


Использование методов статистики в лингвистических исследованиях
(на материале нидерландско-русских словарей)
Аспирант Воронежского государственного университета, Воронеж, Россия
Нидерландский, или как его раньше называли голландский, язык входит в западногерманскую подгруппу германских языков. Это государственный язык Нидерландов и один из двух государственных языков Бельгии. Общее количество лиц, для которых он является родным, составляет примерно 21 млн.
Целью предлагаемого исследования является выявление закономерностей распределения количества слов нидерландского языка по длине посредством построения адекватной стохастической модели.
Для достижения поставленной цели были решены следующие задачи: 1) создание электронных баз данных исследуемых словарей; 2) обработка и аппроксимация полученных данных различными видами распределений с помощью GNU R; 3) проверка полученных результатов.
Поскольку звуковая форма является первичной реальностью языка, данные по этому параметру брались в звуках. Для этого показатели длины в буквах были обработаны по правилам чтения нидерландского языка. Для анализа были взяты три нидерландско-русских словаря различного размера [Дренясова 1977; Миронов 2006; Баар 2012].
Вся обработка данных и их графическое представление произведена с помощью языка статистической обработки GNU R. В отечественной научно-практической литературе вопрос применения языка R для решения задач математической лингвистики остаётся нераскрытым.
Анализ словарей был проведен с помощью методов описательной статистики, а также посредством визуализации данных на диаграмме типа «скрипка» (violin plot), как это показано на рисунке 1. Эта графическая форма представления дает больше информации о характере распределения, чем «ящик с усами» (box-and-whisker plot), т. к. помимо данных о медиане и квартилях, отражает еще и показатели ядерной плотности распределения [Hintze, Nelson 1998].
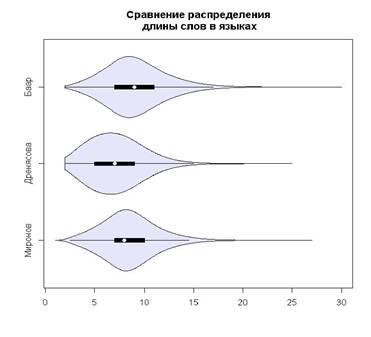
Рис. 1. Распределение в виде скрипки по исследуемым словарям
Из полученного распределения можно сделать вывод о том, что между словарями больших размеров наблюдается больше сходства, чем с малым словарем. Разницу в положении медианы можно объяснить тем, что в словарях большого объема больше представлена специальная лексика и термины, которые обычно обладают большей длиной, нежели общеупотребительные слова. Также можно заметить, что распределение ассиметрично со смещением вправо.
Затем полученные данные были обработаны методом бутстреппинга по методике Каллена и Фрея [Cullen, Frey 1999], чтобы на основании расчета моментов выяснить, какое распределение следует использовать для последующей аппроксимации. Наиболее близкие результаты дали отрицательное биноминальное распределение и распределение Пуассона. Дальнейший анализ результатов аппроксимации методом максимального правдоподобия показал, что более адекватно в данном случае распределение Пуассона. Оно относится к семейству дискретных распределений и задаётся следующей функцией вероятности:
![]() , где (1)
, где (1)
λ>0; k=0,1,2,…; e – основание натурального логарифма.
Проведенные вычисления показали, что при использовании при аппроксимации распределения Пуассона λ ≈ средней длине слова в анализируемом словаре. Так, для словаря ван ден Баара эта величина равно 9,1, для словаря Миронова — 8,5, для словаря Дренясовой — 7,1.
Затем была проведена проверка адекватности аппроксимации распределением Пуассона — были взяты случайные выборки по каждому из словарей в количестве 2000, эти выборки были проведены 10000 раз и для каждого раза вычислялся критерий согласия Пирсона. Количество успехов, где эмпирическое и теоретическое распределения совпадают, было равно 8441 для словаря Баара, 8508 — для словаря Дренясовой и 8426 — для словаря Миронова.
Таким образом, имеющиеся эмпирические распределения слов по длине могут быть описаны распределением Пуассона. Исходя из изложенного, можно выдвинуть гипотезу, что разница в длине случайно взятых слов должна описываться распределением Скеллама, которое выражает разницу между двумя распределениями Пуассона. Оно задается следующей функцией вероятности:
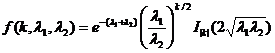 , где (2)
, где (2)
λ1, λ2 – параметры двух распределений Пуассона (1), а I|k| - модифицированная функция Бесселя первого рода (функция Инфельда).
Данная гипотеза была проверена методом Монте-Карло с использованием теста Пирсона, результаты представлены в таблице:
Таблица 1. Количество успешных выборок (p>0,05) при использовании метода Монте-Карло
Успехов из 10000 выборок | Дренясова | Баар | Миронов |
Дренясова | 8043 | 8042 | 8039 |
Баар | 8042 | 8040 | 7992 |
Миронов | 8039 | 7992 | 7980 |
Таким образом, на основании проведенного анализа построена математическая модель, выявляющая закономерность в распределении частот слов различной длины в зависимости от средней длины слова в анализируемых словарях посредством аппроксимации распределения Пуассона методом максимального правдоподобия. Верификация модели дала положительные результаты, равно как и верификация разности на основе распределения Скеллама, что говорит о правильности выдвинутой гипотезы.
Литература
Большой нидерландско-русский словарь: Ок. сл. и словосочетаний / , , и др.; под рук. . М., 2006.
Дренясова Т. Н., Миронов С. А. Карманный нидерландско-русский словарь. Около 7000 слов. М., 1977.
Baar A. H., van den. Groot Nederlands-Russisch Woordenboek / Большой голландско-русский словарь. Amsterdam, 2012.
Cullen A. C., Frey H. C. Probabilistic Techniques in Exposure Assessment: A Handbook for Dealing with Variability and Uncertainty in Models and Inputs/ Alison C. Cullen, H. Christopher Frey // Springer, 1999.
Hintze J. L., Nelson R. D. Violin Plots: A Box Plot-Density Trace Synergism / Jerry L. Hintze, Ray D. Nelson // The American Statistician. 1998. Vol. 52. P. 181-184.
