые проверяются на модели, и выбирается лучшее. После реализации решения производится оценка результатов: если она неудовлетворительная, то процессы генерации и выбора повторяются с учетом новых данных.
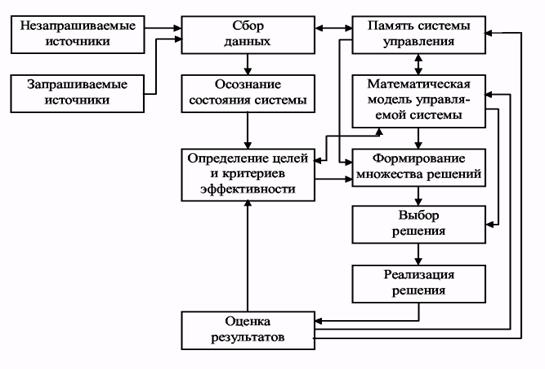

Рис. 37. Процессы системы поддержки принятия решений
С информационно-аналитической точки зрения, задачей системы поддержки принятия решений является агрегирование (сжатие) многокритериальной информации об анализируемых объектах до объема и формы представления, воспринимаемых лицом, принимающим решение.
С программно-технологической точки зрения, варианты решений являются для системы принятия решений просто анализируемыми объектами, которые характеризуются наборами количественных и качественных характеристик (показателей).
Чаще всего системы принятия решений используют при стратегическом планировании и выборе организации сложных систем. Несмотря на уникальность каждой из таких задач, при их решении используется типовая технология обработки информации. Поэтому в мире уже достаточно широко используются универсальные системы поддержки принятия решений, предназначенные для сравнения и выбора вариантов любых решений. Задача пользователя таких систем заключается в настройке универсальной программной оболочки на нужную предметную область путем ввода (импорта) информации об анализируемых объектах, а также иерархии требований и предпочтений. Для универсальных систем принятия решений анализируемыми объектами могут являться любые объекты, для которых требуется дать оценку их соответствия предъявляемым требованиям по многим критериям, принять решение альтернативного выбора, например «выбрать лучшее из...» или «одобрить-отвергнуть», принять решение о распределении ресурсов среди группы объектов, исходя из их текущей приоритетности.
В зависимости от решаемой задачи в системах поддержки принятия решений могут использоваться различные методы принятия решений, привлекаться модели и методы, разработанные в рамках предметной области. Примерами методов принятия решения являются:
Ÿ декомпозиция главной цели до того уровня детализации, когда для нижнего уровня иерархии целей можно сформулировать критерии, позволяющие адекватно описать степень достижения целей при принятии той или иной альтернативы;
Ÿ метод аналитических иерархических процессов (лицо, принимающее решение, осуществляет вначале попарное сравнение значимости выбранных критериев, затем этот же метод используется для попарного сравнения альтернатив относительно каждого выбранного критерия; на основе этого система поддержки принятия решений рассчитывает коэффициенты значимости критериев, коэффициенты значимости альтернатив относительно каждого критерия, что позволяет рассчитать для каждой альтернативы значения линейной функции полезности);
Ÿ метод аналитических сетевых процессов, который позволяет учесть взаимосвязи между критериями;
Ÿ многоцелевое оценивание альтернатив (каждая альтернатива оценивается единым показателем эффективности – степенью влияния его выполнения на достижение главной цели).
Системы поддержки принятия решений начинают все шире применяться государственными организациями и крупными корпорациями
(U. S. Navy, NASA, IBM, General Motors, Xerox, 3M, Rockwell International, Reiter Consulting Group International и др.). Примеры задач, решаемых с привлечением таких систем:
· обоснование направлений развития систем высшего образования США на период гг.;
· выбор методов завоевания рынка бытовой техники;
· оценка привлекательности регионов США для трудоустройства людей, окончивших колледж, в ближайшие 10 лет;
· распределение средств между мероприятиями, направленными на уменьшение бандитизма;
· оценка перспективности видов альтернативного горючего для автомобилей;
· распределение средств между проектами социальной программы гуманитарной направленности;
· отбор научно-технических проектов в рамках конкурса;
· выбор перспективных направлений информатизации страны и пр.
В последнее время системы поддержки принятия решений начинают применяться и в интересах малого и среднего бизнеса (например, выбор варианта размещения торговых точек, выбор кандидатуры на замещение вакантной должности, выбор варианта информатизации и т. д.).
Классификация систем поддержки принятия решений
Общепринятой исчерпывающей классификации систем поддержки принятия решений не существует, но системы поддержки принятия решений можно разделить по нескольким уровням.
На уровне пользователя системы поддержки принятия решений можно разделить на:
Ÿ пассивные;
Ÿ активные;
Ÿ кооперативные.
Пассивной системой поддержки принятия решений называется система, которая помогает процессу принятия решения, но не может вынести предложение, какое решение принять.
Активная система может сделать предложение, какое решение следует выбрать.
Кооперативная система позволяет лицу, принимающему решение, изменять, пополнять или улучшать решения, предлагаемые системой, посылая затем эти изменения в систему для проверки. Система изменяет, пополняет или улучшает эти решения и посылает их опять пользователю. Процесс продолжается до получения согласованного решения.
