


Программный код не перемещается во время выполнения, то есть может быть проведена единовременная настройка адресов посредством использования перемещающего загрузчика.
Выбор раздела для вновь поступившей задачи может осуществляться по разным правилам, таким, например, как "первый попавшийся раздел достаточного размера", или "раздел, имеющий наименьший достаточный размер", или "раздел, имеющий наибольший достаточный размер". Все эти правила имеют свои преимущества и недостатки.
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток - фрагментация памяти. Фрагментация - это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Перемещаемые разделы
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов, так, чтобы вся свободная память образовывала единую свободную область (рисунок 2.11). В дополнение к функциям, которые выполняет ОС при распределении памяти переменными разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется "сжатием". Сжатие может выполняться либо при каждом завершении задачи, либо только тогда, когда для вновь поступившей задачи нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц, а во втором - реже выполняется процедура сжатия. Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то преобразование адресов из виртуальной формы в физическую должно выполняться динамическим способом.
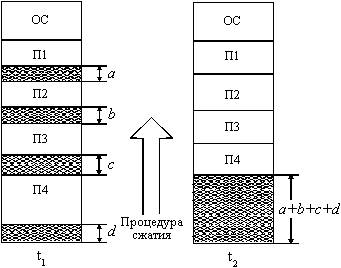
Рис. 2.11. Распределение памяти перемещаемыми разделами
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода.
29.Страничное распределение памяти.
Нах делаю хз и так все знают но все-таки правда рисунок каль :)
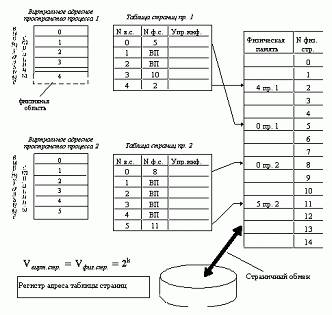
Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами. В общем случае размер виртуального адресного пространства не является кратным размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью.
Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками).
Размер страницы обычно выбирается равным степени двойки: 512, 1024 и т. д., это позволяет упростить механизм преобразования адресов.
При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные - на диск. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. При загрузке операционная система создает для каждого процесса информационную структуру - таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в оперативную память, или делается отметка о том, что виртуальная страница выгружена на диск. Кроме того, в таблице страниц содержится управляющая информация, такая как признак модификации страницы, признак невыгружаемое™ (выгрузка некоторых страниц может быть запрещена), признак обращения к странице (используется для подсчета числа обращений за определенный период времени) и другие данные, формируемые и используемые механизмом виртуальной памяти.
Есть ещё такая штука, инвертированная таблица страниц, это когда не список виртуальных, и соответсвуюих им физических, а наборот, список физических. Таблица получается, понятно, гораздо меньше, но в ней сложнее искать физический адрес по виртуальному.
30.Сегментное распределение памяти.
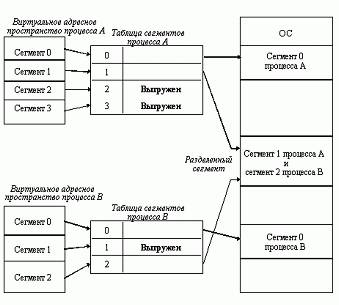
Виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т. п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память (при этом для каждого из этих сегментов операционная система подыскивает подходящий участок свободной памяти), а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту.
Недостатком данного метода распределения памяти является фрагментация на уровне сегментов и более медленное по сравнению со страничной организацией преобразование адреса.
31.Сегментно-страничное распределение памяти.
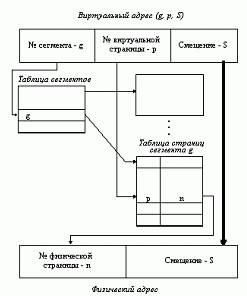
Виртуальное пространство процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента. Оперативная память делится на физические страницы. Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в оперативной памяти, а часть на диске. Для каждого сегмента создается своя таблица страниц, структура которой полностью совпадает со структурой таблицы страниц, используемой при страничном распределении. Для каждого процесса создается таблица сегментов, в которой указываются адреса таблиц страниц для всех сегментов данного процесса. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс.
