


УДК 004.7, 004.272.44
С. А. ЛАЗАРЕВ, А. В. ДЕМИДОВ, Р. В. ШАТЕЕВ
S. A. LAZAREV, A. V. DEMIDOV, R. V. SHATEEV
НЕКОТОРЫЕ АСПЕКТЫ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ МЕХАНИЗМОВ КОНТЕНТНОЙ ФИЛЬТРАЦИИ ТРАФИКА
SOME ASPECTS OF THE EFFECTIVENESS IMPROVE OF CONTENT-FILTERING SOFTWARE
В данной статье приводятся некоторые подходы к повышению эффективности контентной фильтрации и основных алгоритмов категоризации текста в интеллектуальном контент-анализе. Целью статьи является выбор наиболее эффективного способа обработки запросов в подсистеме контентной фильтрации.
Ключевые слова: фильтрация контента, категоризация текста, контент-анализ, машинное обучение, наивный байесовский классификатор.
The article suggests some approaches which are aimed at increasing efficiency of the content filtering and the main algorithms of the text categorizing in the intellectual content analysis. The purpose of article is the choice of the most effective method of request processing in a subsystem of the content filtering.
Keywords: content filtering, text categorizing, content analysis, machine learning, naive bayesian classifier.
Актуальность
В настоящее время, из-за бурного роста сети, любому пользователю Internet широко доступен огромный объём веб-контента [1]. В связи с этим фактом, можно предположить, что вместе с ростом всемирной сети увеличивается количество сайтов с нежелательным для пользователей содержимым. Зачастую, в средних и высших учебных учреждениях, возникает острая необходимость в контроле и управлении доступом к сетевым ресурсам [14]. Ярким примером может служить ограничение доступа студентов различных учебных заведений к материалам экстремистского или порнографического характера. Именно поэтому в последние годы, как в частном, так и корпоративном секторах, значительно возрастает спрос на продукты фильтрации, которые осуществляют управление доступом.
Если идёт речь о частном применении, то система фильтрации устанавливается на конкретный ПК. В случае применения в целях защиты корпоративной сети контент-фильтр нужно устанавливать на сервере-шлюзе, который пропускает через себя весь интернет-трафик [2].
В настоящее время возможно применение четырёх основных подходов к фильтрации веб-страниц: стандарты категоризации W3C (PICS/POWDER), URI-ориентированная база, на основе метода ключевых слов и интеллектуальный контент-анализ [3]. Проводя анализ сравнения коммерческих продуктов, которые решают описанные задачи, можно отметить, что все они используют метод анализа ключевых слов с динамической категоризацией, помимо URI-ориентированного метода ведения базы [4]. Интеллектуальный контент-анализ автоматически распределяет содержимое по категориям, и лишь после этого принимает решение на основе политики безопасности блокировать или передавать содержимое веб-ресурса пользователю. Метод анализа содержимого дополняет классический метод проверки по базе URI адресов для уменьшения накладных расходов связанных с обновлением URI списков и уменьшения числа ложных срабатываний по причине устаревания основной БД.
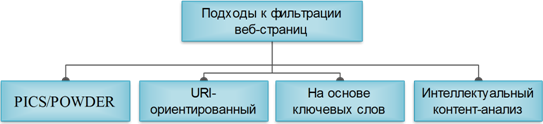
Рисунок 1 - Основные подходы к фильтрации веб-страниц
Высокоточные алгоритмы контент-анализа имеют весьма значительную сложность при реализации, кроме того, для их работы требуются существенные вычислительные мощности. Усложнения в модуле контентного анализа на стороне сервера приводят к замедленной выдаче веб-страниц пользователю, а так же ухудшают общую пропускную способность системы фильтрации. Исходя из этих особенностей в данной работе рассматриваются некоторые аспекты задачи повышения эффективности, и особое внимание уделяется способам категоризации текста. Подсистема динамической категоризации содержимого остается важнейшим подходом в комплексной системе фильтрации трафика.