На концептуальном уровне выделяют следующие системы поддержки принятия решений:
Ÿ управляемые сообщениями;
Ÿ управляемые данными;
Ÿ управляемые документами;
Ÿ управляемые знаниями;
Ÿ управляемые моделями.
Система, управляемая сообщениями, поддерживает группу пользователей, работающих над выполнением общей задачи.
Системы, управляемые данными, ориентируются на доступ и манипуляции с данными.
Системы, управляемые документами, осуществляют поиск и манипулируют неструктурированной информацией, заданной в различных форматах.
Системы, управляемые знаниями, обеспечивают решение задач в виде фактов, правил, процедур.
Системы, управляемые моделями, базируются на математических моделях (статистических, финансовых, оптимизационных, имитационных). Для их построения можно использовать OLAP-системы, позволяющие осуществлять сложный анализ данных, и тогда такую систему поддержки принятия решения можно отнести к гибридным системам, которые обеспечивают моделирование, поиск и обработку данных.

На уровне данных, с которыми эти системы работают, условно можно выделить:
Ÿ оперативные;
Ÿ стратегические.
Оперативные системы поддержки принятия решений предназначены для немедленного реагирования на изменения текущей ситуации в управлении финансово-хозяйственными процессами компании.
Стратегические системы ориентированы на анализ значительных объемов разнородной информации, собираемой из различных источников.
На уровне решаемой задачи и области применения выделяют системы поддержки принятия решений:
· первого класса;
· второго класса;
· третьего класса.
Системы поддержки принятия решений первого класса, обладающие наибольшими функциональными возможностями, предназначены для применения в органах государственного управления высшего уровня (администрация президента, министерства) и органах управления больших компаний (совет директоров корпорации) при планировании крупных комплексных целевых программ для обоснования решений относительно включения в программу различных политических, социальных или экономических мероприятий и распределения между ними ресурсов на основе оценки их влияния на достижение основной цели программы. Системы поддержки принятия решений этого класса являются системами коллективного пользования, базы знаний которых формируются многими экспертами – специалистами в различных областях знаний.
Системы поддержки принятия решений второго класса являются системами индивидуального пользования, базы знаний которых формируются непосредственным пользователем. Они предназначены для использования государственными служащими среднего ранга, а также руководителями малых и средних фирм для решения оперативных задач управления.
Системы поддержки принятия решений третьего класса являются системами индивидуального пользования, адаптирующимися к опыту пользователя. Они предназначены для решения часто встречающихся прикладных задач системного анализа и управления (например, выбор субъекта кредитования, выбор исполнителя работы, назначение на должность и пр.). Такие системы обеспечивают получение решения текущей задачи на основе информации о результатах практического использования решений этой же задачи, принятых в прошлом. Кроме того, системы этого класса предназначены для использования в торговых предприятиях, торгующих дорогими товарами длительного пользования, в качестве средства «интеллектуальной рекламы», позволяющего покупателю выбрать товар на основе своего опыта применения товаров аналогичного назначения.
На уровне архитектуры системы поддержки принятия решений делятся на:
Ÿ функциональные системы поддержки принятия решений;
Ÿ независимые витрины данных;
Ÿ двухуровневое хранилище данных;
Ÿ трехуровневое хранилище данных.
Они отличаются организацией серверной стороны системы поддержки принятия решений. Характерной чертой функциональной системы является то, что анализ осуществляется с использованием данных из оперативных систем. На клиентской стороне располагается пользовательский интерфейс системы поддержки принятия решений, а на серверной – источники данных для задач принятия решений.
Витрина данных – база данных, функционально-ориентированная и, как правило, содержащая данные по одному из направлений деятельности организации. Она отвечает тем же требованиям, что и хранилище данных, но, в отличие от хранилища, нейтрального к приложениям, в витрине данных информация хранится оптимизированно с точки зрения решения конкретных задач.
Кроме того, под витриной данных иногда понимают относительно небольшое хранилище данных или же часть более общего хранилища данных, специфицированную для использования конкретным подразделением в организации и/или определенной группой пользователей. Если в корпоративной системе имеется две витрины данных, то общие данные, имеющиеся в обеих секциях одновременно, должны быть представлены в секциях идентично.
Независимые витрины данных часто появляются в организации исторически и встречаются в крупных организациях с большим количеством независимых подразделений, зачастую имеющих свои собственные отделы информационных технологий.
Хранилище данных – предметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию набор данных, организованный для целей поддержки принятия решений; может состоять из нескольких баз данных, имеет свою собственную модель хранения данных. Информация, поступившая в хранилище, не удаляется, не изменяется.
Двухуровневое хранилище данных строится централизованно для предоставления информации в рамках компании. Для поддержки такой архитектуры необходимы специалисты в области хранилищ данных. Это означает, что вся организация должна согласовать все определения и процессы преобразования данных.
Трехуровневое хранилище данных представляет собой единый централизованный источник корпоративной информации. Витрины данных представляют подмножества данных из хранилища, организованные для решения задач отдельных подразделений компании. Пользователи имеют возможность доступа к детальным данным хранилища в случае, если данных в витрине недостаточно, а также для получения более полной картины состояния бизнеса.
В большинстве реальных случаев система принятия решений вне зависимости от класса и архитектуры должна помочь лицу, принимающему решения, формализовать его собственные представления о ценности полученных результатов и затратах на их получение.