32. Задачи ОС по управлению файлами и устройствами
Подсистема ввода-вывода (Input-Output Subsystem) мультипрограммной ОС при обмене данными с внешними устройствами компьютера должна решать ряд общих задач, из которых наиболее важными являются следующие:
организация параллельной работы устройств ввода-вывода и процессора;
согласование скоростей обмена и кэширование данных;
разделение устройств и данных между процессами;
обеспечение удобного логического интерфейса между устройствами и остальной частью системы;
поддержка широкого спектра драйверов с возможностью простого включения в систему нового драйвера;
динамическая загрузка и выгрузка драйверов;
поддержка нескольких файловых систем;
поддержка синхронных и асинхронных операций ввода-вывода.
33. Физическая организация файловой системы
Жесткий диск состоит из одной или нескольких стеклянных или металлических пластин, каждая из которых покрыта с одной или двух сторон магнитным материалом.
На каждой стороне каждой пластины размечены тонкие концентрические кольца — дорожки (traks), на которых хранятся данные. Количество дорожек зависит от типа диска. Нумерация дорожек начинается с 0 от внешнего края к центру диска. Когда диск вращается, элемент, называемый головкой, считывает двоичные данные с магнитной дорожки или записывает их на магнитную дорожку.
Головка может позиционироваться над заданной дорожкой. Головки перемещаются над поверхностью диска дискретными шагами, каждый шаг соответствует сдвигу на одну дорожку. Запись на диск осуществляется благодаря способности головки изменять магнитные свойства дорожки.
Цилиндр - совокупность дорожек одного радиуса на всех поверхностях всех пластин пакета. Сектор – фрагменты, на которые разбивается каждая дорожка. Все дорожки имеют равное число секторов, в которые можно максимально записать одно и то же число байт. Сектор имеет фиксированный для конкретной системы размер, выражающийся степенью двойки (чаще - 512 байт). Плотность записи тем выше, чем ближе дорожка к центру.
Сектор — наименьшая адресуемая единица обмена данными дискового устройства с оперативной памятью. Для того чтобы контроллер мог найти на диске нужный сектор, необходимо задать ему все составляющие адреса сектора: номер цилиндра, номер поверхности и номер сектора. Так как прикладной программе в общем случае нужен не сектор, а некоторое количество байт, не обязательно кратное размеру сектора, то типичный запрос включает чтение нескольких секторов, содержащих требуемую информацию, и одного или двух секторов, содержащих наряду с требуемыми избыточные данные.
Кластер – собственная единица дискового пространства операционной системы. При создании файла место на диске ему выделяется кластерами.
Дорожки и секторы создаются в результате выполнения процедуры физического, или низкоуровневого, форматирования диска, предшествующей использованию диска. Для определения границ блоков на диск записывается идентификационная информация. Низкоуровневый формат диска не зависит от типа операционной системы, которая этот диск будет использовать.
Разметку диска под конкретный тип файловой системы выполняют процедуры высокоуровневого, или логического, форматирования. При высокоуровневом форматировании определяется размер кластера и на диск записывается информация, необходимая для работы файловой системы (информация о доступном и неиспользуемом пространстве, границах отведенных под файлы и каталоги областей, о поврежденных областях). Кроме того, на диск записывается загрузчик операционной системы — небольшая программа, которая начинает процесс инициализации операционной системы после включения питания или рестарта компьютера.
Прежде чем форматировать диск под определенную файловую систему, он может быть разбит на разделы.
Раздел — непрерывная часть физического диска, которую операционная система представляет пользователю как логическое устройство (используются также названия логический диск и логический раздел). Логическое устройство функционирует так, как если бы это был отдельный физический диск.
Логические устройства не могут быть использованы операционными системами разного типа. Все разделы одного диска имеют одинаковый размер блока, определенный для данного диска в результате низкоуровневого форматирования. Однако в результате высокоуровневого форматирования в разных разделах одного и того же диска, представленных разными логическими устройствами, могут быть установлены файловые системы, в которых определены кластеры отличающихся размеров.
