


Инженерия справочных данных ISO 15926
TechInvestLab
Версия 2.0
25 февраля 2011г.
О стандарте ISO 15926
В этом тексте крайне неформально описан метод инженерии справочных данных ISO 15926. Этот метод используется для поддержки интеграции данных различных компьютерных приложений (САПР, PLM, ERP, EAM и т. д.) в соответствии со стандартом ISO 15926. Cтандарт регламентирует передачу данных инженерного проекта и промышленных каталогов между хранилищами информации компьютерных приложений по принципу «все-со-всеми», и предназначен для применения на протяжении всего жизненного цикла инженерного проекта.
Использование этого стандарта для передачи данных из хранилища в хранилище иногда называют «ISO 15926 outside».
Использование стандарта в самих хранилищах данных компьютерных приложений – «ISO 15926 inside» – пока нигде не реализовано, то есть форматы данных в хранилищах вовсе не соответствуют ISO 15926 (хотя на такое соответствие и намекают многие поставщики PLM – пока это не так). Но данные в различных хранилищах не соответствуют и никакому иному единому стандарту.
Задача интеграции данных встаёт в тот момент, когда какие-то данные требуются прикладной программе, не приспособленной для работы с «посторонним» для неё хранилищем. Так, ERP-системе очень непросто получить доступ к данным PLM-системы, и наоборот. Схемы баз данных разных приложений не соответствуют друг другу: что является «атрибутом» для одного хранилища - может быть «объектом» другого, что представлено текстовой строкой в одной схеме данных – может оказаться группой текстовых и числовых полей в другой. Но потребность в передаче данных между разными хранилищами становится всё больше, ибо повторный ручной ввод данных из приложения в приложение пожирает дорогое время квалифицированных сотрудников, является источником ошибок, а количество таких перенабивок в большом строительном проекте может приближаться к десятку!
Инженерия справочных данных для “ISO 15926 outside” является одной из дисциплин работы с нормативно-справочной информацией (НСИ, основными данными, master data) в рамках работы по поднятию качества данных и обеспечению управления основными данными. Принципиальное отличие этой технологии от бытующих сегодня технологий управления корпоративной НСИ (enterprise MDM, master data management) в том, что стандарт ISO 15926 изначально предполагает использование справочных данных в независимых друг от друга организациях (а не просто декларирует «пересечение справочными данными границ организации» с последующим обсуждением проблем только одной организации). Согласно этому стандарту доступ к НСИ осуществляется в едином формате, а сами НСИ содержатся в совокупности («федерации») административно независимых библиотек справочных данных. Поэтому технология ISO 15926 пригодна для интеграции данных не только в масштабах крупной инжиниринговой компании или холдинга, но и для интеграции данных в масштабах отрасли или даже крупного межотраслевого проекта.
Инженерия справочных данных в варианте «ISO 15926 outside» также отличается от традиционных для проектных организаций попыток внедрить стандарты обмена данными семейства STEP (даже в современных вариантах PLCS – AP239, или будущий AP242): в стандарте ISO 15926 речь идет о данных всего жизненного цикла, в том числе и о стадии эксплуатации. За счет особенностей представления времени (используется парадигма «4D пространства-времени»), ISO 15926 позволяет компактно описывать не только «проектно-конструкторские данные», но и данные, необходимые для управления непрерывно меняющейся конфигурацией уже эксплуатирующихся изделий и установок (передача информация о том, например, как меняются запчасти на работающей установке). Кроме того, ISO 15926 не ограничивается одной инженерной специальностью, а принципиально расширяем (в этом смысле его нужно сравнивать не столько с каким-то одним прикладным протоколом STEP, сколько с семейством этих стандартов в целом).
Дальнейшее чтение предполагает хотя бы поверхностное знакомство с частями 1, 2, 4, 6, 7 и 8 стандарта (три последние пока существуют только в виде проектов на согласовании в ISO), а также знание базовых терминов системной иненерии (в варианте ISO 15288: целевая система, жизненный цикл, практики и т. д.).
В соответствии со стандартами описания метода (в данном тексте использован ISO 24744), в данном тексте описаны:
· участвующие рабочие продукты
· стадии жизненного цикла целевой системы (справочных данных);
· практики, выполняемые на протяжении жизненного цикла;
· организация (профессиональные роли и используемые ими инструменты);
· используемые языки/нотации моделирования данных.
В текущей версии метода описаны действия пока только для одной профессиональной роли: «инженер справочных данных», часто также называемый «модельер данных». Кроме того, упомянуто участие «тестировщика моделей» и «администратора проектных данных».
Информация, данные, информационные объекты
Инженерия справочных данных имеет дело с тремя разными типами сущностей:
1. Информация – это факты, сведения, приказы, требования, мнения. Обсуждение информации затрагивает содержательные вопросы – значение информации в контексте ее использования («смысл»). Что эта информация означает для нашего проекта, что из этой информации следует? В чем смысл именно такой информации, а не другой? Какой ситуации в реальном мире соответствует эта информация?
Содержательное рассмотрение обычно никак не связано с обсуждением способа записи, соглашениями об именах, синтаксисом, особенностями представления информации на носителе. Это именно содержание, а не форма. Информация о том, что 2*2=4 обсуждается содержательно (что это именно 4, не 3 и не 7), а не с точки зрения ее представления (например, использованной системы счисления для записи цифр), или на каком носителе она записана.
Информация абстрактна, т. е. не существует в материальном мире – но она может выражать знания об объектах реального мира. Информация инженерного проекта – это то, что содержательно известно о проекте, независимо от того, как оно представлено, закодировано, в каком формате хранится.
Информацию производят и используют участники инженерного проекта – строители, теплотехники, менеджеры.
2. Данные – это представление информации с использованием какого-то формализма. Например, при обсуждении данных 2*2=4 можно обсуждать формализм – арабские цифры или римские.
Данные абстрактны, т. е. не существуют в материальном мире. Действительно, одни и те же данные (например, текстовая строка «труба» в кодировке UNICODE или даже большая база данных со сложной схемой) могут быть представлены на самых разных экземплярах носителя, в том числе и резервных (бэкапы). На всех этих экземплярах носителей данные остаются одними и теми же, и обсуждаются именно как данные.
Данными занимаются инженеры справочных данных (они же модельеры данных), другие модельеры, программисты, администраторы данных. Администраторы данных следят за тем, чтобы данные были непротиворечивы, а содержащаяся в них информация соответствовала принятому формализму.
3. Информационные объекты – это газеты, журналы, документы (бумажные и даже электронные – файлы), хранилища данных на компьютерах (предназначенные для хранения данных в структурированном виде, без повторений и с возможностью однозначного нахождения нужных данных) и любые другие физические объекты, содержащие данные. На разных информационных объектах/носителях информации (например, в газете и в хранилище данных) могут находиться одни и те же данные (например, текстовая строка «труба»).