Главным в системе принятия решений является не вычислительная часть, а технологическая поддержка процедуры корректного извлечения и формализации субъективных требований и предпочтений специалистов, а также процедуры пошагового агрегирования информации под контролем аналитика. Система поддержки принятия решений – не более чем средство технологической поддержки процедуры принятия решений, последнее слово всегда должно оставаться за экспертом.
Тест по теме «Системы поддержки принятия решений»
1. Что характерно для ранних систем поддержки принятия решений?
a) возможность оперировать неструктурированными или слабоструктурированными задачами, в отличие от задач, с которыми имеет дело исследование операций
b) оперирует слабоструктурированными решениями;
c) поддерживает разнообразные стили и методы решения, что может быть полезно при решении задачи группой лиц, принимающих решения;
d) нет правильного ответа
2. Какие подсистемы входят в системы поддержки принятия решений?
a) системы поддержки генерации решений
b) системы поддержки выбора решений
c) системы управления базами данных
d) системы имитационного моделирования
e) нет правильного ответа
3. Какие методы используют в системах поддержки принятия решений?
a) метод аналитических иерархических процессов
b) метод Гаусса
c) математическое моделирование
d) метод аналитических сетевых процессов
e) нет правильного ответа
4. Как можно классифицировать систему поддержки принятия решений?
a) на уровне пользователя
b) в зависимости от языка программирования
c) на концептуальном уровне
d) в зависимости от области применения
5. Какие системы поддержки принятия решений позволяют модифицировать решения системы, опирающиеся на большие объемы данных из разных источников?
a) активные
b) кооперативные
c) стратегические
d) оперативные
e) управляемые данными
f) нет правильного ответа
6. К какому классу относится система поддержки принятия решения, чья база знаний сформирована многими экспертами?
a) первому
b) второму
c) третьему
7. Какие бывают архитектуры систем поддержки принятия решений?
a) независимые витрины данных
b) зависимые витрины данных
c) трехуровневое хранилище данных
d) одноуровневое хранилище данных
8. При какой архитектуре данные хранятся в единственном экземпляре?
a) трехуровневое хранилище данных
b) двухуровневое хранилище данных
c) функциональная система
d) четырехуровневое хранилище данных
Литература по теме «Системы поддержки
принятия решений»
1. Абдрахимов, Д. Поддержка принятия решений: взгляд на место информационно-аналитических технологий поддержки принятия решений в арсенале банковского аналитика [Электронный ресурс] / Д. Абдрахимов, А. Иоффин. – Режим доступа: http://www. *****/rus/bt/1997/nr4/10.htm
2. Горский, П. Мифы и реальность использования научных методов принятия решений в банковском бизнесе / П. Горский // Банковское дело. – 2002. – № 5. – Режим доступа: http://www. *****/bank_business/2002-05/02.html
3. Кравченко, информационные технологии в развитии компьютерных систем поддержки принятия решений [Электронный ресурс] / , . – Режим доступа: http://www. *****/ksit/k4sem24.zip
4. Ларичев, методы принятия решений / , . – М. : Наука : Физматлит, 1996.
5. Лисянский, К. Архитектуры систем поддержки принятия решений [Электронный ресурс] / К. Лисянский. – Режим доступа: http://lissianski. *****/index. html
6. Моисеев, к книге «Проблемы принятия решений при нечеткой исходной информации» / . – М. : Наука, 1981.
7. Пауэр, история развития систем поддержки принятия решений [Электронный ресурс] / . – Режим доступа: *****. http://*****/History/DataTech/DSS/DSS. aspx
8. Принятие решения: основные понятия и концепции [Электронный ресурс]. – Режим доступа: http://de. *****/courses/man/main. htm
9. Тоценко, В. Системы поддержки принятия решений – ваш инструмент для правильного выбора / В. Тоценко // Компьютера. – 1998. – № 34. – Режим доступа: http://*****/offline/1998/262/1520/
10. Трахтенгерц, поддержка принятия решений /
. – М. : СИНТЕГ, 1998.
Глоссарий
Основные определения по теме «История развития
искусственного интеллекта»
Искусственный интеллект (Artificial Intelligence, AI) – научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования тех видов человеческой деятельности, которые традиционно считаются интеллектуальными (представление знаний, обучение, общение и т. п.).
Интеллектуальная система – система или устройство с программным обеспечением, имеющие возможность с помощью встроенного процессора настраивать свои параметры в зависимости от состояния внешней среды.
Эвристика – процесс поиска решений; прием решения задачи, основанный не на строгих математических моделях и алгоритмах, а на соображениях, восходящих к «здравому смыслу»; отражает особенности того, как такие задачи решает человек, когда он не пользуется строго формальными приемами.
Кибернетика – наука об управлении, связи и переработке информации. Основным объектом исследования кибернетики являются абстрактные кибернетические системы – от компьютеров до человеческого мозга и человеческого общества.
Теория игр – математическая теория предсказания результатов игр, в которых участники не имеют полной информации о намерениях друг друга. Теория игр используется для описания процессов, происходящих на олигополистических рынках, и в теории фирм.
Теория принятия решений – область исследования, изучающая закономерности выбора людьми путей решения разного рода задач и исследующая способы поиска наиболее выгодных из возможных решений.