Анализ подходов к контентной фильтрации
Понятие фильтрации содержимого можно толковать двумя способами. Первым вариантом может служить понимание контента всемирной сети Интернет в глобальном смысле. Во втором случае к контенту можно отнести содержание веб-страницы интернет-ресурса. Ниже будет подразумеваться толкование вторым способом.
Система контентной фильтрации может блокировать HTTP-запросы в соответствии с их URI-адресами, а также используя один или несколько подходов, описанных ниже. Блокирование на основе URI нуждается в ведении большой базы данных запрещенных адресов. Если к URI запроса найдено соответствие в базе данных, то запрос блокируется. База данных постоянно обновляется путем совместных усилий сообществ и полуавтоматических систем.
В работе [2] идёт речь о построении подсистемы фильтрации на основе URI блокировки, которая применяется в корпоративной сети ФБГОУ ВПО «Госуниверситет–УНПК» на протяжении года, но из-за быстро развивающейся сети Интернет база адресов быстро теряет актуальность, и вновь созданные ресурсы становятся доступны конечному пользователю. В связи с этим было принято решение об усовершенствовании данной подсистемы дополнительными методами.
Анализ веб-контента дополняет возможности URI-ориентированного подхода. Самым простым способом анализа содержимого страницы является работа со стандартами разработанными консорциумом W3C, а именно: Platform for Internet Content Selection (PICS) [5] и её более актуальная замена Protocol for Web Description Resources (POWDER) [6]. Идея данных спецификаций заключается в добровольной маркировке содержимого страницы создателями ресурсов. Но, к сожалению, в настоящее время нельзя полностью положиться на использование рекомендованных стандартов, именно потому, что их соблюдает крайне незначительное число разработчиков [7]. Следовательно, система фильтрации не может опираться на стандарты PICS или POWDER, чтобы на их основе чётко определить содержимое страницы.
Ещё одним подходом к определению категории содержимого является работа с ключевыми словами. При использовании данного варианта нужно тщательно подходить к отбору ключевых слов, поскольку для естественного языка значительными являются сопутствующие проблемы морфологического и контекстного характера, из-за которых возможно возникновение большого количества ложных срабатываний. Некорректное определение может произойти из-за двусмысленности слов, присущей естественному языку.
Наиболее сложным, из вышеописанных, является интеллектуальный контентный анализ, основывающийся, как правило, на методах машинного обучения. Эти методы делают упор на поиск ярко выраженных особенностей в содержимом страницы (метаинформация, ключевые слова, ссылки, изображения и т. п.), которые могут сказать о её принадлежности к какой-либо категории [8]. Первым этапом машинного обучения является «тренировка» на заранее подготовленных страницах, которые можно без сомнений отнести к запрещённой или разрешённой категории. После обучения категоризатор может определять содержимое в соответствии с заданными функциями. На практике большинство обучаемых функций предназначены для обработки текста, потому что категоризация такого вида информации является более эффективной, чем анализ изображения.
Поскольку было сказано, что механизм описанный последним является наиболее сложным, то возникает явная потребность в облегчении подхода при реализации на конкретном аппаратном комплексе. В связи с этим по результатам анализа алгоритмов категоризации текста планируется вариант реализации алгоритма раннего принятия решения, который способен в значительной степени увеличить скорость обработки веб-страниц при обслуживании сотен или тысяч пользователей.
Анализ алгоритмов категоризации текста
Категоризация текстов - важная часть в веб-фильтрации, потому что именно текст в содержимом страниц обеспечивает максимальное количество возможностей для его обработки.
В настоящее время разработано множество алгоритмов для категоризации текста с высокой точностью. Их основным предназначением является работа на рабочих станциях. Исследования по этим алгоритмам в основном делают упор на точности категоризации, при этом их общая скорость выполнения не всегда рассматривается как важный критерий. В текущую задачу входит оценка эффективности рассматриваемых алгоритмов, с точки зрения, как скорости выполнения, так и точности определения категорий, для построения контент-анализатора, который не будет вызывать значительного замедления системы в целом.