Данные не живут без носителя. Так, «файл» – это обычно маленькие магнитные частички, специальным образом ориентированные, расположенные во множестве разных мест диска из немагнитного материала. Данные из файла могут затем попасть в оперативную память – и стать там уже не магнитными частичками с разной ориентацией в пространстве, а участками полупроводниковой микросхемы с разными напряжениями.
Информационными объектами занимаются системные администраторы, которые следят не за непротиворечивостью записанных на них данных, а за их сохранностью на носителях (бэкапы), и за неискажением при переносе с носителя на носитель.
Справочные данные
Справочные данные (reference data) – это такие данные, которые используются в нескольких проектах, на нескольких стадиях жизненного цикла и/или интересуют множество пользователей. Классификатор ОКПО, каталог промышленной продукции или каталог методов, налоговые ставки, схема данных какой-то геоинформационной системы, «схема данных» для представления 3D моделей строительных конструкций или промышленного оборудования – это всё справочные данные.
От часто используемого в корпоративной автоматизации понятия нормативно-справочной информации (НСИ) справочные данные отличаются тем, что они – данные, а не информация, то есть при работе с ними принципиально важна формальная система их записи. Кроме того, справочные данные включают не только «данные для конечного потребления», то есть заполненные формы (например, каталоги), но и «данные, описывающие структуру и значение других данных», то есть «пустографки», формы для заполнения.
Умение разговаривать на языке баз данных тут не понадобится: традиционного разделения между «схемой базы данных» и «данными в базе данных» в ISO 15926 нет (то есть нет жёсткого разделения на «пустографку» и «содержимое», зато есть формализация «пустографок для занесения туда пустографок в качестве содержимого», и так на много уровней в глубину, но в рамках одного формализма). То, что можно было бы назвать «схемой данных», в ISO 15926 попадает в справочные данные, а определяемые «схемой» данные в свою очередь могут оказаться «схемой» ещё для каких-то «данных», то есть тоже справочными данными. Чтобы не путаться, забываем пока о базах данных, но нам придётся вспомнить о них при рассказе о применении ISO 15926 к данных конкретных хранилищ.
Виды справочных данных.
Справочные данные, создаваемые согласно ISO 15926, состоят из единиц справочных данных (reference data items). Такими единицами справочных данных являются:
· Классы индивидов (class of individuals), классы отношений (class of relationships) и классы классов (class of class), используемые для разделения и группировки индивидов. Ни в коем случае не путайте эти классы с классами из объектно-ориентированного программирования: тут классы из теории множеств, у них нет «методов», никакой речи не ведется об «объектах» и т. д. Об объектно-ориентированном программировании придется забыть так же, как про схемы баз данных. Теория множеств тут тоже неклассическая (non well founded sets, «нефундированные множества»), но это не должно смущать.
· Отдельные индивиды (individuals), при этом в ISO 15926 к индивидам относится только то, что имеет протяжённость в пространстве и/или во времени, и в справочные данные попадают только те индивиды, которые будут использованы во многих проектах, например, «Москва» или «Ростехнадзор». Тут надо помнить, что в соответствии с онтологической сущностью ISO 15926 под «Москвой» понимается реальный физический город, и под «Ростехнадзором» - совокупность конкретных людей, территорий, документов, компьютеров.
· Шаблоны (templates), которые используются для формирования утверждений о единицах данных. Проще всего представлять их как заготовленные для заполнения «пустографки» в виде таблиц, заголовки столбцов в которых называются «ролями шаблона» (template roles). «Ролями» их называют потому, что они определяют роль для заполняющих их значений. Так, «Труба Т123» в одном шаблоне (определяемом этим шаблоном таблице) может стоять в роли (находиться в столбце) «предмет снабжения», а в другом шаблоне та же «Труба Т123» может стоять в роли (столбце) «место протекания потока».
· Экземпляры шаблонов (template instances), то есть заполненные строчки в таблицах-пустографках, содержащие (в данном случае инженерии справочных данных) утверждения о прочих единицах справочных данных.
Шаблоны совершенно не случайно сравниваются с таблицами: любимым инструментом инженеров справочных данных является Excel, поэтому чаще всего с шаблонами и их заполнением работают именно в табличном формате, и используют для этого Excel.
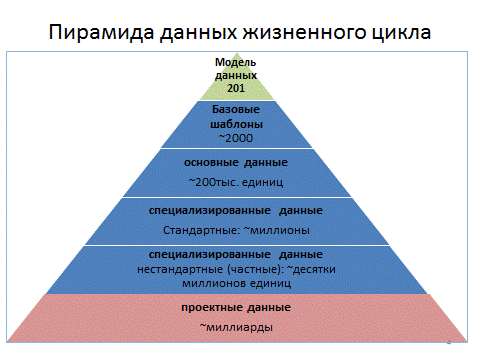
По степени общности отражаемой информации окружающего мира среди справочных данных выделяется несколько категорий, составляющих пирамиду:
· «Модель данных» – это 201 тип Части 2 ISO 15926, которые также продублированы в виде классов справочных данных;
· Основные классы (core classes) – те, которые отражают разделения индивидов и отношений в соответствии с общеупотребимыми словами из обычных языков. Среди них можно найти, например: «насос», «газету», «давление», «поток», «сварку», «выше» и «ниже».
· Стандартные классы (standard classes) – те, правила отнесения к которым определяются открытыми стандартами, контролируемыми какими-либо организациями по стандартизации (ISO, национальными, как Ростехрегулирование, или профильными ассоциациями).
· Специализированные классы – сюда входят классы де-факто, классы производителей, частные (proprietary) классы и прочие, в особенности определений которых мы пока не будем углубляться. Эти классы могут быть получены из анализа специальных учебников, стандартов предприятий, а то и из спецификаций отдельных проектов.
· Протошаблоны (proto templates) – предикаты, описывающие на языке логики 201 тип «модели данных» Части 2 ISO 15926.
· Базовые шаблоны (base templates) – те, с помощью которых можно сформировать утверждения о любых данных, ограниченные только отнесением всего и вся к 201 типу «модели данных» Части 2 ISO 15926. Эти шаблоны позволяют формировать любые утверждения об абстрактных и конкретных сущностях в мире и их связях, требуя только лишь связывать их с такими общими типами, как «физический объект», или «григорианские дата и время», или «класс классов» и т. д. Вот страничка, на которой собирается список общеупотребительных базовых шаблонов: https://www. posccaesar. org/wiki/SigMmt/Templates.