Когнитивная психология – направление в психологической науке, изучающее зависимость поведения субъекта от познавательных процессов. Главное в когнитивной психологии – выделение некоторых общих компонентов, структур, процессов, характерных для познания в целом. В этом плане когнитивная психология – это современная психология познавательных процессов.
Основные определения по теме «Направления исследований
в области искусственного интеллекта»
Нейрокибернетика – научное направление, изучающее основные закономерности организации и функционирования нейронов и нейронных образований. Основным методом нейрокибернетики является математическое моделирование, при этом данные физиологического эксперимента используются в качестве исходного материала для создания моделей.
Нейрокомпьютеры – это системы, в которых алгоритм решения задачи представлен логической сетью элементов частного вида – нейронов с полным отказом от булевских элементов типа и, или, не. Как следствие этого, введены специфические связи между элементами, которые являются предметом отдельного рассмотрения.
Нейрокомпьютинг – скороразвивающаяся область вычислительных технологий, стимулированная исследованиями мозга. Вычислительные операции выполняются огромным числом сравнимо обычных, нередко адаптивных процессорных частей. Нейрокомпьютинг, по собственному происхождению, совершенно приспособлен для сравнения образов, определения образов и синтеза систем управления.
Робот – автоматическое устройство с антропоморфным действием, которое частично или полностью заменяет человека при выполнении работ в опасных для жизни условиях или при относительной недоступности объекта. Робот может управляться оператором либо работать по заранее составленной программе. Использование роботов позволяет облегчить или вовсе заменить человеческий труд на производстве, в строительстве, при работе с тяжелыми грузами, вредными материалами, а также в других тяжелых или небезопасных для человека условиях.
Компьютерная лингвистика (computational linguistics) – область использования компьютеров для моделирования функционирования языка в тех или иных условиях или проблемных областях, а также сфера применения компьютерных моделей языка в лингвистике и др. дисциплинах.
Распознавание образов (Pattern recognition) – разделение образов в неком пространстве на классы. Образ традиционно представляется в виде вектора измеренных величин.
Распознавание речи (Speech recognition) – автоматическое разложение звукового вида на фонемы и слова.
Естественный язык – в лингвистике любой язык общения между людьми. Под естественностью некоторого языка понимается наличие синонимии и омонимии слов и словосочетаний, а также свободный порядок слов в предложении.
Проблемная область интеллектуальной системы определяется предметной областью и решаемыми в ней задачами.
Предметную область можно характеризовать описанием области в терминах пользователя, а задачи – их типом. С точки зрения разработчика, выделяются статические и динамические предметные области. Предметная область называется статической, если описывающие ее исходные данные не изменяются во времени. При этом производные данные (выводимые из исходных) могут появляться заново и изменяться (не изменяя при этом исходных данных). Если исходные данные, описывающие предметную область, изменяются за время решения задачи, то предметную область называют динамической.
Основные определения по теме «Представление знаний»
Данные – это отдельные факты, характеризующие объекты, процессы и явления предметной области, а также их свойства; сведения, полученные путем измерения, наблюдения, логических или арифметических операций, представленные в форме, пригодной для постоянного хранения, передачи и (автоматизированной) обработки.
Знания – это закономерности предметной области (принципы, связи, законы), полученные в результате практической деятельности и профессионального опыта, позволяющие специалистам ставить и решать задачи в этой области; это хорошо структурированные данные, или данные о данных, или метаданные.
Поверхностные знания – знания о видимых взаимосвязях между отдельными событиями и фактами в предметной области.
Глубинные знания – абстракции, аналогии, схемы, отображающие структуру и природу процессов, протекающих в предметной области. Эти знания объясняют явления и могут использоваться для прогнозирования поведения объектов.
Процедурные знания – знания, «растворенные» в алгоритмах.
Декларативными знаниями считаются предложения, записанные на языках представления знаний, приближенных к естественному и понятных неспециалистам.
Эмпирические знания – знания, которые могут добываться ИС путем наблюдения за окружающей средой.
Поле знаний – поле, в котором содержатся основные понятия, используемые при описании предметной области, и свойства всех отношений, используемых для установления связей между понятиями. Поле знаний связано с концептуальной моделью проблемной области, в которой еще не учтены ограничения, которые неизбежно возникают при формальном представлении знаний в базе знаний.
Семантическая сеть – это ориентированный граф, вершины которого – понятия, а дуги – отношения между ними.
Фрейм – это абстрактный образ для представления некоего стереотипа восприятия.
Основные определения по теме «Нейронные сети»
Нейрон (биологический) – клетка мозга, способная генерировать электрический импульс в случае, когда суммарный потенциал превысит критическую величину. Соединяясь друг с другом, нейроны образуют сеть, по которой путешествуют электрические импульсы; именно нейронные сети мозга обрабатывают информацию. При этом «обучение» сети и запоминание информации базируется на настройке значений весов связей между нейронами.
Синапс (вес, синаптический вес) – межнейронное соединение, однонаправленная входная связь нейрона, соединенная с выходом другого нейрона.
Аксон – выходная связь нейрона: при помощи аксона нейрон передает собственный выходной сигнал.
Искусственная нейронная сеть (Artificial neural network) – это система, состоящая из многих простых вычислительных элементов, работающих параллельно, функция которых определяется структурой сети, силой взаимных связей, а вычисления производятся в самих элементах или узлах.