Операционная система может поддерживать разные статусы разделов, особым образом отмечая разделы, которые могут быть использованы для загрузки модулей операционной системы, и разделы, в которых можно устанавливать только приложения и хранить файлы данных. Один из разделов диска помечается как загружаемый (или активный). Именно из этого раздела считывается загрузчик операционной системы.
34. 4 способа размещения файлов.
Непрерывные файлы
Простейшей схемой выделения файлам определенных блоков на диске является система, в которой файлы представляют собой непрерывные наборы соседних блоков диска. Тогда на диске, состоящем из блоков по 1 Кбайт, файл размером в 50 Кбайт будет занимать 50 последовательных блоков. При 2-килобайтных блоках такой файл займет 25 соседних блоков.
У непрерывных файлов есть два существенных преимущества.
Во-первых, такую систему легко реализовать, так как системе, чтобы определить, какие блоки принадлежат тому или иному файлу, нужно следить всего лишь за двумя числами: номером первого блока файла и числом блоков в файле. Зная первый блок файла, любой другой его блок легко получить при помощи простой операции сложения.
Во-вторых, при работе с непрерывными файлами производительность просто превосходна, так как весь файл может быть прочитан с диска за одну операцию. Требуется только одна операция поиска (для первого блока). После этого более не нужно искать цилиндры и тратить время на ожидания вращения диска, поэтому данные могут считываться с максимальной скоростью, на которую способен диск.
Недостатки: со временем диск становится фрагментированным, нужно заранее знать размер файла.
И все-таки есть ситуации, в которых непрерывные файлы могут применяться и в самом деле широко используются: на компакт-дисках. Здесь все размеры файлов известны заранее и не могут меняться при последующем использовании файловой системы CD-ROM.
Связные списки
Второй метод размещения файлов состоит в представлении каждого файла в виде связного списка из блоков диска, как показано на рис. 6.10. Первое слово каждого блока используется как указатель на следующий блок. В остальной части блока хранятся данные.
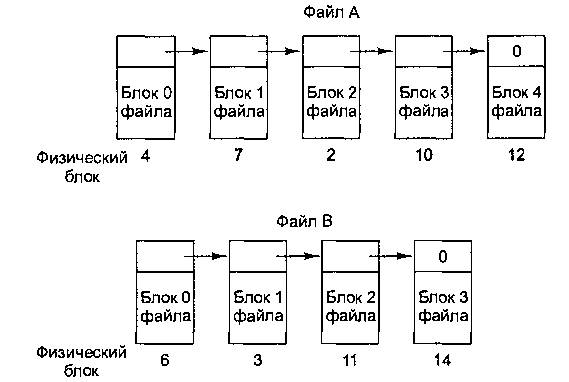
Рис. 6.10. Размещение файла в виде связного списка блоков диска В отличие от систем с непрерывными файлами, такой метод позволяет использовать каждый блок диска. Нет потерь дискового пространства на фрагментацию (кроме потерь в последних блоках файла). Кроме того, в каталоге нужно хранить только адрес первого блока файла. Всю остальную информацию можно найти там.
С другой стороны, хотя последовательный доступ к такому файлу несложен, произвольный доступ будет очень медленным. Чтобы получить доступ к блоку п, операционная система должна сначала прочитать первые п - 1 блоков по очереди. Очевидно, такая схема оказывается очень медленной.
Связный список при помощи таблицы в памяти
Оба недостатка предыдущей схемы организации файлов в виде связных списков могут быть устранены, если указатели на следующие блоки хранить не прямо в блоках, а в отдельной таблице, загружаемой в память. На рис. 6.11 показан внешний вид такой таблицы для файлов с рис. 6.10. На обоих рисунках показаны два файла. Файл А использует блоки диска 4, 7,2,10 и 12, а файл В использует блоки диска 6, 3,11 и 14. С помощью таблицы, показанной на рис. 6.11, мы можем начать с блока 4 и следовать по цепочке до конца файла. То же может быть сделано для второго файла, если начать с блока 6. Обе цепочки завершаются специальным маркером (например -1), не являющимся допустимым номером блока. Такая таблица, загружаемая в оперативную память, называется FAT-таблицей (File Allocation Table — таблица размещения файлов).