· Основные шаблоны (core templates) – те, с помощью которых можно формировать утверждения о связях данных с основными классами. Основные шаблоны позволяют формировать утверждения о том, как связаны описываемые вами сущности с понятиями, выразимыми в словах из общеупотребимых толковых словарей. Основные шаблоны определяются через указание ограничений на те данные, которые могут занимать роли в базовых шаблонах. Вообще-то, те же самые утверждения можно сформировать и с помощью базовых шаблонов, но базовый шаблон нужно подбирать по ситуации, а конструкция основного шаблона уже для неё «приспособлена».
· Специализированные шаблоны (specialized templates) – те, с помощью которых можно формировать ещё более специальные утверждения, устанавливая связи данных со специальными классами и даже с конкретными индивидами. Использование специализированных шаблонов может быть ограничено, например, рамками отрасли, а то и одной организации. Специализированные шаблоны получаются из базовых и основных шаблонов еще бОльшими ограничениями на заполнение ролей. Считается, что для специалиста в какой-то предметной области легче сориентироваться в большом наборе очень конкретных специализированных шаблонов, чем стараться сформировать необходимые ему утверждения из небольшого количества очень общих конструкций (то есть легче записать «из крана течёт вода», чем сформировать целую совокупность записей типа «арматура присоединена к трубопроводу, арматура имеет ручной привод, трубопровод содержит поток, темпоральная часть потока состоит из жидкой фазы вещества H2O, …»).
Проектные данные
Справочные данные используются для того, чтобы задать форму для понимаемых всеми компьютерными приложениями данных о том инженерном проекте, которым вы занимаетесь. Инженерные проекты могут быть самыми разными: и инжиниринговый проект строительства завода, и проект создания каталога выпускаемой заводом продукции, и даже проект преобразования завода как организации (реинжиниринг бизнес-процессов). Данные проекта на едином для всех компьютерных приложений языке стандарта ISO 15926 формируются одинаково – как экземпляры тех или иных шаблонов (т. е. как строчки значений в табличках, колонки-роли в которых задаются шаблонами).
Получается, что все данные на каждой стадии инженерного проекта могут быть поделены на справочные данные (задающие формализм/формат) и проектные данные (задающие содержание).
Например, на стадии проектирования справочные данные содержат информацию о том, что бывают «трубы с номинальным диаметром 100мм», «трубы с номинальным диаметром 200мм» (скорее всего, это стандартные классы, определяемые по ГОСТу). Среди справочных данных есть шаблон, позволяющий «отнести объект А к категории Б» (это – базовый шаблон). Из них могут быть созданы специализированные шаблоны классификации труб, и с их помощью в проектных данных формируется набор утверждений (экземпляров специализированных шаблонов) о том, что «объект Т123 относится к трубам с номинальным диаметром 100мм», «объект Т567 относится к трубам с номинальным диаметром 200мм» и т. п.
При этом само утверждение «бывают трубы с номинальным диаметром 100мм» было проектными данными для того, кто составлял каталог труб (целевая система другого инженерного проекта!), а справочные данные для него включали основной класс «труба».
Легко также представить себе ситуацию, когда ваши проектные данные с кодами труб на чертеже окажутся справочными данными для кого-то на следующих стадиях жизненного цикла (на стадии эксплуатации, например, когда проектными данными будут серийные номера заменяемых при ремонтах единиц оборудования, а код трубы на чертеже остаётся «справочным» и не будет меняться).
Теперь мы можем уточнить приведённое выше определение справочных данных, которые используются «на нескольких стадиях жизненного цикла и/или интересуют множество пользователей». До тех пор, пока проектные данные находятся в руках их создателя (создателя соответствующей информации), они могут изменяться, уточняться, пересматриваться, и предаваться иному лицу для использования. Однако в тот момент, когда кто-то не просто воспользовался этими данными, а использовал их именно для описания своих данных (обычно это делается при переходе к следующей стадии жизненного цикла или хотя бы к иному этапу стадии) – они стали справочными данными, которые уже не могут быть так просто пересмотрены или изменены без угрозы для целостности данных проекта.
Можно сказать, что справочные данные описывают мир на уровне «как вообще бывает», а проектные данные – «как есть конкретно в нашем проекте на текущей стадии жизненного цикла». Но всё-таки строгое логическое разделение данных на справочные и проектные в пограничных случаях затруднительно, и поэтому так много внимания уделяется управлению наборами справочных данных для обеспечения использования их при интеграции данных.
Инженерия данных жизненного цикла
Данные жизненного цикла инженерного объекта (атомной станции, подводной лодки, кузнечного пресса) – это все данные, которые появляются и используются в любой момент этого жизненного цикла, от замысла до вывода из эксплуатации. Данные жизненного цикла в инженерии справочных данных ISO 15926 считают единым целым, и включают «модель данных» (201 тип данных Части 2 стандарта), общие для многих проектов справочные данные, и проектные данные (которые тоже могут стать справочными на протяжении их собственного жизненного цикла).
Как уже упоминалось, «классы», «шаблоны», «индивиды», из которых составлены справочные данные, именуют для краткости «единицами справочных данных» (reference data item). Единицы справочных данных определяются с использованием друг друга, и представляют собой «пирамиду справочных данных», которая при добавлении проектных данных становится «пирамидой данных жизненного цикла» - верх которой находится на «философском уровне общности», а низ содержит утверждения о конкретных свойствах конкретных индивидов в отдельных проектах.
Общее понятие «инженерии данных» означает ход превращения информации в данные в соответствии с каким-то формализмом. «Инженерия справочных данных ISO 15926» - это оформление информации в виде данных в соответствии с формализмом, предписанным «моделью данных» Части 2 стандарта по правилам, описанным в прочих его частях.
В конкретном проекте инженерия справочных данных состоит в разработке шаблонов-«пустографок» и нужных для их специализации классов, то есть к созданию данных, описывающих структуры и значения других данных (проектных, или, возможно, очередного уровня справочных данных).
Инженерия самих проектных данных – это уже принятие профессиональных проектных решений (определение параметров потоков, геометрии трубопроводов, состава оборудования и т. д.). Иногда инженерия проектных данных – это превращение в данные информации о чужих проектных решениях. У проектных данных другой жизненный цикл, и в него вовлечены другие профессиональные роли (инженеры-конструкторы, каталогизаторы и т. д.).
Однако при интеграции данных жизненные циклы справочных и проектных данных пересекаются, поэтому ниже по необходимости будет рассказано и о практиках жизненного цикла проектных данных.