Нейронные сети – класс моделей, основанных на биологической аналогии с мозгом человека и предназначенных после прохождения этапа так называемого обучения на имеющихся данных для решения разнообразных задач анализа данных.
Нейронная сеть – это процессор с массивным распараллеливанием операций, обладающий естественной способностью сохранять экспериментальные знания и делать их доступными для последующего использования. Он похож на мозг в двух отношениях: сеть приобретает знания в результате процесса обучения и для хранения информации используются величины интенсивности межнейронных соединений, которые называются синаптическими весами.
Нейрокомпьютер – это вычислительная система с архитектурой аппаратного и программного обеспечения, адекватной выполнению алгоритмов, представленных в нейросетевом логическом базисе.
Обучение нейронной сети (Training) – целенаправленный процесс изменения межслойных синаптических связей, итеративно повторяемый до тех пор, пока сеть не приобретет необходимые свойства.
Обучение с учителем, или обучение контролируемое, или обучение управляемое (Supervised learning, Associative learning). Обучение с учителем предполагает, что для каждого входного вектора существует целевой вектор, представляющий собой требуемый выход. Вместе они называются обучающей парой. Предъявляется выходной вектор, вычисляется выход сети и сравнивается с соответствующим целевым вектором, разность (ошибка) с помощью обратной связи подается в сеть, и веса изменяются в соответствии с алгоритмом, стремящимся минимизировать ошибку. Векторы обучающего множества предъявляются последовательно, вычисляются ошибки, и веса подстраиваются для каждого вектора до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо низкого уровня.
Обучение без учителя, или самообучение, или обучение неконтролируемое, или обучение неуправляемое (Unsupervised learning, Self-organization). Алгоритм обучения без учителя подстраивает веса сети так, чтобы получались согласованные выходные векторы, то есть чтобы предъявление достаточно близких входных векторов давало одинаковые выходы. Процесс обучения выделяет статистические свойства обучающего множества и группирует сходные векторы в классы.
Переобучение сети (Over training, Overfitting). Если в результате обучения нейронная сеть хорошо распознает примеры из обучающего множества, но не приобретает свойство обобщения, то есть не распознает или плохо распознает любые другие примеры, кроме обучающих, то говорят, что сеть переобучена. Переобучение – это результат чрезмерной подгонки сети к обучающим примерам.
Сходимость процесса обучения (Coincidence of the learning algorithm). Целью процедуры минимизации является отыскание глобального минимума, достижение его называется сходимостью процесса обучения.
Задача классификации (Classification problem) заключается в разбиении объектов на классы, когда основой разбиения служит вектор параметров объекта. Объекты в пределах одного класса считаются эквивалентными с точки зрения критерия разбиения. Сами классы часто бывают неизвестными заранее и формируются динамически (как, например, в сетях Кохонена). Классы зависят от предъявляемых объектов, и поэтому добавление нового объекта требует корректирования системы классов.
Кластеризация (Сlustering) – это один из методов анализа данных, позволяющих классифицировать многомерные наблюдения, каждое из которых описывается набором переменных X1, X2, …, Xn. Целью кластеризации является образование групп схожих между собой объектов.
Основные определения по теме «Эволюционное моделирование»
Эволюционное моделирование – направление в математическом моделировании, объединяющее компьютерные методы моделирования эволюции, а также близкородственные по источнику заимствования идей другие направления в эвристическом программировании. Включает в себя как разделы генетические алгоритмы, эволюционные стратегии, эволюционное программирование, искусственные нейронные сети, нечеткую логику.
Генетический алгоритм (Genetic algorithm, как направление исследований) – раздел эволюционного моделирования, заимствующий методические приемы из теоретических положений популяционной генетики. Представляет собой своего рода модель машинного исследования поискового пространства, построенную на эволюционной метафоре. Характерные особенности: использование строк фиксированной длины для представления генетической информации, работа с популяцией строк, использование генетических операторов для формирования будущих поколений. Генетические алгоритмы, являясь одной из парадигм эволюционных вычислений, представляют собой алгоритмы случайного направленного поиска для построения (суб)оптимального решения данной проблемы, который моделирует процесс естественной эволюции.
Генетические алгоритмы (как метод) – адаптивные методы поиска, которые используются для решения задач функциональной оптимизации.
Кроссовер, скрещивание (Crossover) – процедура или оператор в генетических алгоритмах, используемые для получения разнообразия в процессе воспроизводства. При одноточечном кроссовере берутся две хромосомы потомка, на них случайным образом выбирается точка, и для этой точки происходит обмен генетического материала потомков. При двухточечном кросcовере происходит то же самое, только выбираются случайным образом две точки.
Мутация (Mutation) – оператор в генетических алгоритмах, предназначенный для внесения разнообразия в процесс размножения; с очень малой вероятностью двоичная мутация заменяет биты в хромосоме случайными битами, значение этой вероятности является параметром генетического алгоритма.
Ген (Gene) в генетических алгоритмах представляет собой основную единицу информации, определяющую характеристику особи. Например, если мы используем генетический алгоритм для обучения нейронной сети, то тогда в качестве генов мы будем использовать веса связей между нейронами. Гены в реализации генетических алгоритмов обычно представляют собой битовые строки фиксированной длины.
Генотип (Genotype) – представление особи в терминах генетического алгоритма.
Фенотип (Phenotype) – представление особи в виде, имеющемся в реальном мире.