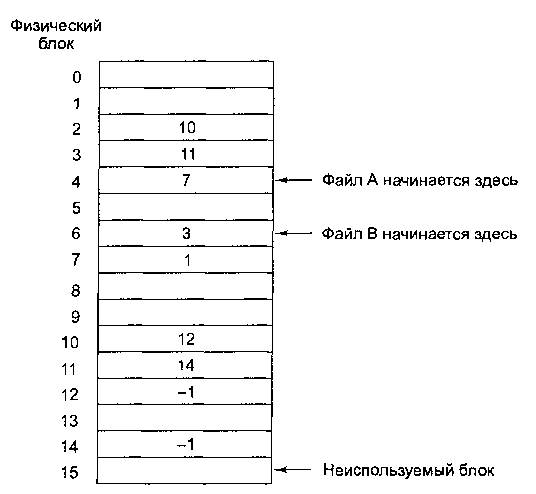
Рис. 6.11. Таблица размещения файлов
Эта схема позволяет использовать для данных весь блок. Кроме того, случайный доступ при этом становится намного проще. Хотя для получения доступа к какому-либо блоку файла все равно понадобится проследовать по цепочке по всем ссылкам вплоть до ссылки на требуемый блок, однако в данном случае вся цепочка ссылок уже хранится в памяти, поэтому для следования по пей не требуются дополнительные дисковые операции. Как и в предыдущем случае, в каталоге достаточно хранить одно целое число (номер начального блока файла) для обеспечения доступа ко всему файлу.
Основной недостаток этого метода состоит в том, что вся таблица должна постоянно находиться в памяти. Для 20-гигабайтного диска с блоками размером 1 Кбайт потребовалась бы таблица из 20 млн записей, по одной для каждого из 20 млн блоков диска. Каждая запись должна состоять как минимум из трех байтов. Для ускорения поиска размер записей должен быть увеличен до 4 байт. Таким образом, таблица будет постоянно занимать 60 или 80 Мбайт оперативной памяти. Таблица, конечно, может быть размещена в виртуальной памяти, но и в этом случае ее размер оказывается чрезмерно большим, к тому же постоянная выгрузка таблицы на диск и загрузка с диска существенно снизит производительность файловых операций.
I-узлы
Последний метод отслеживания принадлежности блоков диска файлам состоит в связывании с каждым файлом структуры данных, называемой i-узлом (index node — индекс-узел), содержащей атрибуты файла и адреса блоков файла. Простой пример i-узла показан на рис. 6.12. При наличии i-узла можно найти все блоки файла. Большое преимущество такой схемы перед хранящейся в памяти таблицей из связных списков заключается в том, что каждый конкретный i-узел должен находиться в памяти только тогда, когда соответствующий ему файл открыт. Если каждый i-узел занимает n байт, а одновременно открыто может быть k файлов, то для массива i-узлов потребуется в памяти всего kn байтов.
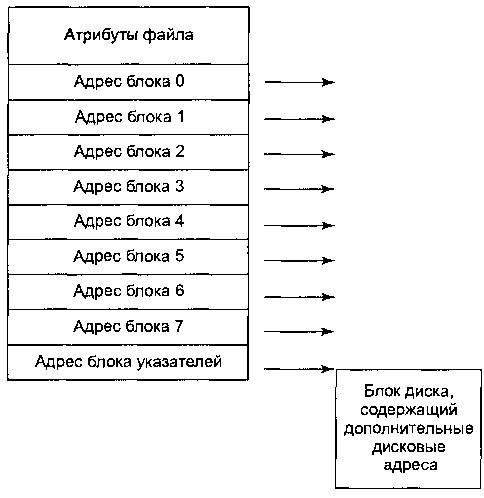
Рис. 6.12. Пример i-узла
Обычно этот размер значительно меньше, чем FAT-таблица, описанная в предыдущем разделе. Это легко объясняется. Размер таблицы, хранящей связный список всех блоков диска, пропорционален размеру самого диска. Для диска из n блоков потребуется n записей в таблице. Таким образом, размер таблицы линейно растет с ростом размера диска. Для схемы i-узлов, напротив, требуется массив в памяти с размером, пропорциональным максимальному количеству файлов, которые могут быть открыты одновременно. При этом не важно, будет ли размер диска 1 Гбайт, 10 Гбайт или 100 Гбайт.