Под эффективностью работы алгоритма будем понимать комбинацию точности категоризации информации, а так же непосредственную скорость выполнения алгоритма.
В работах [9], [10] проводится рассмотрение и всестороннее сравнение существующих алгоритмов категоризации текстов, таких как: метод опорных векторов, метод k ближайших соседей, искусственная нейронная сеть, дерево принятия решений и наивный байесовский классификатор (Рис. 2).
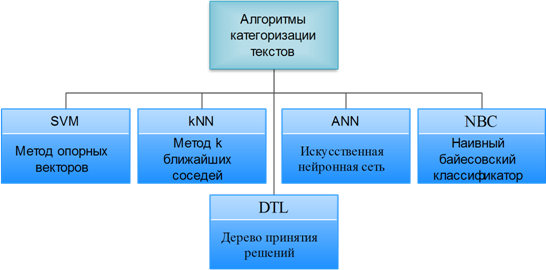
Рисунок 2 - Алгоритмы категоризации текстов
Метод опорных векторов (англ. Support Vector Machine, SVM) использует процесс поиска плоскости решения, которая может разделить положительные и отрицательные примеры в многомерном пространстве функции, в котором учебные документы представлены как векторы. SVM, разработанный Владимиром Вапником в 1995 году, был впервые применен к задаче классификации текстов Торстеном Джохимсом (Thorsten Joachims) в 1998 году. В своем первоначальном виде алгоритм решал задачу различения объектов двух классов. Метод приобрел огромную популярность благодаря своей высокой эффективности. Многие исследователи использовали его в своих работах, посвященных классификации текстов. Подход, предложенный Вапником для определения того, к какому из двух заранее определенных классов должен принадлежать анализируемый образец, основан на принципе структурной минимизации риска. Вероятность ошибки при классификации оценивается, как непрерывная убывающая функция, от расстояния между вектором и разделяющей плоскостью. Она равна 0,5 в нуле и стремится к 0 на бесконечности.
Результаты классификации текстов с помощью метода опорных векторов, являются одними из лучших, по сравнению с остальными методами машинного обучения [16]. Однако, скорость обучения данного алгоритма одна из самых низких. Метод опорных векторов требует большого объема памяти и значительных затрат машинного времени на обучение, что снижает его масштабируемость. Тем не менее, данный алгоритм можно использовать в качестве эталона с точки зрения качества классификации [8]. То есть метод будет работать эффективно, если опорных векторов будет сравнительно не много, если же их количество возрастает метод становится малоэффективен из-за значительно увеличивающейся сложности.
Метод k ближайших соседей (англ. k-nearest Neighbor Algorithm, kNN) является одним из самых изученных и высокоточных алгоритмов, используемых при создании автоматических классификаторов. Впервые он был предложен еще в 1952 году для решения задач дискриминантного анализа. В исследованиях, посвященных анализу работы различных алгоритмов машинного обучения для задачи классификации текстов, этот метод демонстрирует одни из наилучших результатов [10].
В основе метода лежит очень простая идея: находить в отрубрицированной коллекции самые похожие на анализируемый текст документы и на основе знаний об их категориальной принадлежности классифицировать неизвестный документ.
Решение об отнесении документа к тому или иному классу принимается на основе анализа информации о принадлежности k его ближайших соседей. Например, коэффициент соответствия рубрики анализируемому документу, можно выяснить путем сложения для этой рубрики значений.
При монотематической категоризации выбирается рубрика с максимальным значением. Если же документ может быть приписан к нескольким рубрикам (случай мультитематической категоризации), классы считаются соответствующими, если значение превосходит некоторый, заранее заданный порог.