Хромосома, особь (Chromosome) – базовый элемент генетического алгоритма. Она представляет собой набор генов, описывающих параметры особи и однозначно определяющих ее. Например, в задаче обучения нейронной сети хромосома будет содержать в себе полностью все настраиваемые параметры. Обычно при реализации генетического алгоритма размер хромосом от эпохи к эпохе не изменяется, хотя встречаются и исключения.
Приспособленность, фитнесс (Fitness) – параметр, определяющий, насколько хорошо данная особь отвечает требованиям. Приспособленность рассчитывается для каждой особи на основе данных, закодированных в генотипе, и используется для выбора наиболее приспособленных особей.
Популяция (Population) – совокупность особей, участвующих в генетических операциях. В классических реализациях алгоритма ее размер постоянен.
Эпоха (Еpoch) – один этап функционирования генетического алгоритма. На нем осуществляется вычисление приспособленности каждой особи популяции. Затем на основании приспособленности отбираются хромосомы, участвующие в формировании следующей эпохи. Затем к ним применяются генетические операции, такие как скрещивание, мутация и т. д.
Основные определения по теме «Нечеткие множества
и нечеткая логика»
Нечеткая логика (Fuzzy logic) – умозаключение с использованием нечетких множеств или множеств нечетких правил. Это направление восходит к первым работам по нечетким множествам, выполенным Лофти Заде (Lofti Zaden) в гг.
Неопределенность является неотъемлемой частью процессов принятия решений. Неопределенности принято разделять на три класса:
· неопределенность, связанная с неполнотой наших знаний о проблеме, по которой принимается решение;
· неопределенность, которая возникает в связи с непредсказуемостью реакции окружающей среды на наши действия;
· неопределенность, связанная с неточным пониманием цели непосредственно самим ЛПР.
Нечеткое множество А Í Х представляет собой набор пар ![]() , где х Î Х и
, где х Î Х и ![]() – функция принадлежности, то есть
– функция принадлежности, то есть 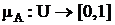 , которая представляет собой некоторую субъективную меру соответствия элемента нечеткому множеству и может принимать значения от нуля, который обозначает абсолютную непринадлежность, до единицы, которая, наоборот, говорит об абсолютной принадлежности элемента х нечеткому множеству А.
, которая представляет собой некоторую субъективную меру соответствия элемента нечеткому множеству и может принимать значения от нуля, который обозначает абсолютную непринадлежность, до единицы, которая, наоборот, говорит об абсолютной принадлежности элемента х нечеткому множеству А.
Нечетким числом называется выпуклое нормальное нечеткое множество с кусочно-непрерывной функцией принадлежности, заданное на множестве действительных чисел.
Лингвистическую переменную можно определить как переменную, значениями которой являются не числа, а слова или предложения естественного (или формального) языка.
Терм-множеством (term set) называется множество всех возможных значений лингвистической переменной.
Термом (term) называется любой элемент терм-множества. В теории нечетких множеств терм формализуется нечетким множеством с помощью функции принадлежности.
Дефаззификацией (defuzzification) называется процедура преобразования нечеткого множества в четкое число.
Фаззификацией (fuzzification) называется процедура преобразования четких значений в степени уверенности.
Нечетким логическим выводом называется получение заключения в виде нечеткого множества, соответствующего текущим значениям входов, с использованием нечеткой базы знаний и нечетких операций.
Нечеткой базой знаний называется совокупность нечетких правил «если… то…», определяющих взаимосвязь между входами и выходами исследуемого объекта. Обобщенный формат нечетких правил такой: если <посылка правила>, то <заключение правила>.
Посылка правила, или антецедент, представляет собой утверждение типа «x есть низкий», где «низкий» – это терм (лингвистическое значение), заданный нечетким множеством на универсальном множестве лингвистической переменной x. Квантификаторы «очень», «более-менее», «не», «почти» и т. п. могут использоваться для модификации термов антецедента.
Заключение, или следствие, правила представляет собой утверждение типа «y есть d», в котором значение выходной переменной d может задаваться:
Ÿ нечетким термом: «y есть высокий»;
Ÿ классом решений: «y есть бронхит»;
Ÿ четкой константой: «y=5»;
Ÿ четкой функцией от входных переменных: «y=5+4*x».
Нечеткая система – множество нечетких правил, преобразующих входные данные в выходные. В простейшем случае эти правила устанавливает эксперт, в более сложном – например, нейросеть.
Нечеткое правило – условное высказывание вида «если X есть A, то Y есть B», где A и B – нечеткие множества.
Основные определения по теме «Экспертные системы»
Экспертные системы – это сложные программные комплексы, аккумулирующие знания специалистов в конкретных предметных областях и тиражирующие эти знания для консультации менее квалифицированных специалистов.
Пользователь – специалист предметной области, для которого предназначена система. Обычно его квалификация недостаточно высока, и поэтому он нуждается в помощи и поддержке своей деятельности со стороны экспертной системы.
Инженер по знаниям – специалист в области искусственного интеллекта, выступающий в роли промежуточного буфера между экспертом и базой знаний. Синонимы: когнитолог, инженер-интерпретатор, аналитик.
Интерфейс пользователя – комплекс программ, реализующих диалог пользователя с ЭС как на стадии ввода информации, так и при получении результатов.