С такой схемой связана проблема, заключающаяся в том, что при выделении каждому файлу фиксированного количества дисковых адресов этого количества может не хватить. Одно из решений заключается в резервировании последнего дискового адреса не для блока данных, а для следующего адресного блока, как показано на рис. 6.12. Более того, можно создавать целые цепочки и даже деревья адресных блоков.
35. Файловые операции
Файловая система ОС должна предоставлять пользователям набор операций работы с файлами, оформленный в виде системных вызовов. Этот набор обычно состоит из таких системных вызовов, как create (создать файл), read (читать из файла), write (записать в файл) и некоторых других.
Чаще всего с одним и тем же файлом пользователь выполняет не одну операцию, а последовательность операций. Например, при работе текстового редактора с файлом, в котором содержится некоторый документ, пользователь обычно считывает несколько страниц текста, редактирует эти данные и записывает их на место считанных, а затем считывает страницы из другой области файла, и т. п. После большого количества операций чтения и записи пользователь завершает работу с данным файлом и переходит к другому. Какие бы операции не выполнялись над файлом, ОС необходимо выполнить ряд универсальных для всех операций действий:
По символьному имени файла найти его характеристики, которые хранятся в файловой системе на диске.
Скопировать характеристики файла в оперативную память, так как только таким образом программный код может их использовать.
На основании характеристик файла проверить права пользователя на выполнение запрошенной операции (чтение, запись, удаление, просмотр атрибутов файла).
Очистить область памяти, отведенную под временное хранение характеристик файла.
Кроме того, каждая операция включает ряд уникальных для нее действий, например чтение определенного набора кластеров диска, удаление файла и т. п. Операционная система может выполнять последовательность действий над файлом двумя способами:
Для каждой операции выполняются как универсальные, так и уникальные действия. Такая схема иногда называется схемой без запоминания состояния операций (stateless).
Все универсальные действия выполняются в начале и конце последовательности операций, а для каждой промежуточной операции выполняются только уникальные действия.
Подавляющее большинство файловых систем поддерживает второй способ организации файловых операций как более экономичный и быстрый. Первый способ обладает одним преимуществом — он более устойчив к сбоям в работе системы, так как каждая операция является самодостаточной и не зависит от результата предыдущей. Поэтому первый способ иногда применяется в распределенных сетевых файловых системах (например, в Network File System, NFS компании Sun), когда сбои из-за потерь пакетов или отказов одного из сетевых узлов более вероятны, чем при локальном доступе к файлам.
При втором способе в файловой системе вводятся два специальных системных вызова: open — открытие файла, и close — закрытие файла. Системный вызов открытия файла open выполняется перед началом любой последовательности операций с файлом, а вызов закрытия файла close — после окончания работы с файлом. Основной задачей вызова open является преобразование символьного имени файла в его уникальное числовое имя, копирование характеристик файла из дисковой области в буфер оперативной памяти и проверка прав пользователя на выполнение запрошенной операции. Вызов close освобождает буфер с характеристиками файла и делает невозможным продолжение операций с файлом без его повторного открытия.
36. Контроль доступа к файлам.
Определить права доступа к файлу - значит определить для каждого пользователя набор операций, которые он может применить к данному файлу. В разных файловых системах может быть определен свой список дифференцируемых операций доступа. Этот список может включать следующие операции:
создание файла,
уничтожение файла,
открытие файла,
закрытие файла,
чтение файла,
запись в файл,
дополнение файла,
поиск в файле,
получение атрибутов файла,
установление новых значений атрибутов,
переименование,
выполнение файла,
чтение каталога,
и другие операции с файлами и каталогами.