Библиотеки справочных данных
Справочные данные разрабатываются самыми разными организациями, и административно контролируемые этими организациями совокупности справочных данных называются библиотеками справочных данных (БСД, или RDL, reference data library). Библиотеки справочных данных ссылаются друг на друга, одни из них используют определенные в других более общие классы, шаблоны или даже индивиды для определения собственных менее общих классов, шаблонов и индивидов. Однако теоретически любая библиотека может содержать даже основные классы и базовые шаблоны – если они никому больше не понадобились, или если владельцы библиотеки просто не нашли их в других доступных им библиотеках.
Библиотеки справочных данных могут быть:
· международные (подробнее о состоянии дел с ними – чуть ниже);
· национального уровня (например, специализирующиеся на классах и шаблонах, извлечённых из стандартов одной страны, ГОСТ-Р или DIN);
· отраслевого уровня (отрасль тут – это вовсе не "министерство", речь может идти о какой-то отраслевой ассоциации или даже о большом холдинге), и в России есть как минимум две отрасли, которые полным ходом разрабатывают свои библиотеки справочных данных – атомная и судостроительная;
· уровня предприятия;
· уровня отдельного проекта (зато, возможно, объединяющего несколько предприятий, и даже в разных отраслях).
Библиотеки справочных данных могут (а в идеале – в максимальной степени должны) ссылаться друг на друга, и в совокупности образуют "федерацию" библиотек (помним, что каждая из этих библиотек – под независимым администрированием!).
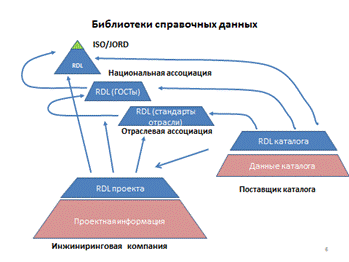
Библиотека справочных данных содержит «зарегистрированные» данные. Поскольку «справочники» предполагают коллективную разработку группой авторов и некоторый уровень проверки, данные туда попадают не автоматически, а только после формального утверждения. Публичные (международные и национальные) БСД должны в идеале иметь объявленную процедуру, по которой любое заинтересованное лицо может предложить пополнение или изменение содержащихся в них справочных данных.
Поэтому при библиотеке справочных данных полезно иметь «песочницу» (sandbox), где можно потренироваться в создании справочных данных, т. е. выполнить все процедуры работы с ними, кроме формального утверждения.
Библиотеки справочных данных поддерживают присвоение уникальных идентификаторов содержащимся в них единицам справочных данных. В настоящее время в рамках проекта iRING есть механизм централизованного присвоения уникальных идентификаторов, но как это будет организовано в рамках федерации библиотек в связи со стартом проекта JORD – пока не известно.
Мэппинг
Любые данные (и справочные, и проектные) хранятся на каком-то носителе, и сегодня такими носителями, удобными для организации компьютерной обработки данных, являются хранилища данных (data warehouse – софт "базы данных" или "репозитория", развернутый на каких-то серверах). При этом свои прикладные программы и обеспечивающие их хранилища проектных данных имеют инженеры-проектировщики и специалисты по закупкам, составители календарно-сетевых графиков и бухгалтера. А внутри инженерной специальности свои хранилища, приспособленные для использования со средствами автоматизации проектирования, имеют строители, теплотехники, компоновщики, электрики, технологи, специалисты по автоматике и по АСУ ТП, и много кто ещё.
Обеспечение доступности для прикладных программ данных из различныъх хранилищ информации и является целью «интеграции проектных данных» (если говорить в терминах деятельности), или создания «единого информационного пространства» проекта (если говорить в терминах создаваемой программной инфраструктуры – хранилищ проектных данных).
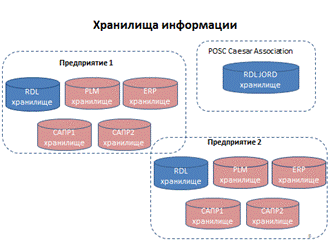
Прямой обмен данными между хранилищами в такой ситуации невозможен: данные каждого хранилища определены (формализованы) по-разному, поэтому для каждого хранилища должно быть реализовано множество программ, обеспечивающих передачу данных другим по принципу «точка-точка», что крайне затратно по ресурсам – число возможных пар огромно.
При использовании ISO 15926 передача данных между хранилищами происходит с переводом передаваемого фрагмента проектных данных в нейтральную по отношению к хранилищам форму. При этом инженерия справочных данных обеспечивает наличие и доступность нейтральных шаблонов для передачи значений проектных данных. Схема обменов данными резко упрощается: преобразование данных одного хранилища (например, системы САПР P&ID одного из поставщиков) происходит теперь только в один формат (подходящий для данного проекта набор шаблонов), определяемый постоянно пополняющимися справочными данными ISO 15926, а не в специализированные форматы каждого нового типа хранилища данных (например, систем PLM разных поставщиков), применяющегося в инженерном проекте.
По идеологии ISO 15926, для того, чтобы проектными данными из одного хранилища можно было пользоваться в других хранилищах, необходимо написать "адаптер" (adapter), который берет данные хранилища в его родном формате и выдаёт «наружу» в виде, соответствующем ISO 15926. Таким образом, все общающиеся между собой хранилища данных (хранящие данные для прикладных программ, включая САПР) выглядят друг для друга одинаково (по терминологии Части 9 стандарта это "фасады" (façade), но эту программистскую часть мы в данном тексте обсуждать пока не будем).
Далее именно такое взаимодействие всех-со-всеми, обеспеченное использованием «общего языка», мы будем называть "интеграцией данных" (в отличие от "обменов данными", где программисты каждый раз договариваются об обмене «точка-точка» – теплотехника с компоновщиком, планировщика с бухгалтерией, и реализуют запросы на обмены по мере их поступления). Поскольку формат и справочные данные ISO 15926 используются только для организации обменов данными, но не для хранения данных в хранилищах и не для их обработки прикладными программами, такой способ работы и называют "ISO 15926 outside".
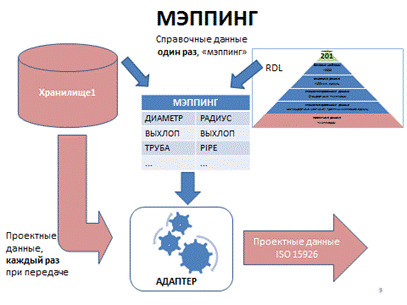
Каждый адаптер содержит в себе словарь для перевода с «языка» своего хранилища на общий язык ISO 15926. Этот словарь (тоже, кстати, данные) называется "мэппинг" (mapping). Чтобы поддержать перевод проектных данных на общий язык ISO 15926 в ходе передачи данных, необходимо обеспечить возможность адаптеру хранилища проектных данных использовать в мэппинге ссылки на единицы справочных данных (классы, шаблоны и роли шаблонов). Для этого и используются присваиваемые каждой библиотекой уникальные идентификаторы.