База знаний – ядро ЭС, совокупность знаний предметной области, записанных на машинный носитель в форме, понятной эксперту и пользователю (обычно на некотором языке, приближенном к естественному). Параллельно такому «человеческому» представлению существует БЗ во внутреннем «машинном» представлении.
Решатель – программа, моделирующая ход рассуждений эксперта на основании знаний, имеющихся в БЗ. Синонимы: дедуктивная машина, машина вывода, блок логического вывода.
Подсистема объяснений – программа, позволяющая пользователю получить ответы на вопросы: «Как была получена та или иная рекомендация?» и «Почему система приняла такое решение?» Ответ на вопрос «как» – это трассировка всего процесса получения решения с указанием использованных фрагментов БЗ, то есть всех шагов цепи умозаключений. Ответ на вопрос «почему» – ссылка на умозаключение, непосредственно предшествовавшее полученному решению, то есть отход на один шаг назад. Развитые подсистемы объяснений поддерживают и другие типы вопросов.
Интеллектуальный редактор базы знаний – программа, представляющая инженеру по знаниям возможность создавать БЗ в диалоговом режиме. Включает в себя систему вложенных меню, шаблонов языка представления знаний, подсказок и других сервисных средств, облегчающих работу с базой.
Решение – процесс и результат выбора способа и цели действий из ряда альтернатив в условиях неопределенности.
Приобретением знаний называется выявление знаний из источников и преобразование их в нужную форму, а также перенос в базу знаний ИС. Источниками знаний могут быть книги, архивные документы, содержимое других баз знаний и т. п., то есть некоторые объективизированные знания, переведенные в форму, которая делает их доступными для потребителя.
Экспертные знания – знания, которые имеются у специалистов, но не зафиксированы во внешних по отношению к нему хранилищах. Экспертные знания являются субъективными.
Формализация. Процесс формализации знаний, полученных у эксперта, состоит из следующих шагов: выбор метода измерения нечеткости, получение исходных данных посредством опроса эксперта, реализация алгоритма построения функции принадлежности.
Интерпретация данных. Это одна из традиционных задач для экспертных систем. Под интерпретацией понимается процесс определения смысла данных, результаты которого должны быть согласованными и корректными. Обычно предусматривается многовариантный анализ данных.
Диагностика. Под диагностикой понимается процесс соотнесения объекта с некоторым классом объектов и/или обнаружение неисправности в некоторой системе. Неисправность – это отклонение от нормы. Такая трактовка позволяет с единых теоретических позиций рассматривать и неисправность оборудования в технических системах, и заболевания живых организмов, и всевозможные природные аномалии. Важной спецификой является здесь необходимость понимания функциональной структуры («анатомии») диагностирующей системы.
Мониторинг. Основная задача мониторинга – непрерывная интерпретация данных в реальном масштабе времени и сигнализация о выходе тех или иных параметров за допустимые пределы. Главные проблемы – «пропуск» тревожной ситуации и инверсная задача «ложного» срабатывания. Сложность этих проблем – в размытости симптомов тревожных ситуаций и необходимости учета временного контекста.
Проектирование. Проектирование состоит в подготовке спецификаций на создание «объектов» с заранее определенными свойствами. Под спецификацией понимается весь набор необходимых документов: чертеж, пояснительная записка и т. д. Основные проблемы здесь – получение четкого структурного описания знаний об объекте и проблема «следа». Для организации эффективного проектирования и в еще большей степени перепроектирования необходимо формировать не только сами проектные решения, но и мотивы их принятия. Таким образом, в задачах проектирования тесно связываются два основных процесса, выполняемых в рамках соответствующей ЭС: процесс вывода решения и процесс объяснения.
Прогнозирование. Прогнозирование позволяет предсказывать последствия некоторых событий или явлений на основании анализа имеющихся данных. Прогнозирующие системы логически выводят вероятные следствия из заданных ситуаций. В прогнозирующей системе обычно используется параметрическая динамическая модель, в которой значения параметров «подгоняются» под заданную ситуацию. Выводимые из этой модели следствия составляют основу для прогнозов с вероятностными оценками.
Планирование. Под планированием понимается нахождение планов действий, относящихся к объектам, способным выполнять некоторые функции. В таких ЭС используются модели поведения реальных объектов с тем, чтобы логически вывести последствия планируемой деятельности.
Обучение. Под обучением понимается использование компьютера для обучения какой-то дисциплине или предмету. Системы обучения диагностируют ошибки при изучении какой-либо дисциплины с помощью ЭВМ и подсказывают правильные решения. Они аккумулируют знания о гипотетическом «ученике» и его характерных ошибках, затем в работе они способны диагностировать слабости в познаниях обучаемых и находить соответствующие средства для их ликвидации. Кроме того, они планируют акт общения с учеником в зависимости от успехов ученика с целью передачи знаний.
Управление. Под управлением понимается функция организованной системы, поддерживающая определенный режим деятельности. Такого рода ЭС осуществляют управление поведением сложных систем в соответствии с заданными спецификациями.
Оптимизация – нахождение решения, удовлетворяющего системе ограничений и максимизирующего или минимизирующего целевую функцию.
Основные определения по теме «Системы поддержки
принятия решений»
Принятие решения – это особый вид человеческой деятельности, направленный на выбор лучшей из имеющихся альтернатив. Главной задачей, которую приходится разрешать при принятии решения, является выбор альтернативы, наилучшей для достижения некоторой цели, или ранжирование множества возможных альтернатив по степени их влияния на достижение этой цели.