В самом общем случае права доступа могут быть описаны матрицей прав доступа, в которой столбцы соответствуют всем файлам системы, строки - всем пользователям, а на пересечении строк и столбцов указываются разрешенные операции (рисунок 2.35). В некоторых системах пользователи могут быть разделены на отдельные категории. Для всех пользователей одной категории определяются единые права доступа. Например, в системе UNIX все пользователи подразделяются на три категории: владельца файла, членов его группы и всех остальных.
Различают два основных подхода к определению прав доступа:
избирательный доступ, когда для каждого файла и каждого пользователя сам владелец может определить допустимые операции;
мандатный подход, когда система наделяет пользователя определенными правами по отношению к каждому разделяемому ресурсу (в данном случае файлу) в зависимости от того, к какой группе пользователь отнесен.
37. FAT.
Файловая система FAT (File Allocation Table) представляет собой простую файловую систему, разработанную для небольших дисков и простых структур каталогов. Название этой файловой системы происходит от метода, применяемого для организации файлов, - таблица размещения файлов (File Allocation Table, FAT), которая размещается в начале тома. В целях защиты тома на нем хранятся две копии FAT, на тот случай, если одна из них окажется поврежденной. Кроме того, таблица размещения файлов и корневой каталог должны размещаться по строго фиксированным адресам, чтобы файлы, необходимые для запуска системы, были размещены корректно.
Том, отформатированный для использования файловой системы FAT, размечается по кластерам. Размер кластера по умолчанию определяется размером тома. При использовании файловой системы FAT номер кластера должен иметь длину не более 16 бит и представлять собой одну из степеней 2. Размеры кластеров по умолчанию в зависимости от размера тома приведены в таблице. При форматировании тома FAT с помощью программы Format из командной строки пользователь имеет возможность указать другой размер кластера, отличный от значения, устанавливаемого по умолчанию. Однако устанавливаемый размер не может быть меньше размера по умолчанию, указанного в таблице для соответствующего размера тома.
Размер раздела Размер кластера
< 16 Мб 4 Кб
16 Мб – 127 Мб 2 Кб
128 Мб – 255 Мб 4 Кб
256 Мб – 511 Мб 8 Кб
512 Мб – 1023 Мб 16 Кб
1 Гб – 2 Гб 32 Кб
2 Гб – 4 Гб 64 Кб
Загрузочный сектор, Блок параметров BIOS (BPB) FAT1 FAT2 (копия) Корневой каталог Область файлов
Структура тома FAT
Таблицы расположения файлов (области FAT1 и FAT2) содержат следующую информацию о каждом кластере тома:
Unused (кластер не используется)
Cluster in use by a file (кластер используется файлом)
Bad cluster (плохой кластер)
Last cluster in a file (последний кластер файла)
Корневой каталог содержит записи для каждого файла и каждого каталога, расположенных в корневом каталоге. Единственным различием между корневым каталогом и всеми остальными каталогами является то, что корневой каталог занимает четко определенное место на диске и имеет фиксированный размер (512 записей для жесткого диска; для дискет этот размер определяется объемом дискеты).
Каталоги содержат 32-байтные записи для каждого содержащегося в них файла и каждого вложенного каталога. Эти записи содержат следующую информацию:
имя (в формате "8+3"),
байт атрибутов (8 бит),
время создания (24 бит),
дата создания (16 бит),
дата последнего доступа (16 бит),
время последней модификации (16 бит),
дата последней модификации (16 бит),
номер начального кластера файла в таблице расположения файлов (16 бит),
размер файла (32 бит).
Структура каталога FAT не имеет четкой организации, и файлам присваиваются первые доступные адреса кластеров на томе. Номер начального кластера файла представляет собой адрес первого кластера, занятого файлом, в таблице расположения файлов. Каждый кластер содержит указатель на следующий кластер, использованный файлом, или индикатор (OxFFFF), указывающий на то, что данный кластер является последним кластером файла.