Главной особенностью, выделяющей метод kNN среди остальных, является отсутствие у этого алгоритма стадии обучения. Иными словами, принадлежность документа рубрикам определяется без построения классифицирующей функции.
Основным преимуществом такого подхода является возможность обновлять обучающую выборку без переобучения классификатора. Это свойство может быть полезно, например, в случаях, когда обучающая коллекция часто пополняется новыми документами, а переобучение занимает слишком много времени.
Классический алгоритм предлагает сравнивать анализируемый документ со всеми документами из обучающей выборки и поэтому главный недостаток метода kNN заключается в длительности времени работы рубрикатора на этапе классификации [9].
Искусственная нейронная сеть (англ. Artificial Neural Network, ANN) широко изучается в области искусственного интеллекта для анализа данных с 1986 года. ANN представляет из себя математическую модель, а также ее программные или аппаратные реализации, построенные по образу и подобию сетей нервных клеток живого организма. Нейронные сети - один из наиболее известных и старых методов машинного обучения.
ANN - адаптивная система, которая состоит из группы соединенных искусственных нейронов. Система может быть обучена для изменения её внутренних состояний, отражения связей документов и их категорий.
Для эффективного проведения категоризации текста необходимо определить рациональную структуру и топологию нейронной сети. Основными топологиями классифицирующих нейронных сетей являются одно - и многослойный персептрон, нейросетевой Гауссов классификатор, сеть Кохонена, сеть встречного распространения, прямоточная и каскадная сети [17]. Все вышеуказанные топологии имеют высокую точность в обработке одновременно линейных и нелинейных примеров, но принятие решений по классификации трудно формализуемы в силу природы организации нейронной сети и представляют не тривиальную задачу с учётом масштабируемости с ограниченными вычислительными ресурсами.
Дерево принятия решений (англ. Decision Tree Learning, DTL) представляет собой структуру организованную следующим образом: внутренними узлами являются проверки атрибута, а ветвями являются варианты результатов проверки. Документ классифицируется проходом от корневой вершины по множеству внутренних узлов в соответствующих вариантах, основанных на результатах проверки атрибутов, пока не достигнуты листы дерева.
В отличие от остальных, рассматриваемых в данной работе подходов, деревья принятия решений относятся к символьным (т. е. не числовым) алгоритмам, преимущество которых заключается в относительной простоте интерпретации человеком правил отнесения документов к категории. Они хорошо приспособлены для графического отображения, и поэтому сделанные на их основе выводы гораздо легче интерпретировать, чем, если бы они были представлены только в числовой форме.
При рассмотрении области применения данного подхода к автоматической классификации текста получаем, что внутренние узлы представляют собой термы, ветви, отходящие от них, характеризующие вес терма в анализируемом документе, а листья - категории. Такой категоризатор обрабатывает испытываемый документ, рекурсивно проверяя веса вектора признаков по отношению к порогам, выставленным для каждого из весов, пока не достигнет листа дерева (категории). К этой категории (листа которой достиг классификатор) и приписывается анализируемый документ.
Полученное Решение просто интерпретируемо, но требует точного выбора атрибутов для предупреждения ситуации с переобучением, т. е. при построении алгоритма обучения получается такой алгоритм, который слишком хорошо работает на примерах, участвовавших в обучении, но достаточно плохо работает на примерах, не участвовавших в обучении (из тестовой выборки). Это связано с тем, что в процессе обучения в обучающей выборке обнаруживаются некоторые случайные закономерности, которые отсутствуют в генеральной совокупности [15].
Наивный байесовский классификатор (англ. Naive Bayes Classifier, NBC) специальный частный случай байесовского классификатора, основанный на дополнительном предположении, что объекты x∊X описываются n статистически независимыми признаками:
|
Предположение о независимости означает, что функции правдоподобия классов представимы в виде
|
где ![]() - плотность распределения значений j-го признака для класса y.
- плотность распределения значений j-го признака для класса y.