Процесс принятия решений – получение и выбор наиболее оптимальной альтернативы с учетом просчета всех последствий. Необходимо выбирать ту альтернативу, которая наиболее полно отвечает поставленной цели, но при этом приходится учитывать большое количество противоречивых требований и, следовательно, оценивать выбранный вариант решения по многим критериям.
Системы поддержки принятия решений (DSS, Decision Support System) являются человеко-машинными объектами, которые позволяют лицам, принимающим решения, использовать данные, знания, объективные и субъективные модели для анализа и решения слабоструктурированных и неструктурированных проблем.
Хранилище данных – предметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию набор данных, организованный для целей поддержки принятия решений.
Витрина данных – упрощенный вариант хранилища данных, содержащий только тематически объединенные данные.
Витрина данных, секция данных (Data Mart) – база данных, функционально-ориентированная и, как правило, содержащая данные по одному из направлений деятельности организации. Она отвечает тем же требованиям, что и хранилище данных, но, в отличие от хранилища, нейтрального к приложениям, в витрине данных информация хранится оптимизированно с точки зрения решения конкретных задач.
Рекомендованная литература
Искусственный интеллект и интеллектуальные информационные системы – активно развивающиеся и обширные области исследований, и в рамках одного пособия просто невозможно рассмотреть все вопросы и проблемы, связанные с этими исследованиями. Здесь рассматривались основные направления и подходы. Для более подробного изучения предлагается ознакомиться с рядом книг и пособий, перечисленных ниже.
1. Андрейчиков, информационные системы : учебник для вузов / . – М. : Финансы и статистика, 2004. – 424 с.
2. Гаврилова, знаний интеллектуальных систем / , . – СПб. : Питер, 2001. – 384 с.
3. Гаскаров, информационные системы : учебник для вузов / . – М. : Высшая школа, 2003. – 431 с.
4. Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности / и др. – Харьков : ОСНОВА, 1997. – 112 с.
5. Джарратано, Д. Экспертные системы: принципы разработки и программирование : пер. с англ. / Д. Джарратано, Г. Райлт. – 4-е изд. –
М. : . Д. Вильямс», 2007. – 1152 с.
6. Круглов, логика и искусственные нейронные сети /
, , . – М. : ФИЗМАТЛИТ, 2001. – 224 с.
7. Любарский, информационные системы /
. – М. : Наука, 1990. – 227 с.
8. Макаров, : история и перспективы / , . – М. : Наука : Изд-во МАИ, 2003. – 349 с.
9. Методы и модели анализа данных: OLAP и Data Mining / и др. – СПб. : БХВ-Петербург, 2004. – 336 с.
10. Миркес, : учеб. пособие для студентов /
. – Красноярск : ИПЦ КГТУ, 2002. – 347 с.
11. Нейроинформатика / и др. – Новосибирск : Наука : Сибирское предприятие РАН, 1998. – 296 с.
12. Нечеткие гибридные системы / и др. ; под. ред.
. – М. : ФИЗМАТЛИТ, 2007. – 208 с.
13. Прикладные нечеткие системы : пер. с яп. / К. Асаи и др. ; под ред.
Т. Тэрано, К. Асаи, М. Сугэно. – М. : Мир, 1993. – 368 с.
14. Рассел, С. Искусственный интеллект: современный подход / С. Рассел, П. Норвиг. – 2-е изд. – М. : Вильямс, 2006. – 1408 с.
15. Рутковская, Д. Нейронные сети, генетические алгоритмы и нечеткие системы / Д. Рутковская, М. Пилиньский, Л. Рутковский ; пер. с польск. . – М. : Горячая линия – Телеком, 2008. –
452 с.
16. Ручкин, искусственный интеллект и экспертные системы / , . – СПб. : БХВ-Петербург, 2009. – 240 с.
17. Уоссермен, Ф. Нейрокомпьютерная техника: Теория и практика : пер. с англ. / Ф. Уоссермен. – 1992. – 118 с.
18. Уэно, Х. Представление и использование знаний / Х. Уэно. – М. : Мир, 1989. – 220 с.
19. Фогель, Л. Искусственный интеллект и эволюционное моделирование / Л. Фогель, А. Оуэнс, М. Уолш. – М. : Мир, 1969. – 230 с.
20. Частиков, экспертных систем. Среда CLIPS /
, , . – СПб. : БХВ-Петербург, 2003. – 608 с.
21. Шеховцов, знаний : учеб. пособие / . – СПб. : ГЭТУ, 1997. – 56 с.
22. Ярушкина, теории нечетких и гибридных систем : учеб. пособие / . – М. : Финансы и статистика, 2004. – 320 с.
Учебное издание
, ,
ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Учебное пособие
 |
Директор Издательского центра
Редактирование и подготовка оригинал-макета
 Подписано в печать 26.07.10.
Подписано в печать 26.07.10.
Формат 60х84/16. Усл. печ. л. 7,9. Уч.-изд. л. 6,7.
Тираж 100 экз. Заказ 65 /
Оригинал-макет подготовлен
в Издательском центре
Ульяновского государственного университета
Отпечатано в Издательском центре
Ульяновского государственного университета
2

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 |