Мэппинг можно грубо представить себе как табличку из двух колонок: в одной колонке перечислены единицы описания проектных данных хранилища (элементы, определяющие «язык хранилища», его собственную «пустографку»): объекты метаданных, схем данных, моделей данных, классификаторов, справочников и т. п. конкретного хранилища данных, а в другой колонке – ссылки на классы, шаблоны и роли шаблонов из справочных данных ISO 15926.
Хранилища справочных данных
Библиотеки справочных данных, как и проектные данные, находятся в хранилищах данных в тех формах, которые предписывает софт хранилища (реляционная база данных, объект-ориентированный репозиторий, triple-store и т. д.).
Доступные для использования справочные данные должны быть доступны в форме, соответствующей ISO 15926, то есть после преобразования соответствующим «адаптером» на основе какого-то мэппинга из формата хранилища в формат, предписанный ISO 15926 – а именно, частями 8 и 9.
Для справочных данных мэппинг много проще, чем для проектных данных, и им обычно можно пренебречь – он реализуется при разработке софта хранилища интерфейсами редактора мэппинга и редактора справочных данных, и инженерам справочных данных им не нужно заниматься специально. Исключение составляют случаи включения в «Единое информационное пространство» какой-нибудь большой внешней базы данных (например, каталога промышленного оборудования) как справочных данных. Тогда эти данные каталога рассматриваются как проектные данные и проводится полноценный мэппинг, с возможной разработкой адаптера ISO 15926 для хранилища этого каталога.
При необходимости хранилище БСД должно предоставлять для использования в мэппинге полные описания единиц справочных данных, включая ограничения на атрибуты и кардинальности для отношений, аксиомы шаблонов, метаданные (даты заведения в хранилище, синонимы названия единицы справочных данных на иностранных языках) и пр.
На текущий момент для организации корпоративного хранилища справочных данных используется или программное обеспечения iRING Sandbox, или просто набор файлов стандарта XMpLant (XML-формат, не определяемый частями 8 и 9 Стандарта), либо набор файлов языка OWL (в виде, определяемом Частью 8 стандарта).
Текущее состояние библиотек справочных данных
На международном уровне планируется существование библиотеки справочных данных, контролируемой ISO. Пока что доступная публично «официальная» международная библиотека справочных данных называется PCA-RDS (контролируется POSC Caesar Association – PCA), и это не столько библиотека справочных данных, сколько помойка справочных данных, что не мешает пользоваться ею уже сегодня (для этого нужно обязательно установить Java-клиент http://rds. posccaesar. org/downloads/PCA-RDS_client. zip и нельзя использовать доступ через browser!).
Скоро БСД PCA-RDS, будем надеяться, будет переименована (или даже заменена с повышением качества данных) в рамках проекта JORD, запланированного к выполнению POCS Caesar Association и консорциумом FIATECH, впрочем, это мы забегаем в будущее.
Справочные данные ISO 15926 существуют на сегодня в части официально зарегистрированных классов только на уровне «модели данных» (201 понятие), на основном (англоязычные понятия, часто встречающиеся в инженерии) и чуть-чуть на стандартном (международных стандартов, ISO) уровнях пирамиды данных. В части шаблонов ситуация ещё хуже, набор одобренных профессиональным сообществом («черными поясами») базовых шаблонов катастрофически мал, а основные шаблоны разрабатываются на уровне отдельных проектов и публично пока недоступны.
Тем самым для интеграции проектных данных условием создания «единого информационного пространства» конкретного инженерного проекта является не столько наличие ресурсов квалифицированного персонала для построения мэппинга использующихся хранилищ, сколько наличие соответствующего сути инженерного проекта фрагмента справочных данных ISO 15926 – чтобы было к чему привязывать («мэппить») справочные данные этих хранилищ.
Наилучшим решением для этой проблемы пока что представляется собрать из доступных хранилищ пригодные справочные данные (каковых может оказаться не так много), а недостающие справочные данные разработать, исходя из потребностей отражения всех требующихся для передачи данных из интегрируемых хранилищ. На сегодня «создание единого информационного пространства проекта» на 80% усилий состоит именно из инженерии справочных данных.
Процесс выявления (сбора и/или разработки) необходимых справочных данных для формирования утверждений на языке ISO 15926 о каком-то наборе проектных данных называется «характеризацией» этого набора проектных данных.
Создавая справочные данные для конкретного инженерного проекта сегодня, нельзя забывать про перспективу – именно эти справочные данные наверняка понадобятся многим людям в других проектах и организациях, и нельзя сказать заранее, каким. Например, сегодня нет стандартных классов для ГОСТов, поэтому практически в любом проекте в России требуется разработать довольно много справочных данных уровня национальной библиотеки, что осложняется отсутствием ее институационального оформления – есть только отраслевые инициативы по справочным данным ISO 15926, и поэтому велика вероятность дублирования отраслевых усилий по разработке справочных данных.
Работа над справочными данными ISO 15926 "прагматична" (обслуживает обмен информацией для конкретной цели одного проекта, одного деятельностного контекста) и одновременно "семантична" (пригодна для интеграции данных в заранее неизвестных ситуациях – то есть работает не со «смыслом» данных, а со «значениями»). Единство "информационного пространства" в рамках одного инженерного проекта и среди многих проектов обеспечивается тем, что все справочные данные являются специализацией общей картины мира, задаваемой «моделью данных» – типами Части 2 стандарта ISO 15926. То есть все справочные данные в конечном итоге можно описать набором высказываний языка логики первого порядка, оперирующего предикатами, вытекающими из 201 прото-понятия этого "философско-компьютерного эсперанто".
Жизненный цикл справочных данных
Инженер справочных данных (из наследия «мира баз данных» за ним тянется иногда название "модельер данных") обеспечивает следующий список стадий инкрементального жизненного цикла справочных данных:
1. Выявление набора проектных данных, который нужно будет переводить в форму, соответствующую ISO 15926. Например, это может быть набор бумажных спецификаций насосов от разных производителей, или пакет чертёжей промышленной установки, или описание организационной структуры в виде базы данных, или результаты работы конструкторов и проектировщиков, внесённые ими в хранилище промышленного средства автоматизации проектирования (либо системы PLM – например, ENOVIA V6, либо отдельного САПР – например, SmartPlant 3D). Перенос данных из одного компьютерного хранилища в другое является наиболее частым использованием, но стандарт может быть использован и для организации переноса в компьютерное хранилище данных из бумажных (или сканированных) материалов.