Поскольку все записи каталога имеют одинаковый размер, байт атрибутов для каждой записи описывает тип этой записи. Один бит указывает, что запись является, например, подкаталогом, в то время, как другой бит помечает запись как метку тома. Как правило, настройкой этих атрибутов управляет только операционная система.
Файл FAT имеет 4 атрибута, которые могут сбрасываться и устанавливаться пользователем: - archive file (архивный файл), - system file (системный файл), - hidden file (скрытый файл), - read-only file (файл только для чтения).
Ограничение системы FAT на размер логического диска составляет 2 Gb. При этом каждая запись FAT (на разделах объемом более 16 Mb) является 2-байтовым числом, следовательно, на логическом разделе может быть не более 65536 кластеров. Поэтому на дисках объемом более 1 Gb размер кластера в системе FAT составляет 32 K, т. е. "хвост" (slack) каждого файла занимает от 0 до 32 К, из чего следует, что каждая тысяча файлов поглощает в среднем 16 Mb дискового пространства. Файловую систему FAT, вследствие больших накладных расходов памяти, не рекомендуется использовать для томов, размер которых превышает 511 Mb.
38. HPFS.
HPFS - сокращенное название высокопроизводительной файловой системы (high performance file system), совместно разработанной в 1989 году корпорациями IBM и Microsoft.
Эта система была разработана, чтобы преодолеть некоторые недостатки FAT, к числу которых относятся:
ограничения, налагаемые на размер файлов и дискового пространства;
ограничение длины имени файла;
фрагментация файлов, приводящая к снижению быстродействия системы и износу оборудования;
непроизводительные затраты памяти, вызванные большими размерами кластеров;
подверженность потерям данных.
Переход на HPFS позволит сэкономить дисковое пространство. HPFS распределяет пространство, основываясь на физических 512-байтовых секторах, а не на кластерах, независимо от размера раздела.
Первые 16 секторов раздела HPFS составляют загрузочный блок. Эта область содержит метку диска и код начальной загрузки системы. Сектор 16, известный под названием суперблок, содержит много общей информации о файловой системе в целом: размер раздела, указатель на корневой каталог, счетчик элементов каталогов, номер версии HPFS, дату последней проверки и исправления раздела при помощи команды CHKDSK, а также дату последнего выполнения процедуры дефрагментации раздела. Он также содержит указатели на список испорченных блоков на диске, таблицу дефектных секторов и список доступных секторов.
Сектор 17 носит название SpareBlock? (запасной блок). Он содержит указатель на список секторов, которые можно использовать для "горячего" исправления ошибок, счетчик доступных секторов для "горячего" исправления ошибок, указатель на резерв свободных блоков, применяемых для управления деревьями каталогов, и информацию о языковых наборах символов. SpareBlock? также содержит так называемый "грязный" флаг. Этот новый флаг сообщает операционной системе о том, было ли завершение предыдущего сеанса работы нормальным, либо произошло в результате сбоя электропитания, либо файлы не были закрыты должным образом по какой-то другой причине.
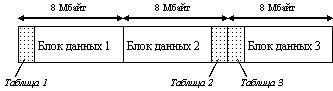
Во время форматирования раздела HPFS делит его на полосы по 8 Мбайт каждая. Каждая полоса - ее можно представить себе как виртуальный "мини-диск" - имеет отдельную таблицу объемом 2 Кбайт, в которой указывается, какие секторы полосы доступны, а какие заняты. Чтобы максимально увеличить протяженность непрерывного пространства для размещения файлов, таблицы попеременно располагаются в начале и в конце полос (рисунок 9.3). Этот метод позволяет файлам размером до 16 Мбайт (минус 4 Кбайта, отводимые для размещения таблицы) храниться в одной непрерывной области.
При форматировании диска в середине диска резервируется место для того, чтобы физические головки, считывающие данные, никогда не проходили более половины ширины диска.