Предположение о независимости существенно упрощает задачу, так как оценить n одномерных плотностей гораздо легче, чем одну n-мерную плотность. К сожалению, оно крайне редко выполняется на практике, отсюда и название метода.
Наивный байесовский классификатор может быть как параметрическим, так и непараметрическим, в зависимости от того, каким методом восстанавливаются одномерные плотности. Он использует вероятностную модель, в которой классификация и включения в соответствующую категорию документов проводится путем оценивания вероятности появления слов в документе. Вероятности могут быть использованы для оценки наиболее близких категорий тестового документа [18].
Основные преимущества наивного байесовского классификатора - простота реализации и низкие вычислительные затраты при обучении и классификации. В тех редких случаях, когда признаки действительно независимы (или почти независимы), наивный байесовский классификатор (почти) оптимален.
Основной недостаток NBC - относительно невысокое качество классификации в большинстве реальных задач.
В некоторых исследованиях предпринимаются попытки использовать структурную информацию - гиперссылки и метаинформацию для улучшения точности [11], [12]. Эти методы требуют синтаксического разбора (парсинга) веб-контента для извлечения семантической информации. Этот вариант обработки страниц выходит за рамки данной работы, т. к. синтаксический разбор требует значительно больших затрат времени чем использование рассматриваемой модели анализа текста как последовательности слов и может быть не так эффективен для фильтрации в реальном времени.
Одним из возможных вариантов повышения скорости обработки контентной фильтрации при сохранении допустимой точности, является разработка метода, который можно назвать алгоритмом раннего принятия решения. Он основан на предположении, что существует возможность принятия решения о выборе категории до полной обработки всего содержимого страницы. Быстрое решение особенно важно, так как большая часть страниц относится к разрешённой категории и должна пройти фильтр с максимальной скоростью.
Ключевая идея алгоритма раннего принятия решения, ускоряющего контентную фильтрацию, состоит в возможности принятия решения о фильтрации до полного сканирования содержимого страницы, как только категория содержимого достоверно (с высокой вероятностью) определена. Быстрое принятие решений особенно важно для фильтрации в реальном времени, т. к. наибольшая часть веб-контента разрешена и должна пройти фильтр как можно быстрей.
Среди вышеупомянутых алгоритмов целесообразно остановить выбор на наивном байесовском классификаторе для использования в качестве основания для алгоритма раннего принятия решения, т. к. его вычисление может быть представлено как подбор подходящей категории в процессе анализа документа. Таким образом, появляется возможность избежать анализа всего документа. Вероятность того, что проверяемый документ принадлежит к одной или нескольким категориям может быть оценена путём проверки документа категоризатором. Однако есть основание полагать, что наивный байесовский классификатор может оказаться эффективным, т. е. достаточно точным и быстрым, даже по части веб-страницы.
Заключение
В работе был произведён анализ наиболее распространённых текстовых классификаторов, который позволяет, на основе выявленных положительных и отрицательных сторон, сделать выбор в пользу наивного байесовского классификатора. Основой выбора послужили простота реализации и высокая скорость работы при удовлетворительной точности, что даёт возможность использовать его в дальнейших исследованиях. Перспективным направлением, на основе NBC, является разработка алгоритма раннего принятия решения, который позволит сократить время обработки запросов к подсистеме фильтрации до минимума.
СПИСОК ЛИТЕРАТУРЫ
1. Internet 2012 in numbers [Электронный ресурс] - Режим доступа: http://royal. /2013/01/16/internet-2012-in-numbers/, свободный – Яз. англ.
2. , , Построение подсистемы контентной фильтрации интернет-трафика на базе свободного программного обеспечения [Электронный ресурс] / Информационные ресурсы, системы и технологии - Режим доступа: http://*****/article124, свободный – Яз. рус.
3. Neural networks for Web content filtering [Текст] / P. Y. Lee, S. C. Hui, and A. C. Fong // IEEE Intelligent Systems, vol. 17, no. 5, Sept.-Oct., 2002. c. 48-57.