Выявление набора данных, которые вы хотите передавать из хранилища в хранилище – очень важная стадия, и она занимает много времени и усилий (в том числе и потому, что обычно требуется проводить большое число переговоров с владельцами и пользователями разных данных). Не нужно забывать, что вы видите сперва только информационные объекты (распечатки, компьютерные сервера и отдельные файлы на их дисках), а данные – абстрактный объект, и нужно специально этот абстрактный объект формировать.
Важно в явном виде указать, что войдет в набор передаваемых данных, а что точно останется за пределами передачи и будет использоваться только в рамках одного хранилища и совместимых с ним приложений.
Важно в явном виде сформулировать ответ на вопрос управления конфигурацией: в какой степени ваши данные являются «живыми». Вы должны спланировать, будете ли вы передавать только окончательный результат работы (например, пакет сданных чертежей), или ваша задача – «синхронный перевод» постоянно изменяющихся решений прямо в процессе проектирования, по мере их появления в каком-то хранилище данных, и по мере уточнения справочных данных самого хранилища.
При идентификации интересующих вас наборов проектных данных надо не забывать отслеживать – какие у меня будут источники этих данных, и куда я их хочу в конечном итоге перемещать.
От результатов выполнения этой стадии зависит, каков будет объем работы по инженерии справочных данных, и насколько эта работа потом окажется полезной или бесполезной для реального инженерного проекта (например, можно создать огромную библиотеку справочных данных, но она окажется бесполезной при реальных передачах данных – разработанные справочные данные в реальных передачах не будут задействованы, а для мэппинга реальных данных каких-то справочных данных хватать не будет).
Выходными рабочими продуктами стадии являются наборы данных, которые подлежат характеризации, и указание на то, в каком контексте будут использованы результаты всей работы: из какого хранилища будут извлекаться эти наборы данных, и в какое хранилище потом попадать.
2. Выявление единиц описания данных хранилища. На этой стадии вы должны определить, что собственно вы будите «мэппить» (колонка описаний данных из хранилища в табличке мэппинга), чтобы обеспечить передачу данных для каждого хранилища информации, найденного на предыдущей стадии (как источника данных, так и места назначения).
При идентификации единиц описаний проектных данных вы должны понять содержательно (семантически, онтологически), какие у вас есть объекты в наборе проектных данных (трубы, документы, люди,…) и какие связи между ними можно обнаружить (присоединение, описание, ответственность,…), а также выявить необходимые метаданные (версии, варианты наименований, даты создания, места хранения оригинала, рабочий язык и т. д.).
Выходным рабочим продуктом этой стадии является список единиц описания данных хранилища. Какие именно единицы попадут в этот список – зависит от того, какой внутренний формат хранилища используется, каков его «язык» («хранилищем» может быть и характеризуемый набор бумажных документов). Для разных хранилищ этот набор едениц описания данных называются по-разному: метаданные, схема данных, метамодель. Важная часть этого списка – словари-справочники и классификаторы, используемые для описания данных хранилища.
Эта работа по факту занимает много времени, и в ней много тонкостей. Например, бойтесь просто брать схему базы данных идентифицированного на первой стадии хранилища и объявлять именно её единицы выявленными единицами описания проектных данных. Скорее всего, вы обнаружите, что в схеме данных вам "не хватит слов" для описания передаваемых в другое хранилище данных этого приложения. Например, в файлах чертежей, созданных при помощи САПР, могут обнаруживаться единицы, которые находятся вовсе не в базе данных, а в настроечных файлах, а то и в коде самого приложения. То есть база данных хранилища информации содержит данные, но не все данные – и тогда нужно анализировать не схему, а образцы чертежей, и пытаться определить единицы данных именно на ней, а в набор выявленных единиц описания данных включать те самые данные настроечных файлов или «константы» из кода.
Ситуация осложняется тем, что инженеры вполне могут не заморачиваться соответствием схемы данных хранилища при «настройке на проект» и использовать базу данных хранилища каким-нибудь неожиданным образом (например, в поле "внутренний диаметр" хранить "номинальный диаметр" – и этого никто не заметит, пока не понадобится перенести данные в САПР, различающую эти понятия). И в этом случае надо будет анализировать не схему данных хранилища, а образцы выходных (конечных) проектных данных – чертежи, заполненные спецификации, распечатанные отчёты и т. д.
Иногда наилучшим решением будет изначальное игнорирование схем баз данных используемых хранилищ, и разбирательство с бумажными распечатками (потом, правда, придется вернуться к схеме данных в ходе мэппинга – ибо адаптер не сумеет взять данные из нужных мест на бумажных носителях). Тем не менее, на бумажных документах можно выявить такие важные единицы данных, как различные заполняемые вручную поля (например, для подписи), выноски, различающиеся типы линий (например, выделенная жирной рамочкой группа данных в таблице, у которой есть содержательный смысл, но нет явно заданного названия) и т. д.
Выявление единиц описания данных влияет на то, какие именно наборы данных окажутся необходимы и должны быть отобраны на предыдущей стадии, поэтому две описанные стадии часто перекрываются во времени и проходят итеративно.
По сути, данная стадия является небольшим исследовательским проектом, и для неё нужно выделять достаточное время и ресурсы.
3. Характеризация набора идентифицированных единиц описания данных. На этой стадии создаются справочные данные ISO 15926, которые затем используются при мэппинге. Это самая сложная и трудозатратная часть работы.
Входной рабочий продукт этой стадии – выделенные на предыдущей стадии единицы описания данных (можно о них думать, как об уже заполненной колонке таблички мэппинга для адаптера какого-то хранилища).
В ходе стадии осуществляется работа с библиотеками справочных данных (локальной проекта или предприятия, и внешними – других предприятий, отраслевой, национальной, JORD/PCA-RDS), которые было решено использовать для данного проекта.
Выходной рабочий продукт – единицы справочных данных, необходимые для мэппинга, и зарегистрированные в надлежащих для их уровня библиотеках справочных данных.
В ходе характеризации выполняются следующие шаги:
· Выбор связанных единиц данных из набора выявленных единиц данных.
· Выбор библиотек справочных данных, в которых будут искаться классы и шаблоны (тут нужно обратить внимание, что не всем доступным библиотекам можно доверять – и этот выбор может потребовать неожиданно больших исследований).
· Поиск в библиотеках справочных данных таких единиц данных (классов и индивидов), из которых необходимые вам единицы справочных данных могут быть получены путём специализации, или которые непосредственно могут быть использованы для классификации необходимых вам единиц описаний проектных данных. На этом шаге ищутся соответствия для единиц описания проектных данных и их метаданных (как правило, на уровне классов индивидов и классов отношений), и отношений между ними (среди классов отношений). Особенное внимание уделяется таким единицам описания данных хранилища, как атрибуты, параметры, единицы измерения. Для этих типов сущностей стандартом ISO 15926 предусмотрены весьма контринтуитивные типы справочных данных.