Тот факт, что все пространство заранее распределено, также позволяет HPFS использовать специально оптимизированное программное обеспечение для более быстрой и эффективной работы с каталогами.
Скорость работы увеличивается также благодаря способу хранения элементов каталогов, используется не простой список, а В-дерево.
Операции записи в кэш осуществляются особым образом, который называется "ленивой" записью. Когда программа посылает команду записи, HPFS помещает данные в кэш и немедленно сообщает программе, что операция выполнена, и только потом в фоновом режиме данные перемещаются из оперативной памяти на устройство. Это исключает длительную задержку, сопровождающую действительную операцию записи данных на устройство ввода-вывода. Однако при этом существует риск нарушения целостности данных. Например, уже после того, как программа получила от ОС сообщение об успешном завершении операции ввода-вывода, при попытке записать данные из кэша на диск драйвер этого устройства может сообщить об ошибке обращения к диску. В таком случае весьма полезным является список блоков "горячего" исправления.
HPFS обладает повышенной отказоустойчивостью по сравнению с FAT. Если на диске с FAT оказалась стертой таблица распределения файлов, то скорее всего окажутся потерянными все данные, которые находятся вне корневого каталога. В системе HPFS вместо таблицы размещения файлов применяется битовый массив, который содержит флаг, помечающий используемые секторы. Если область битового массива будет разрушена, пользователь этого не заметит, даже если это случится во время работы системы.
39.труктура тома UFS.
(сюда ещё надо, про какую-то двойную или тройную косвенную адресацию и что файлы более самомостоятельные, чем в нтфс, что-то такое..)
Раздел диска, где размещается файловая система, делится на четыре области:
загрузочный блок;
суперблок (superblock) содержит самую общую информацию о файловой системе: размер файловой системы, размер области индексных дескрипторов, число индексных дескрипторов, список свободных блоков и список свободных индексных дескрипторов, а также другую административную информацию;
область индексных дескрипторов (inode list), порядок расположения индексных дескрипторов в которой соответствует их номерам;
область данных, в которой расположены как обычные файлы, так и файлы-каталоги, в том числе и корневой каталог; специальные файлы представлены в файловой системе только записями в соответствующих каталогах и индексными дескрипторами специального формата, но места в области данных не занимают.
Физическая организация файловой системы ufs
Суперблок является резервной копией основной первой копии суперблока. При повреждении основной копии суперблока может быть использована резервная копия суперблока. Области же блока группы цилиндров и индексных дескрипторов содержат индивидуальные для каждой последовательности значения. Блок группы цилиндров описывает количество индексных дескрипторов и блоков данных, расположенных на данной группе цилиндров диска. Такая группировка делается для ускорения доступа, чтобы просмотр индексных дескрипторов и данных файлов, описываемых этими дескрипторами, не приводил к слишком большим перемещениям головок диска.
В ufs имена файлов могут иметь длину до 255 символов (кодировка ASCII, по одному байту на символ).
40.NTFS: структура тома, типы файлов, каталоги.
NTFS представляет собой либо файл, либо часть файла. Основой структуры тома NTFS является главная таблица файлов (Master File Table, MFT), которая содержит по крайней мере одну запись для каждого файла тома, включая одну запись для самой себя. Каждая запись MFT имеет фиксированную длину, зависящую от объема диска, — 1, 2 или 4 Кбайт. Для большинства дисков, используемых сегодня, размер записи MFT равен 2 Кбайт, который мы далее будет считать размером записи по умолчанию.
Структура тома NTFS показана на рис. 7.19. Загрузочный блок тома NTFS располагается в начале тома, а его копия — в середине тома. Загрузочный блок содержит стандартный блок параметров BIOS, количество блоков в томе, а также начальный логический номер кластера основной копии MFT и зеркальную копию MFT.
Далее располагается первый отрезок MFT, содержащий 16 стандартных, создаваемых при форматировании записей о системных файлах NTFS. Назначение этих файлов описано в показанной ниже таблице MFT.
Номер записи Системный файл Имя файла Назначение файла

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