4. Internet Filter Software Review 2013 [Электронный ресурс] - Режим доступа: http://internet-filter-review. , свободный – Яз. англ.
5. Platform for Internet Content Selection (PICS) [Электронный ресурс] - Режим доступа: http://www. w3.org/PICS/, свободный – Яз. англ.
6. Protocol for Web Description Resources (POWDER): Description Resources [Электронный ресурс] - Режим доступа: http://www. w3.org/TR/powder-dr/, свободный – Яз. англ.
7. Что сказал Льюис Кэрролл о проблемах «семантической паутины»? / МОО «Информация для всех» [Электронный ресурс] - Режим доступа: http://www. *****/pr/2008/080723a. htm, свободный – Яз. рус.
8. WebGuard: A Web filtering engine combining textual, structural and visual content-based analysis [Текст] / M. Hamammi, Y. Chahir, and L. Chen // IEEE Trans. Knowl. Data Eng., vol. 18, no. 2, Feb. 2006. c. 272-284.
9. A re-examination of text categorization methods [Текст] / Y. Yang and X. Liu // Proc. SIGIR’99, 22nd ACM International Conference on Research and Development in Information Retrieval, 1999. c.42-49.
10. Machine learning in automated text categorization [Текст] / F. Sebastiani // ACM Comput. Surv., vol. 34, no. 1, March 2002. c. 1-47.
11. Using Web structure for classifying and describing Web pages [Текст] / E. J. Glover, K. Tsioutsiouliklis, S. Lawrence, D. M. Pennock, and G. W. Flake // Proc. World Wide Web (WWW), 2002. c. 562-569.
12. Automatic Web page categorization by link and context analysis [Текст] / G. Attardi, A. Gulli, and F. Sebastiani // Proc. THAI-99, First European Symp. Telematics, Hypermedia, and Artificial Intelligence, 1999. c. 105-119.
13. Machine learning [Текст] / T. Mitchell // McGraw Hill, 1996.
14. Лазарев, технологии обратного проксирования в рамках системы управления информационным обменом сети корпоративных порталов [Текст] / , // Информационные системы и технологии. – Орел: Госуниверситет - УНПК, 2011. – № 6 (68) ноябрь-декабрь. – С. 129-134.
15. Overfitting [Электронный ресурс] / Wikipedia, the free encyclopedia - Режим доступа: http://en. wikipedia. org/wiki/Overfitting, свободный – Яз. англ.
16. Chakrabarti S. Mining The Web Discovering Knowledge From Hypertext Data [Текст] / S. Chakrabarti ; Morgan Kaufmann Publishers, 2004.
17. Лорьер, Ж.-Л. Системы искусственного интеллекта [Текст] / Ж.-Л. Лорьер ; пер. с фр. . - М. : Мир, 1с.
18. Прикладная статистика: классификация и снижение размерности [Текст] / , , - М.: Финансы и статистика, 1989.
Сведения об авторах
, НИУ «БелГУ», кандидат экономических наук, 5, e-mail: *****@.
Lazarev Sergey Aleksandrovich, National Research University «Belgorod State University», Belgorod, Pobedy Street 85, e-mail: *****@.
, ФГБОУ ВПО «Государственный университет – УНПК», начальник технического отдела, г. Орел, Наугорское шоссе, 40, , e-mail: a. *****@***ru.
Demidov Alexandr Vladimirovich, State University - ESPC, Head of Technical Department, Orel, Naugorskoe Highway 40, tel.: (48, e-mail: a. *****@***ru.
; ФГБОУ ВПО «Государственный университет – УНПК», магистрант кафедры "Информационные системы", г. Орел, Наугорское шоссе, 29, , e-mail: *****@***ru.
Shateev Roman Valerievich; State University - ESPC, Master’s Degree Student of Department "Informational Systems", Orel, Naugorskoe Highway 29, tel.: (48, e-mail: *****@***ru.