· Пополнение отсутствующих единиц справочных данных (классов и индивидов), установление связей между найденными и определяемыми справочными данными. В рамках этой работы проводятся типизация, классификация и специализация необходимых вам единиц справочных данных, а также определение атрибутов отношений и классов отношений. Основным инструментом для выполнения этого шага является построение аналитических диаграмм в формате Частей 2 и 7 стандарта (примеры см. на сайте http://www.15926.info/ или на странице http:///iso15926_sample_diagrams). По завершении этого шага сформированные вами справочные данные должны также содержать единицы, соответствующие гнездам словарей-справочников и фасетам классификаторов, используемых для описания данных хранилища.
· Выделение ролей и границ шаблонов на подготовленных аналитических диаграммах, с учётом доступных базовых, основных и специализированных шаблонов. Должны быть приняты решения о непосредственном использовании найденных в библиотеках справочных данных шаблонов, или о разработке на основе доступных в них шаблонов новых специализированных шаблонов для описания данных построенных диаграмм. Образцы описания шаблонов можно видеть на страницах, доступных с https://www. posccaesar. org/wiki/SigMmt/Templates/ .
· Проверка корректности вашего результата в рамках «общей картины мира» («модели данных»): не перепутали ли вы "индивид" и "отношение", или не прописали ли вы свойство "сила тока" для «балки». На этом шаге инструменты автоматизированной проверки отсутствуют, проверка выполняется глазами, по диаграмме. Рекомендуется участие в этом шаге отдельной роли «тестировщика моделей» (желательно имеющего квалификацию «черный пояс»).
· Регистрация созданных единиц справочных данных (классов, индивидов, шаблонов) в БСД проекта. Особенности выполнения данного шага зависят от выбранного способа ведения БСД и от используемого хранилища данных. В настоящее время доступные способы включают как ведение локальных файлов на серверах компании в форматах MS Excel или OWL (без автоматического получения доступа к справочным данным), так и использование программного обеспечения iRING Sandbox (с предоставлением автоматического доступа к «фасаду» хранилища справочных данных в виде RDF/OWL SPARQL endpoint). На этом шаге также следует задуматься над необходимостью введения русских имён новых единиц справочных данных и для тех единиц, которые были обнаружены в составе англоязычных БСД. Если регистрация русских имён для данного инженерного проекта целесообразна, она осуществляется как регистрация справочных данных в БСД проекта.
· Пополнение созданными справочными данными внешних БСД. Если результат может быть применим не только в вашем проекте, но и на отраслевом, национальном или даже международном уровне – им нужно поделиться. Например, занести шаблон в раздел "предложенные" на странице https://www. posccaesar. org/wiki/SigMmt/Templates, чтобы им после проверки и утверждения мог пользоваться весь мир. Точно так же, по установленным внешними БСД правилам, можно провести регистрацию в них русских имён для справочных данных.
· Верификация справочных данных. После регистрации справочных данных в БСД в ряде случаев возможна компьютерная верификация, при которой специальное программное обеспечение проверяет корректность созданной совокупности справочных данных: отсутствие противоречий в типизации, специализации, классификации и атрибутах классов, индивидов, отношений, шаблонов и ролей. Пока что готовое программного обеспечения для верификации отсутствует, в будущем, видимо, оно будет зависеть от форматов выбранных хранилищ данных. Проект.15926 планирует выполнение таких проверок.
4. Мэппинг. На этой стадии прописывается соответствие выбранных единиц справочных данных ISO 15926 единицам описания проектных данных хранилища.
Как правило, мэппинг осуществляется отождествлением единиц описания проектных данных с ролями специализированных шаблонов из библиотек справочных данных, выбранных и/или разработанных на предыдущей стадии характеризации наборов данных (говорят «мэппинг единиц описаний проектных данных к ролям шаблонов»). Это позволяет в дальнейшем получать проектные данные из хранилища переведёнными в нейтральное представление ISO 15926. Такие данные могут быть закачаны в любое другое хранилище, для которого проведён мэппинг к тому же самому набору единиц справочных данных.
«Магия семантических технологий» ISO 15926 заключается в том, что мэппинг производится в общем случае к единицам справочных данных (связанным отношениями классам и индивидам), получаемым, вообще говоря, из разных шаблонов, а не к строго одному и тому же набору шаблонов со строго одним и тем же набором ролей. Поэтому, если проектные данные из чужого хранилища будут получены вами в виде экземпляров такого шаблона, который вы не использовали при мэппинге единиц описаний проектных данных вашего хранилища, у вас есть «семантический» выход. Вам необходимо обратиться к той библиотеке справочных данных, в которой зарегистрирован неизвестный шаблон, получить из него аксиому шаблона, построить по ней аналитическую диаграмму (если она не предоставляется хранилищем), понять на основании диаграммы и ограничений ролей назначение шаблона, и осуществить мэппинг его ролей к единицам описания проектных данных вашего хранилища.
Если неизвестный шаблон окажется специализацией иного, также неизвестного вам шаблона, необходимо будет пройти по всей цепочке специализаций и получить аксиомы всех шаблонов, использованных для построения анализируемого. Эта операция является по сути «поднятием» шаблона до уровня Части 2 стандарта, описанной в Части 7.
Рабочим продуктом стадии являются таблицы мэппинга, понимаемые адаптерами задействованных при передаче данных хранилищ.
Процедура мэппинга существенно зависит от используемого программного обеспечения, для разных программ реализации интерфейсов «редактора мэппинга» («переводчика») и форматы таблицы мэппинга («словаря») могут существенно различаться. Сами хранилища проектных данных могут быть реализованы как Excel таблицы, реляционные базы данных, объектные базы данных разной структуры – во всех этих случаях нужно ожидать «особенностей».
Создание мэппинга – это эксплуатация созданного на предыдущей стадии рабочего продукта «справочные данные».
Мэппинг выполняется для каждого участвующего в едином информационном пространстве проекта хранилища – для всех источников и приёмников проектных данных. Это само по себе не так трудно (основная работа – создание недостающих справочных данных – к этому моменту уже проведена), но требует знания особенностей представления проектных данных в хранилищах, наравне со знанием устройства библиотек справочных данных ISO 15926.
5. Передача проектных данных. Осуществить передачу проектных данных между хранилищами становится возможным тогда, когда для обоих хранилищ есть мэппинги единиц описания данных к одному и тому же набору справочных данных (в самом простом случае – к ролям одного и того же набора специализированных шаблонов). С помощью мэппинга для источника данных из хранилища-источника его адаптер создаёт обменные файлы (или набор сообщений в случае он-лайн запросов), а с помощью мэппинга для приёмника данных его адаптер помещает данные в хранилище-приёмник в «родном» для него формате.
Тем самым предусловием передачи проектных данных является наличие двух адаптеров: хранилища-источника, и хранилища-приёмника.
Входными рабочими продуктами являются выходные рабочие продукты предыдущей стадии – мэппинги (словари соответствия, понимаемые адаптерами) для участвующих в передаче данных хранилищ.
Выходным рабочим продуктом стадии являются обменные файлы с проектными данными в нейтральном по отношению к участвующим хранилищам данных формате.
На этой стадии работает не столько инженер справочных данных, сколько новая профессиональная роль – «администратор проектных данных». Формально на этой стадии жизненного цикла сами справочные данные не участвуют, и эта стадия, скорее из жизненного цикла инженерного проекта. Тут она приведена «по сопричастности».
6. Верификация результатов. На этой стадии проверяется полнота и непротиворечивость данных, сформированных в хранилище-приёмнике. Эта верификация может проводиться с помощью прикладных программ, предназначенных для работы с данным хранилищем, или же вручную. Скорее всего, при этом обнаружится, что из одних хранилищ в другие передаются не все требующиеся проектные данные. Причиной этого, скорее всего, является неполное или неправильное выявление единиц описания проектных данных на стадии 2.
Инкрементальность жизненного цикла. Важно отметить, что интеграцию данных практически нереально выполнить «за один проход» (то есть на первом шаге определить все участвующие в крупном проекте хранилища, выявить все интересующие наборы данных, и т. д.). Обычно таких «проходов» несколько, и каждый раз берется небольшая порция работы – исходя из насущных потребностей инженеров. Поэтому представленный жизненный цикл является инкрементальным (в смысле ISO 19760): при его очередном прохождении увеличиваются возможности по передаче информации.
Языки моделирования данных
В ходе инженерии справочных данных используется множество языков, из которых главный – английский. Без знания английского языка будет трудно разобраться, получение адекватного перевода всех частей стандарта ISO 15926 на русский язык маловероятно (как показывает пример официального перевода Части 1). Версии частей стандарта и методических материалов пока что появляются и меняются слишком часто, а библиотеки справочных данных не предназначены для перевода по своей природе.
Тем не менее, перевод на русский язык имен единиц справочных данных является вполне возможной задачей, и входит в число необходимых практик метода инженерии справочных данных, как описано выше.
Далее следует перечислить формальные языки моделирования данных:
· «Язык Части 2» – это 201 тип данных, определенный в Части 2 ISO 15926 на языке описания данных EXPRESS (ISO ), и проиллюстрированный на языке диаграмм Части 2. Этот список видов данных необходимо выучить для чтения и письма «без словаря» тем, кто пишет базовые и основные шаблоны и определяет основные классы (об этих инженерах данных говорят "чёрный пояс"). Тем, кто регистрирует специальные классы и разрабатывает специализированные шаблоны, нужно иметь о нём достаточное представление (знать "со словарём"). Об этих инженерах данных говорят "жёлтый пояс".
· Язык шаблонов – это язык седьмой части стандарта, подкласс языка логики первого порядка (FOL, first-order logic). Язык логики первого порядка используется для написания аксиом шаблонов (см. примеры шаблонов по приведенным ссылкам). Однако базовый уровень специализации шаблонов возможно осуществлять и без твёрдого владения этим языком. Всем инженерам справочных данных нужно знать язык диаграмм Части 7, позволяющий строить аналитические диаграммы шаблонов.
· Языки RDF и OWL обязательно знать лишь тем, кто либо не использует программные средства формирования файлов мэппинга и файлов проектных данных (например, входящие в iRING Tools), либо не удовлетворён качеством работы этих программ.
Инженер справочных данных
Профессиональная роль инженера справочных данных предъявляет следующие требования к квалификации:
· Знание технического английского.
· Понимание теории множеств и логики в объеме курса математики инженерных специальностей.
· Знакомство со всеми частями ISO 15926.
· Хорошие коммуникативные навыки (для поддержания диалога с инженерами, чьи данные они будут характеризовать).
Есть два основных уровня квалификации: «черный пояс» (дающий возможность разрабатывать и оценивать данные, предназначенные для регистрации в библиотеках справочных данных уровня выше предприятия – глобальном, национальном, отраслевом), и «желтый пояс» (дающий возможность разрабатывать и оценивать данные, предназначенные для регистрации в библиотеках справочных данных предприятий и/или отдельных проектов).
Подготовка инженера справочных данных, из квалифицированного сотрудника, впервые познакомившегося с ISO 15926, занимает обычно три месяца полной занятости до момента достижения уровня «желтый пояс».
Используемый инструментарий
Редактор справочных данных позволяет искать в федерации БСД и регистрировать справочные данные (классы и шаблоны) в собственной БСД. Это основной инструмент характеризации. Работает он, как правило, с «песочницей» собственной библиотеки справочных данных проекта, где накапливаются результаты работы. На данный момент доступен редактор справочных данных проекта iRING.
Для иных реализаций стандарта (например, XMpLant) редактор iRING не пригоден, и редактирование справочных должно осуществляться иным способом, например, редактором XML.
Нам неизвестны случаи успешного применения для редактирования справочных данных в реальном проекте редактора онтологий Protégé (любых версий). По всей видимости, это невозможно без написания каких-то специальных плагинов, но и в этом случае сомнительно из-за его неспособности работать с внешними БСД и невозможности «закачать» объёмы реальных БСД в формате OWL.
Редактор мэппинга позволяет определять мэппинги. Его входами являются структура данных конкретного хранилища данных, а также федерация библиотек справочных данных.
Адаптер умеет передавать описания данных хранилища редактору мэппинга, и с использованием мэппинга формировать файлы с проектными данных на основе данных хранилища, либо помещать данные из таких файлов в хранилище.
Тем самым, именно адаптер уникален для каждого типа хранилища данных. Например, для SmartPlant Foundation нужен один, для AVEVA NET Platform другой, для Bentley ProjectWise третий, и на сегодня всё это – гипотетические ситуации. В проекте iRING (http://iringug. org) ведётся для начала разработка адаптеров программных продуктов серии SmartPlant, и далее возможно расширение на продукты прочих производителей (http://iringug. org/wiki/index. php? title=IRINGTools_Interfacing_Project).
Пока же iRING имеет редактор мэппинга и «универсальный» адаптер, которые требуют копировать информацию из реального хранилища во временное хранилище данных с реляционной структурой (то есть отдельно «упрощать» структуру данных хранилища), и позволяют мэппинг уже к этой промежуточной структуре данных.
